You might also like
- Promoting Change Through Paradoxical Therapy - Gerald Weeks PDFDocument575 pagesPromoting Change Through Paradoxical Therapy - Gerald Weeks PDFmarina_apsi100% (2)
- ProblemSheets2015 SolutionsDocument202 pagesProblemSheets2015 Solutionssumit_raisedNo ratings yet
- A320Document41 pagesA320Varun Kapoor75% (4)
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYFrom EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYNo ratings yet
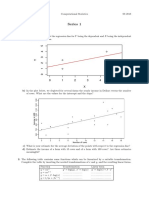
- Multiple Linear RegressionDocument14 pagesMultiple Linear RegressionNamdev100% (1)
- Manual For Adjustment Inventory For: School Students (AISS)Document6 pagesManual For Adjustment Inventory For: School Students (AISS)Priyansh Patel67% (3)
- Amateur Photographer - May 28, 2016Document84 pagesAmateur Photographer - May 28, 2016Lee100% (1)
- Simple RegressionDocument50 pagesSimple Regressioniga gemelia100% (1)
- Method Statement For Installation of Access ScafoldingDocument9 pagesMethod Statement For Installation of Access Scafoldingbureau servicesNo ratings yet
- CQF Module 2 Examination: InstructionsDocument3 pagesCQF Module 2 Examination: InstructionsPrathameshSagareNo ratings yet
- Sesi 6 Statistical Quality ControlDocument46 pagesSesi 6 Statistical Quality ControlMerina Merina100% (1)
- Trefethen BauDocument29 pagesTrefethen BauHari Haran100% (1)
- CH 10Document89 pagesCH 10Mhmd AlKhreisat100% (1)
- Regression An OvaDocument24 pagesRegression An Ovaatul_sanchetiNo ratings yet
- Engineering Prob & Stat Lecture Notes 7Document6 pagesEngineering Prob & Stat Lecture Notes 7EICQ/00154/2020 SAMUEL MWANGI RUKWARONo ratings yet
- Memo Pas206b Wr3 - A 2022Document8 pagesMemo Pas206b Wr3 - A 2022José ChombossiNo ratings yet
- Mfin514 3 1Document18 pagesMfin514 3 1judbavNo ratings yet
- Metanalisis Con RDocument8 pagesMetanalisis Con RHéctor W Moreno QNo ratings yet
- Sample Applied Statistics and Probability For EngineersDocument7 pagesSample Applied Statistics and Probability For EngineersALBERT DAODANo ratings yet
- Series 1Document2 pagesSeries 1Sangwoo KimNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- EMT Untuk StatistikaDocument50 pagesEMT Untuk Statistikaibrahim raflie wijayaNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- HW4 Solutions: Problem 6.2Document8 pagesHW4 Solutions: Problem 6.2Souleymane CoulibalyNo ratings yet
- Homework02 Withsolutions 1 PDFDocument5 pagesHomework02 Withsolutions 1 PDFVarmenUchihaNo ratings yet
- PHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckDocument20 pagesPHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckKarim BekhtiarNo ratings yet
- Holect 18Document6 pagesHolect 18IrenataNo ratings yet
- Factorial Experiments R CodesDocument7 pagesFactorial Experiments R Codes48Raut AparnaNo ratings yet
- Sturm Liou Ville 3Document6 pagesSturm Liou Ville 3imran5705074No ratings yet
- Regression 2Document25 pagesRegression 2Henrique CalhauNo ratings yet
- Q (X) Q (X) : 8.4.1 Uniform Scalar QuantizationDocument22 pagesQ (X) Q (X) : 8.4.1 Uniform Scalar Quantizationroussisd74944No ratings yet
- Problem Set 7 Solution Numerical MethodsDocument12 pagesProblem Set 7 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- HW1 SolDocument7 pagesHW1 SolprakshiNo ratings yet
- Important Instructions To The Examiners:: Model AnswerDocument26 pagesImportant Instructions To The Examiners:: Model AnswerPrashant KasarNo ratings yet
- Financial AccoutingDocument7 pagesFinancial Accoutingtinale1603No ratings yet
- Heavy-Tailed Innovations in The R Package Stochvol: PrefaceDocument8 pagesHeavy-Tailed Innovations in The R Package Stochvol: PrefaceanirudhjayNo ratings yet
- Handout 41100 PolynomialRegressionDocument6 pagesHandout 41100 PolynomialRegressionPrajol JoshiNo ratings yet
- WINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionDocument39 pagesWINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionasNo ratings yet
- Inferences On Two Populations Sample ProblemsDocument10 pagesInferences On Two Populations Sample Problemsalexander bariquitNo ratings yet
- Optimization: Machine Learning Course - CS-433Document23 pagesOptimization: Machine Learning Course - CS-433Diego Iriarte SainzNo ratings yet
- Toom Cook Polynomials BodratoDocument15 pagesToom Cook Polynomials BodratoJuan Pastor RamosNo ratings yet
- Final Predictive Vaibhav 2020Document101 pagesFinal Predictive Vaibhav 2020sristi agrawalNo ratings yet
- Monte Carlo BasicsDocument23 pagesMonte Carlo BasicsIon IvanNo ratings yet
- BZAN 535: Linear RegressionDocument11 pagesBZAN 535: Linear RegressionMotasimaNo ratings yet
- Wma14-01-Rms-20230817 2Document23 pagesWma14-01-Rms-20230817 2Rahyan AshrafNo ratings yet
