You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Sheikh Yusuf Al-Qaradawi A Moderate Voice From TheDocument14 pagesSheikh Yusuf Al-Qaradawi A Moderate Voice From ThedmpmppNo ratings yet
- Maghrib Time Nairobi - Google SearchDocument1 pageMaghrib Time Nairobi - Google SearchHanan AliNo ratings yet
- Certification 5Document10 pagesCertification 5juliet.clementeNo ratings yet
- BCG X Meta India M&E 2023Document60 pagesBCG X Meta India M&E 2023Никита МузафаровNo ratings yet
- Anger Child of Fear: How Vulnerability Leads to AngerDocument2 pagesAnger Child of Fear: How Vulnerability Leads to AngerYeferson PalacioNo ratings yet
- Advanced Management Accounting: ConceptsDocument47 pagesAdvanced Management Accounting: ConceptsGEDDIGI BHASKARREDDYNo ratings yet
- BOI Interim Report 2019 PDFDocument122 pagesBOI Interim Report 2019 PDFAditya MukherjeeNo ratings yet
- ABC Pre School: (Please Refer Advertisement in This Section)Document5 pagesABC Pre School: (Please Refer Advertisement in This Section)hemacrcNo ratings yet
- The Philosophy of EmoDocument2 pagesThe Philosophy of EmoTed RichardsNo ratings yet
- ESL S9 W3 P14-15 Project Challenge Part 2Document27 pagesESL S9 W3 P14-15 Project Challenge Part 2Emma Catherine BurkeNo ratings yet
- DeKalb Pay Raise Summary July 6 2022Document8 pagesDeKalb Pay Raise Summary July 6 2022Janet and JamesNo ratings yet
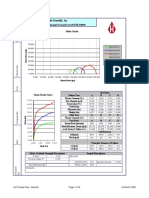
- Humboldt Scientific, Inc.: Normal Stress (Psi)Document9 pagesHumboldt Scientific, Inc.: Normal Stress (Psi)Dilson Loaiza CruzNo ratings yet
- Chapter 1: Functions and Relations: Precalculus, 1st EdDocument49 pagesChapter 1: Functions and Relations: Precalculus, 1st EdjakyNo ratings yet
- Go Int 6 Unit 2 Extension TestDocument4 pagesGo Int 6 Unit 2 Extension TestMiguel Anabalón TorresNo ratings yet
- Optimum Design of Cyclone Separator: SeparationsDocument5 pagesOptimum Design of Cyclone Separator: SeparationsJeyakumar RajaNo ratings yet
- Signals SyllabusDocument1 pageSignals SyllabusproNo ratings yet
- Oracle Induction - Introduction Foot Print and Instances For Perfect ExecutionDocument11 pagesOracle Induction - Introduction Foot Print and Instances For Perfect Executioneuge_prime2001No ratings yet
- Winning Market Through Market Oriented Strategic PlanningDocument25 pagesWinning Market Through Market Oriented Strategic PlanningKafi Mahmood NahinNo ratings yet
- QDEGNSWDocument2 pagesQDEGNSWSnehin PoddarNo ratings yet
- Essay Language TestingDocument6 pagesEssay Language TestingSabrina OktariniNo ratings yet
- NCM 107maternal FinalsDocument84 pagesNCM 107maternal FinalsFranz goNo ratings yet
- Evolution of Media and Social ImpactDocument24 pagesEvolution of Media and Social ImpactLeorick Miciano0% (1)
- Benchmark Evidence BasedDocument11 pagesBenchmark Evidence BasedPeterNo ratings yet
- Sermon 7 - Friendship and Fellowship of The Gospel - Part 6 - Philemon 7Document32 pagesSermon 7 - Friendship and Fellowship of The Gospel - Part 6 - Philemon 7Rob WilkersonNo ratings yet
- Lenti Title IX DismissedDocument31 pagesLenti Title IX DismissedDePauliaNo ratings yet
- Chromatography Viva Questions & Answers GuideDocument4 pagesChromatography Viva Questions & Answers GuidedhruvNo ratings yet
- Personal Narrative EssayDocument3 pagesPersonal Narrative Essayapi-510316103No ratings yet
- ProgDocument16 pagesProgRenon MadariNo ratings yet
- Assignment 1Document3 pagesAssignment 1Rabia Ahmad100% (1)
- Bible Study With The LDS MissionaryDocument53 pagesBible Study With The LDS MissionaryBobby E. LongNo ratings yet