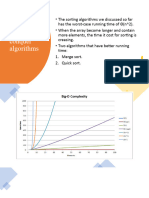
You might also like
- What Is The Fastest AlgorithmDocument4 pagesWhat Is The Fastest AlgorithmNaveed AhmedNo ratings yet
- Mudabbar Ul Islam SP18-BSE-118: Class AssignmentDocument5 pagesMudabbar Ul Islam SP18-BSE-118: Class AssignmentJawad NasirNo ratings yet
- Competitive Resources WEEK @2Document3 pagesCompetitive Resources WEEK @2Rohit rohitNo ratings yet
- ICS 46 Study GuideDocument1 pageICS 46 Study GuideJon NguyenNo ratings yet
- Term Paper: Data StructuresDocument6 pagesTerm Paper: Data StructuresInderpal SinghNo ratings yet
- UNIT - 1 Advanced Algorithm PDFDocument43 pagesUNIT - 1 Advanced Algorithm PDFbharat emandiNo ratings yet
- AlgorithmDocument7 pagesAlgorithmOporajitaNo ratings yet
- Bubble Sort AlgorithmDocument11 pagesBubble Sort AlgorithmRajonNo ratings yet
- Case StudyDocument6 pagesCase Studyzaid bin shafiNo ratings yet
- Ref: Https://Runestone - Academy/Runestone/Books/Published/Pythonds/Sortsearch/Theinsertionsort - HTMLDocument33 pagesRef: Https://Runestone - Academy/Runestone/Books/Published/Pythonds/Sortsearch/Theinsertionsort - HTMLGourab NandaNo ratings yet
- Dmytronoks Algorithms-Cs50Document1 pageDmytronoks Algorithms-Cs50Lord RigoNo ratings yet
- Data Structure SortingDocument14 pagesData Structure SortingDr. Mamta SinghNo ratings yet
- Bubble Sort Cocktail Sort: A Group Project On Fundamentals of Computing 1Document13 pagesBubble Sort Cocktail Sort: A Group Project On Fundamentals of Computing 1Mariebeth SenoNo ratings yet
- Week 03 SimpleSortingDocument45 pagesWeek 03 SimpleSortingbinvaongbavaiNo ratings yet
- Sorting AlgorithmDocument12 pagesSorting AlgorithmKrishnendu SahaNo ratings yet
- PDS Project ReportDocument14 pagesPDS Project ReportKetan KishoreNo ratings yet
- Introduction To C++Document5 pagesIntroduction To C++nartiishartiiNo ratings yet
- Lecture 5Document15 pagesLecture 5AbdurroufNo ratings yet
- Complexity Analysis of Searching and SortingDocument5 pagesComplexity Analysis of Searching and SortingKaushik RayNo ratings yet
- DS Reassessment of PLO 2Document4 pagesDS Reassessment of PLO 2Abbas JaveedNo ratings yet
- Sorting AlgorithmsDocument10 pagesSorting AlgorithmsExa SanNo ratings yet
- Sorting AlgorithmsDocument28 pagesSorting Algorithmsgogagoga2003.lmhNo ratings yet
- Lesson 1pDocument5 pagesLesson 1pMd. Shariful Islam 1530655042No ratings yet
- CSC3303 - Note 2Document2 pagesCSC3303 - Note 2Zam'Ah SirajoNo ratings yet
- Bubble Sort (With Code in Python-C++-Java-C)Document12 pagesBubble Sort (With Code in Python-C++-Java-C)Thee KullateeNo ratings yet
- Data Structures and AlgorithmsDocument115 pagesData Structures and Algorithmsjames oshomahNo ratings yet
- EditorialDocument12 pagesEditorialgelumntrezNo ratings yet
- Quick Sort Lomu ToDocument4 pagesQuick Sort Lomu ToJesus Moran PerezNo ratings yet
- Shellsort - WikipediaDocument5 pagesShellsort - WikipediaRaja Muhammad Shamayel UllahNo ratings yet
- Insertion Sort AlgorithmDocument14 pagesInsertion Sort AlgorithmVinston RajaNo ratings yet
- Chapter9 Part2Document16 pagesChapter9 Part2Artemis ZeusbornNo ratings yet
- Computer Network NotesDocument11 pagesComputer Network NotesAnkiTwilightedNo ratings yet
- Design &analysis of Algorithms Assignment: Uiet Department Information Technology Panjab University SSG-RCDocument11 pagesDesign &analysis of Algorithms Assignment: Uiet Department Information Technology Panjab University SSG-RCAk MishraNo ratings yet
- DS Reassessment of PLO 2Document5 pagesDS Reassessment of PLO 2Abbas JaveedNo ratings yet
- Data StructureDocument24 pagesData StructureKartik YadavNo ratings yet
- Sample of The Study Material Part of Chapter 6 Sorting AlgorithmsDocument10 pagesSample of The Study Material Part of Chapter 6 Sorting Algorithms1012804201No ratings yet
- DSA SPL NotesDocument5 pagesDSA SPL NotesDebanik DebnathNo ratings yet