- Me 343 - Control Systems - Fall 2008 Second Exam - October 29, 2008Document7 pagesMe 343 - Control Systems - Fall 2008 Second Exam - October 29, 2008Sérgio SilvaNo ratings yet
- Sol10 PDFDocument4 pagesSol10 PDFMichael ARKNo ratings yet
- The Notion of StabilityDocument4 pagesThe Notion of StabilityDiana OctavianiNo ratings yet
- WINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal DistributionDocument38 pagesWINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal Distributionjeevan saiNo ratings yet
- Test of Difference and FriedmanDocument11 pagesTest of Difference and FriedmanAngel PascuhinNo ratings yet
- BSA Test of Difference May 10 2023Document9 pagesBSA Test of Difference May 10 2023Angel PascuhinNo ratings yet
- G G G G G G' G G G' G': Steps For Hands-On Reliability Analysis Involving Correlated NormalsDocument8 pagesG G G G G G' G G G' G': Steps For Hands-On Reliability Analysis Involving Correlated NormalsAshraf KhanNo ratings yet
- Ejercicio 2.3Document4 pagesEjercicio 2.3Duvan BayonaNo ratings yet
- Lesson 3Document5 pagesLesson 3alayca cabatanaNo ratings yet
- Week 7 LectureDocument54 pagesWeek 7 LectureHANJING QUANNo ratings yet
- Assignment 1Document7 pagesAssignment 1suna leeNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument21 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAbhilash RudraNo ratings yet
- Aljabar Linier - MatriksDocument41 pagesAljabar Linier - MatriksgibthaNo ratings yet
- Chapter Four: Curve FittingDocument58 pagesChapter Four: Curve FittingGirmole WorkuNo ratings yet
- Quasi Explicit Calibration of Gatheral SVI ModelDocument15 pagesQuasi Explicit Calibration of Gatheral SVI ModelRayan RayanNo ratings yet
- Dynamic ResponseDocument4 pagesDynamic ResponseAlex JavierNo ratings yet
- Notes On Modern Control: Carlos Xavier Rosero ChandiDocument4 pagesNotes On Modern Control: Carlos Xavier Rosero ChandiAlex JavierNo ratings yet
- Chap 6Document23 pagesChap 6studentgprec2653No ratings yet
- MIT18 S096F13 Pset6Document5 pagesMIT18 S096F13 Pset6TheoNo ratings yet
- Discussion QuestionsDocument9 pagesDiscussion QuestionsyourhunkieNo ratings yet
- Sap WM Organization StructureDocument7 pagesSap WM Organization StructureNarendra KumarNo ratings yet
- Probset 1 PDFDocument2 pagesProbset 1 PDFDharavathu AnudeepnayakNo ratings yet
- Manual ROHDE - SCHWARZ - EB200Document232 pagesManual ROHDE - SCHWARZ - EB200Leonardo Arroyave100% (1)
- Pak Emergency Sukkur PDFDocument58 pagesPak Emergency Sukkur PDFNaeemullahNo ratings yet
- Literature Review Situasional LeadershipDocument7 pagesLiterature Review Situasional LeadershipNor Fairus Mp0% (1)
- Versi English - Modul Praktikum Kimia Analitik 2018Document50 pagesVersi English - Modul Praktikum Kimia Analitik 2018Armiati AbdullahNo ratings yet
- MMZG 533Document8 pagesMMZG 533Prakash Kumar SenNo ratings yet
- Accident and Incident Analysis Based On The AccideDocument12 pagesAccident and Incident Analysis Based On The AccideAnees Balqis YunezzafrinNo ratings yet
- Expository Essay Thesis Statement ExamplesDocument4 pagesExpository Essay Thesis Statement Examplesl0d1l1puzos3100% (2)
- Bihar SI Mains Syllabus-024b287317594Document3 pagesBihar SI Mains Syllabus-024b287317594Aryan KhanNo ratings yet
- Research Problem FormatDocument1 pageResearch Problem FormatMarkWeberNo ratings yet
- EpdmDocument2 pagesEpdmhappale2002No ratings yet
- Form IR Civil Proyek PLTMG MERAUKE-20 MW (Contoh)Document94 pagesForm IR Civil Proyek PLTMG MERAUKE-20 MW (Contoh)Ramdan Pramedis SetyaNo ratings yet
- Grade 8 Term 3 Project 2021Document2 pagesGrade 8 Term 3 Project 2021Londiwe PrincessNo ratings yet
- Oleh: Fatma Widyastuti, S.PD., M.Ed. Widyaiswara Ahli Madya Balai Diklat KeagamaansemarangDocument11 pagesOleh: Fatma Widyastuti, S.PD., M.Ed. Widyaiswara Ahli Madya Balai Diklat KeagamaansemarangAkid AthayaNo ratings yet
- Scholarship Application FormDocument4 pagesScholarship Application FormAnonymous fY1HXgJRkzNo ratings yet
- Sheroune 2 1 1.aflDocument11 pagesSheroune 2 1 1.afludhaya kumarNo ratings yet
- Priyajit's Resume NewDocument3 pagesPriyajit's Resume Newamrit mohantyNo ratings yet
- Choosing A SolverDocument12 pagesChoosing A SolversnthejNo ratings yet
- Commercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution ManualDocument8 pagesCommercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution Manualmatthew100% (22)
- 9 tribologyofGO-UHWMPEDocument10 pages9 tribologyofGO-UHWMPEA P BNo ratings yet
- Educational PhilosophyDocument2 pagesEducational Philosophyapi-393451535No ratings yet
- தசம பின்னம் ஆண்டு 4Document22 pagesதசம பின்னம் ஆண்டு 4Jessica BarnesNo ratings yet
- Statement of Teaching Interests-ExampleDocument3 pagesStatement of Teaching Interests-ExampleNedelcuGeorgeNo ratings yet