You might also like
- Chow TestDocument23 pagesChow TestHector Garcia0% (1)
- Chow TestDocument23 pagesChow TestYaronBabaNo ratings yet
- DOE Course Part 14Document21 pagesDOE Course Part 14vsuarezf2732No ratings yet
- Design of Engineering Experiments Part 3 - The Blocking Principle The Blocking PrincipleDocument5 pagesDesign of Engineering Experiments Part 3 - The Blocking Principle The Blocking PrincipleEnio BrogniNo ratings yet
- Blocking Principle & Latin Square Designs in Engineering ExperimentsDocument20 pagesBlocking Principle & Latin Square Designs in Engineering ExperimentsRic GiNo ratings yet
- Applications of Microbiolgical Data: Tim Sandle Microbiology Information ResourceDocument50 pagesApplications of Microbiolgical Data: Tim Sandle Microbiology Information ResourceNatalija Atanasova-PancevskaNo ratings yet
- 44 3 Expmntl DesgnDocument18 pages44 3 Expmntl Desgntarek moahmoud khalifaNo ratings yet
- Functional Form and Dynamic Models: FRT, Lags, Koyck TransformationDocument27 pagesFunctional Form and Dynamic Models: FRT, Lags, Koyck TransformationmazamniaziNo ratings yet
- 2003 StabilityAnalysisDocument58 pages2003 StabilityAnalysisSettuNo ratings yet
- RatchetingDocument20 pagesRatchetingAllan Marbaniang100% (1)
- Panel Data Models: Dynamic Panels and Unit RootsDocument20 pagesPanel Data Models: Dynamic Panels and Unit RootsJeremiahOmwoyoNo ratings yet
- Vibration PDFDocument10 pagesVibration PDFArjun Chitradurga RamachandraRaoNo ratings yet
- Chow TestDocument2 pagesChow TestWhitney LeungNo ratings yet
- IMPTDocument59 pagesIMPTharish srinivasNo ratings yet
- Diagnostic Tests2Document17 pagesDiagnostic Tests2LucNo ratings yet
- FRM Part 1 Changes LO WiseDocument7 pagesFRM Part 1 Changes LO Wiseanirudh917No ratings yet
- Concrete Modeling GuideDocument4 pagesConcrete Modeling GuideJae Huan YooNo ratings yet
- Construction: Prefabricated Steel Bridge Systems: Final ReportDocument14 pagesConstruction: Prefabricated Steel Bridge Systems: Final ReportNicholas FeatherstonNo ratings yet
- Joe Carvalho Position PaperDocument5 pagesJoe Carvalho Position Paperjaguilarn1960No ratings yet
- HFS206 GBA Jul22Document5 pagesHFS206 GBA Jul22Salihin HasanNo ratings yet
- Guideline For FE Analyses of Concrete Dams: ICOLD 2017 PragueDocument17 pagesGuideline For FE Analyses of Concrete Dams: ICOLD 2017 PragueMathy TuringNo ratings yet
- Predictive Modeling Questions and AnswersDocument32 pagesPredictive Modeling Questions and AnswersAsim Mazin100% (1)
- Fatigue Life For ASME VII-DIV2Document23 pagesFatigue Life For ASME VII-DIV2Muhammad Abd El KawyNo ratings yet
- 102 PART 1 | INTRO TO OPERATIONS MANAGEMENTDocument1 page102 PART 1 | INTRO TO OPERATIONS MANAGEMENTomer asgharNo ratings yet
- PSY417 Week02Document38 pagesPSY417 Week02Ellisha McCNo ratings yet
- Bahan Ansys DikaDocument152 pagesBahan Ansys DikaRandika SudarmaNo ratings yet
- PSY - 2060 - 2022H1 - Session 01 2022-01-19 02 - 39 - 01Document24 pagesPSY - 2060 - 2022H1 - Session 01 2022-01-19 02 - 39 - 01Kam ToNo ratings yet
- TQM-I 06 Variable Control ChartDocument73 pagesTQM-I 06 Variable Control ChartAjith NBNo ratings yet
- Ce (Pe) 602BDocument10 pagesCe (Pe) 602BArghya MondalNo ratings yet