- SortingDocument2 pagesSortingSandip DasNo ratings yet
- Amortized Analysis: 2.1 Unbounded ArrayDocument8 pagesAmortized Analysis: 2.1 Unbounded ArraySimon SylevesNo ratings yet
- CS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsDocument11 pagesCS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsJenny JackNo ratings yet
- 01FE20BEC295Document29 pages01FE20BEC295Anirudh GalagaliNo ratings yet
- Advanced SortingDocument22 pagesAdvanced SortingFiromsa DineNo ratings yet
- SortingDocument15 pagesSortingAtifNo ratings yet
- DCX RigidDocument16 pagesDCX RigidalexarrNo ratings yet
- Data Structures and Algorithms (COMP232)Document5 pagesData Structures and Algorithms (COMP232)SamehNo ratings yet
- Bubble SortDocument12 pagesBubble SortInformations & Entertainment Ahmad RazaNo ratings yet
- Bubble SortDocument7 pagesBubble SortAniket KhavanekarNo ratings yet
- LMNs - Algorithms - GeeksforGeeksDocument6 pagesLMNs - Algorithms - GeeksforGeeksAnchal RajpalNo ratings yet
- Sorting: 10.1 AimsDocument12 pagesSorting: 10.1 Aimsbenjamin dzingisoNo ratings yet
- IGNOU MCA MCS-031 Solved Assignment 2010Document13 pagesIGNOU MCA MCS-031 Solved Assignment 2010Gunjan SaxenaNo ratings yet
- Quick SortDocument1 pageQuick Sortprasadgr931No ratings yet
- Priority QueuesDocument25 pagesPriority Queuesvicrattlehead2013No ratings yet
- Elementary Sorting TechniquesDocument8 pagesElementary Sorting TechniquesUmmerNo ratings yet
- Practical 1:-Implementation and Time Analysis of Sortingalgorithms. Bubble Sort, Selection Sort, Insertion Sort, Merge Sort and QuicksortDocument20 pagesPractical 1:-Implementation and Time Analysis of Sortingalgorithms. Bubble Sort, Selection Sort, Insertion Sort, Merge Sort and QuicksortKaran MistryNo ratings yet
- Selection-Heap Sort Algo DetailDocument37 pagesSelection-Heap Sort Algo DetailMallinath KhondeNo ratings yet
- Review QuestionsDocument3 pagesReview Questionsunited_n72No ratings yet
- Data Structures: Linked ListDocument7 pagesData Structures: Linked ListMeenal Kataria PanjwaniNo ratings yet
- BST 4Document7 pagesBST 4Tanya VermaNo ratings yet
- BINARY SEARCH Piyush PDFDocument11 pagesBINARY SEARCH Piyush PDFAk MishraNo ratings yet
- Advantages andDocument2 pagesAdvantages andPrashant HolkarNo ratings yet
- Speech by Alex StepanovDocument4 pagesSpeech by Alex Stepanovadobulation100% (4)
- 2011 Full Page Calendar - TomKat StudioDocument12 pages2011 Full Page Calendar - TomKat StudioThe TomKat StudioNo ratings yet
- Speech by Alex StepanovDocument4 pagesSpeech by Alex Stepanovadobulation100% (4)
- Speech by Alex StepanovDocument4 pagesSpeech by Alex Stepanovadobulation100% (4)
- Sorting Algorithm Comparison ChartDocument18 pagesSorting Algorithm Comparison ChartPrashant HolkarNo ratings yet
- FinalDocument6 pagesFinalswapna jrNo ratings yet
- nfsv4 IbmDocument426 pagesnfsv4 IbmSenthil KumaranNo ratings yet
- What Is Computer CrimeDocument13 pagesWhat Is Computer CrimecrimeloveNo ratings yet
- Iot Based Cattle Health Monitoring System IJERTCONV5IS01041Document4 pagesIot Based Cattle Health Monitoring System IJERTCONV5IS01041DilipNo ratings yet
- SCADAPack 330E 333E 334E 337E E Series DatasheetDocument6 pagesSCADAPack 330E 333E 334E 337E E Series DatasheetAqua Technology GroupNo ratings yet
- Create Sell Digital ProductsDocument2 pagesCreate Sell Digital ProductsAli RachidNo ratings yet
- Mba 544Document2 pagesMba 544api-3782519No ratings yet
- DCXD 119 A 332Document8 pagesDCXD 119 A 332Well WisherNo ratings yet
- Restoring DivisionDocument5 pagesRestoring DivisionAsha DurafeNo ratings yet
- Connect JSP With MysqlDocument2 pagesConnect JSP With MysqlIresh AllagiNo ratings yet
- From Pseudo Code To Program CodeDocument24 pagesFrom Pseudo Code To Program Codeمحمد يسر سواسNo ratings yet
- SDK TC-Python Quick Install Guide PDFDocument7 pagesSDK TC-Python Quick Install Guide PDFInaamNo ratings yet