- Estimation Procedures for Time Series ModelsDocument51 pagesEstimation Procedures for Time Series ModelsNurudeen Bamidele Faniyi (fbn)No ratings yet
- Classical Linear Regression Model Assumptions and DiagnosticsDocument71 pagesClassical Linear Regression Model Assumptions and DiagnosticsabdulraufhccNo ratings yet
- Rolling Contact Fatigue Life Testing Methods Using Weibull Distribution CalculationsDocument8 pagesRolling Contact Fatigue Life Testing Methods Using Weibull Distribution CalculationsJojee MarieNo ratings yet
- Dynamic Panel Data ModelsDocument20 pagesDynamic Panel Data Modelszaheer khanNo ratings yet
- Classical Linear Regression Model Assumptions and DiagnosticsDocument66 pagesClassical Linear Regression Model Assumptions and DiagnosticsOguzNo ratings yet
- Structural Analysis-II Semester V NotesDocument151 pagesStructural Analysis-II Semester V NotesKanade's Engineering Classes PuneNo ratings yet
- Class 5 Mult Reg Diag 2Document38 pagesClass 5 Mult Reg Diag 2Neway AlemNo ratings yet
- Modelling Long-Run Relationship in Finance: Introductory Econometrics For Finance' © Chris Brooks 2013 1Document18 pagesModelling Long-Run Relationship in Finance: Introductory Econometrics For Finance' © Chris Brooks 2013 1Nouf ANo ratings yet
- Department of Automobile & Mechanical Engineering: System Design and SimulationDocument12 pagesDepartment of Automobile & Mechanical Engineering: System Design and Simulationanup chauhanNo ratings yet
- Force Methods - Consistent DeformationDocument41 pagesForce Methods - Consistent DeformationShakira100% (4)
- CE3155 Structural Analysis: ConsultationDocument3 pagesCE3155 Structural Analysis: Consultationhuiting loyNo ratings yet
- Unreplicated 2 Factorial Designs: One Observation Single ReplicateDocument33 pagesUnreplicated 2 Factorial Designs: One Observation Single ReplicateJosé Carlos Chan AriasNo ratings yet
- SE 463 Software Testing and Quality Assurance: Chapter 2: Testing Throughout The SW Life CycleDocument18 pagesSE 463 Software Testing and Quality Assurance: Chapter 2: Testing Throughout The SW Life CycleSam SamNo ratings yet
- Practical Guide To Sequential Design - Webinar SlidesDocument28 pagesPractical Guide To Sequential Design - Webinar Slidestila12negaNo ratings yet
- ARIMA Modelling and Forecasting Techniques ExplainedDocument30 pagesARIMA Modelling and Forecasting Techniques ExplainedRaymond SmithNo ratings yet
- Unit 7 - Forecasting and Time Series - Advanced TopicsDocument54 pagesUnit 7 - Forecasting and Time Series - Advanced TopicsRajdeep SinghNo ratings yet
- Module 07: Solution: Release 2020 R1Document79 pagesModule 07: Solution: Release 2020 R1Rishi SharmaNo ratings yet
- Module 3.3Document26 pagesModule 3.3MOHAMMED SHEHZAD K SALIMNo ratings yet
- BRM - L4,5 - Linear RegressionDocument113 pagesBRM - L4,5 - Linear RegressionNusratJahanHeabaNo ratings yet
- EXP 3 Coefficient of Friction FinalDocument5 pagesEXP 3 Coefficient of Friction FinalCef LlameloNo ratings yet
- AutocorrelationDocument25 pagesAutocorrelationAnonymous xeirMaAHNo ratings yet
- Time Series AnalysisDocument36 pagesTime Series AnalysisVinayakaNo ratings yet
- Lecture 101Document43 pagesLecture 101Jean ReneNo ratings yet
- ANSYS CFX Solving I PDFDocument128 pagesANSYS CFX Solving I PDFAshish Prasannan KalayilNo ratings yet
- Experiment BlockingDocument17 pagesExperiment Blockingstatistics on tips 2020No ratings yet
- Lecture8 Model Assessment StudentsDocument37 pagesLecture8 Model Assessment Students翁江靖No ratings yet
- LAS-DLS-421 Module OutlineDocument8 pagesLAS-DLS-421 Module OutlineElisha ManishimweNo ratings yet
- Ultimate Strength AnalysisDocument59 pagesUltimate Strength AnalysisPedroNo ratings yet
- 8 CSC446 546 InputModelingDocument44 pages8 CSC446 546 InputModelingCh MaarijNo ratings yet
- CH 04Document30 pagesCH 04LusyifaFebioza100% (1)
- The Partial Regularity Theory of Caffarelli, Kohn, and Nirenberg and its SharpnessFrom EverandThe Partial Regularity Theory of Caffarelli, Kohn, and Nirenberg and its SharpnessNo ratings yet
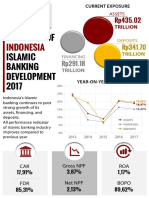
- Indonesia Islamic Banking Snapshot 2017 (V3)Document8 pagesIndonesia Islamic Banking Snapshot 2017 (V3)Haniyah NadhiraNo ratings yet
- Basic Resignation Letter TemplateDocument1 pageBasic Resignation Letter TemplateHaniyah NadhiraNo ratings yet
- Thom21e Ch09 FinalDocument49 pagesThom21e Ch09 Finalagungwibowo89No ratings yet
- ISlide Blue Graduation Thesis Defense Presentation 06Document21 pagesISlide Blue Graduation Thesis Defense Presentation 06Haniyah NadhiraNo ratings yet
- SPS Des2015Document328 pagesSPS Des2015Haniyah NadhiraNo ratings yet
- ISlide Master Thesis Defense PowerPoint Template 07Document21 pagesISlide Master Thesis Defense PowerPoint Template 07Haniyah Nadhira100% (2)
- Managing People in Global Markets-The Asia Pacific PerspectiveDocument4 pagesManaging People in Global Markets-The Asia Pacific PerspectiveHaniyah NadhiraNo ratings yet
- ISlide Blue Graduation Thesis Defense Presentation 06Document21 pagesISlide Blue Graduation Thesis Defense Presentation 06Haniyah NadhiraNo ratings yet
- City Template 16x9Document5 pagesCity Template 16x9Haniyah NadhiraNo ratings yet
- Chap 12Document34 pagesChap 12Haniyah NadhiraNo ratings yet
- The Bidding War For Harbin Brewery GroupDocument10 pagesThe Bidding War For Harbin Brewery GroupHaniyah NadhiraNo ratings yet
- Insights Template Indonesian Bank Improving TractionDocument29 pagesInsights Template Indonesian Bank Improving TractionHaniyah NadhiraNo ratings yet
- MBF14e Chap05 FX MarketsDocument20 pagesMBF14e Chap05 FX MarketsHaniyah Nadhira100% (1)
- MBF14e Chap05 FX MarketsDocument20 pagesMBF14e Chap05 FX MarketsHaniyah Nadhira100% (1)
- Project Name: PNP Project Fact SheetDocument3 pagesProject Name: PNP Project Fact SheetelvinNo ratings yet
- Guest1987 PDFDocument19 pagesGuest1987 PDFPricopi VictorNo ratings yet
- ACHS EQuIP6 Book 1 Final 2016Document210 pagesACHS EQuIP6 Book 1 Final 2016Intan PermataNo ratings yet
- EETD Course Plan (Probability and Statistics)Document6 pagesEETD Course Plan (Probability and Statistics)Raja ahmerNo ratings yet
- Writing A Position PaperDocument2 pagesWriting A Position Paperphilip100% (1)