- TCP Ip MCQDocument28 pagesTCP Ip MCQSonale Taneja TandoanNo ratings yet
- Electronics ResearchDocument3 pagesElectronics ResearchiamalminkoNo ratings yet
- Mockito Vs EasyMock Mockito - Mockito WikiDocument1 pageMockito Vs EasyMock Mockito - Mockito Wikiგენო მუმლაძეNo ratings yet
- Ouriginal Users GuideDocument38 pagesOuriginal Users GuideaeroacademicNo ratings yet
- Empowerment Technologies - Lesson 1Document4 pagesEmpowerment Technologies - Lesson 1Bridget Anne BenitezNo ratings yet
- How To Create APIDocument23 pagesHow To Create APIAbubakar HiyangNo ratings yet
- Current LogDocument4 pagesCurrent Logjhonnier.cl2010No ratings yet
- Sanstop25-01 12 2021-07 46-PMDocument112 pagesSanstop25-01 12 2021-07 46-PMMayur PawarNo ratings yet
- 1 s2.0 S0360835221000784 MainDocument17 pages1 s2.0 S0360835221000784 MainHadi Ashraf RajaNo ratings yet
- Project Synopsis SampleDocument7 pagesProject Synopsis SampleDhwani PatelNo ratings yet
- Adobe Framemaker 2015 HelpDocument990 pagesAdobe Framemaker 2015 Helppulkit nagpal100% (1)
- 23Document19 pages23Limon ÁcidoNo ratings yet
- LaTex MCQDocument89 pagesLaTex MCQobakkandoNo ratings yet
- 26 Owais KCS552Document86 pages26 Owais KCS552Vivo Ipl 2019No ratings yet
- PointerDocument26 pagesPointerpravin2mNo ratings yet
- Chapter 1 Intro To GUI - Part 2Document55 pagesChapter 1 Intro To GUI - Part 2Risa ChanNo ratings yet
- Windows XP Tips 234 Part Part 2Document48 pagesWindows XP Tips 234 Part Part 2zamil hossainNo ratings yet
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Coders at Work: Reflections on the Craft of ProgrammingFrom EverandCoders at Work: Reflections on the Craft of ProgrammingRating: 4 out of 5 stars4/5 (151)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Microsoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.From EverandMicrosoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.Rating: 5 out of 5 stars5/5 (2)
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- Understanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerFrom EverandUnderstanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerRating: 4.5 out of 5 stars4.5/5 (44)
- Once Upon an Algorithm: How Stories Explain ComputingFrom EverandOnce Upon an Algorithm: How Stories Explain ComputingRating: 4 out of 5 stars4/5 (43)
- GAMEDEV: 10 Steps to Making Your First Game SuccessfulFrom EverandGAMEDEV: 10 Steps to Making Your First Game SuccessfulRating: 4.5 out of 5 stars4.5/5 (12)
- What Algorithms Want: Imagination in the Age of ComputingFrom EverandWhat Algorithms Want: Imagination in the Age of ComputingRating: 3.5 out of 5 stars3.5/5 (41)
- Python: For Beginners A Crash Course Guide To Learn Python in 1 WeekFrom EverandPython: For Beginners A Crash Course Guide To Learn Python in 1 WeekRating: 3.5 out of 5 stars3.5/5 (23)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- Software Engineering at Google: Lessons Learned from Programming Over TimeFrom EverandSoftware Engineering at Google: Lessons Learned from Programming Over TimeRating: 4 out of 5 stars4/5 (11)
- App Empire: Make Money, Have a Life, and Let Technology Work for YouFrom EverandApp Empire: Make Money, Have a Life, and Let Technology Work for YouRating: 4 out of 5 stars4/5 (21)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Django Unleashed: Building Web Applications with Python's FrameworkFrom EverandDjango Unleashed: Building Web Applications with Python's FrameworkNo ratings yet
- Microsoft OneNote Guide to Success: Learn In A Guided Way How To Take Digital Notes To Optimize Your Understanding, Tasks, And Projects, Surprising Your Colleagues And ClientsFrom EverandMicrosoft OneNote Guide to Success: Learn In A Guided Way How To Take Digital Notes To Optimize Your Understanding, Tasks, And Projects, Surprising Your Colleagues And ClientsRating: 5 out of 5 stars5/5 (2)