- Most Interesting Preliminary Research Topic: Preparing, Conceptualizing and Focusing A Research PlanDocument9 pagesMost Interesting Preliminary Research Topic: Preparing, Conceptualizing and Focusing A Research PlanRey Christian BolanoNo ratings yet
- Retail Service Quality at Kannan Department StoresDocument5 pagesRetail Service Quality at Kannan Department StoresvidhyathiyagarajanNo ratings yet
- NBS Learning Scenario Template For MOOC (Maria Mantelou)Document7 pagesNBS Learning Scenario Template For MOOC (Maria Mantelou)Kamil Paşa İlkokuluNo ratings yet
- Grade 9 English Chamber Theatre PresentationDocument4 pagesGrade 9 English Chamber Theatre PresentationMisheru Mitchi100% (1)
- Daily Lesson Plan FallaciesDocument5 pagesDaily Lesson Plan Fallaciesapi-269465073No ratings yet
- Dorothea Orem Research PaperDocument8 pagesDorothea Orem Research Paperefdvje8d100% (3)
- Real Estate Property DevelopmentDocument8 pagesReal Estate Property Developmentapi-372989613No ratings yet
- SCI Arc Presents The Duck and The Document Curated by Sylvia LavinDocument2 pagesSCI Arc Presents The Duck and The Document Curated by Sylvia LavinEnrique RamirezNo ratings yet
- Wong 2000Document115 pagesWong 2000Alexandre Maceno de LimaNo ratings yet
- Effects of Coaching Head Nurses on Discharge Planning Documentation QualityDocument8 pagesEffects of Coaching Head Nurses on Discharge Planning Documentation QualitydwiajaNo ratings yet
- National Initiative For Technical Teacher Training (NITTT) : Mentor Guideline ManualDocument81 pagesNational Initiative For Technical Teacher Training (NITTT) : Mentor Guideline ManualJosephine Torres100% (2)
- Effects of The Breakup On Children, School Performance and Peer RelationsDocument13 pagesEffects of The Breakup On Children, School Performance and Peer Relationszubiii aslamNo ratings yet
- Wanke - 2012 - Determinants of Scale Efficiency in The Brazilian 3PL Industry A 10-Year AnalysisDocument17 pagesWanke - 2012 - Determinants of Scale Efficiency in The Brazilian 3PL Industry A 10-Year AnalysisAntonio Carlos RodriguesNo ratings yet
- Impact of Parental Control on Children's Tech UseDocument2 pagesImpact of Parental Control on Children's Tech UseDR PrasadNo ratings yet
- GE PC Course SyllabusDocument9 pagesGE PC Course SyllabusAine CebedoNo ratings yet
- Reliance Jio 4G Market Potential StudyDocument28 pagesReliance Jio 4G Market Potential StudyAarchaNo ratings yet
- Johns Hopkins Sais ThesisDocument5 pagesJohns Hopkins Sais Thesisbrittanyeasonlowell100% (2)
- Appetite: Migle Baceviciene, Rasa JankauskieneDocument9 pagesAppetite: Migle Baceviciene, Rasa JankauskieneMaria Chambi GutierrezNo ratings yet
- UNICEF Infant and Young Child Feeding ProgrammeDocument76 pagesUNICEF Infant and Young Child Feeding ProgrammethousanddaysNo ratings yet
- Product DevelopmentDocument5 pagesProduct DevelopmentAyieNo ratings yet
- Document PDFDocument10 pagesDocument PDFEmily AndreeaNo ratings yet
- Regression Discontinuity Design GuideDocument21 pagesRegression Discontinuity Design GuideyanfikNo ratings yet
- CFA PilesDocument293 pagesCFA Pilesfludor100% (1)
- Heat and Temperature ChangesDocument4 pagesHeat and Temperature ChangesErna RisfaulaNo ratings yet
- ProjectDocument31 pagesProjectSanjeev_Ranjan_5618No ratings yet