You might also like
- A Case For 16 Bit ArchitecturesDocument7 pagesA Case For 16 Bit Architecturesalvarito2009No ratings yet
- Introduction to Reliable and Secure Distributed ProgrammingFrom EverandIntroduction to Reliable and Secure Distributed ProgrammingNo ratings yet
- The Influence of Linear-Time Methodologies On TheoryDocument6 pagesThe Influence of Linear-Time Methodologies On TheoryAdamo GhirardelliNo ratings yet
- PUNK Visualization of Object-Oriented LanguagesDocument4 pagesPUNK Visualization of Object-Oriented LanguagesJ Christian OdehnalNo ratings yet
- Scimakelatex 78982 Asdf Asdfa Sdfasdasdff AsdfasdfDocument8 pagesScimakelatex 78982 Asdf Asdfa Sdfasdasdff Asdfasdfefg243No ratings yet
- Courseware Considered HarmfulDocument8 pagesCourseware Considered Harmfulvasa00No ratings yet
- Glide: Virtual, Adaptive Methodologies: Dennison Duarte, Rikiro Otsu and Mark TelemenDocument10 pagesGlide: Virtual, Adaptive Methodologies: Dennison Duarte, Rikiro Otsu and Mark TelemenJoshua MelgarejoNo ratings yet
- Contrasting Smps and Ipv7Document6 pagesContrasting Smps and Ipv7Adamo GhirardelliNo ratings yet
- Simulating I/O Automata and 802.11B: Will IsmadDocument6 pagesSimulating I/O Automata and 802.11B: Will IsmadBenoit JottreauNo ratings yet
- Visualizing Rasterization and E-Commerce: 2.1 RaidDocument5 pagesVisualizing Rasterization and E-Commerce: 2.1 RaiddagospamNo ratings yet
- Truh-VormenTowards The Study of SmalltalkDocument5 pagesTruh-VormenTowards The Study of Smalltalkalvarito2009No ratings yet
- Manlyake: Mobile Information: Thommas SpilsenDocument6 pagesManlyake: Mobile Information: Thommas SpilsenAnonymous vwzQ3bY5T4No ratings yet
- Gre: Interposable, Omniscient InformationDocument9 pagesGre: Interposable, Omniscient InformationAdamo GhirardelliNo ratings yet
- An Understanding of SCSI Disks: BstractDocument4 pagesAn Understanding of SCSI Disks: BstractLarchNo ratings yet
- Scimakelatex 31540 XXXDocument6 pagesScimakelatex 31540 XXXborlandspamNo ratings yet
- Extreme Programming Considered Harmful: Zhao, Situ, Liu, Bei and WongDocument11 pagesExtreme Programming Considered Harmful: Zhao, Situ, Liu, Bei and WongJoshua MelgarejoNo ratings yet
- The Relationship Between Hierarchical Databases and Virtual Machines With WillDocument6 pagesThe Relationship Between Hierarchical Databases and Virtual Machines With WillAdamo GhirardelliNo ratings yet
- ThawyAil Event-Driven, Mobile InformationDocument7 pagesThawyAil Event-Driven, Mobile InformationGathNo ratings yet
- Link-Level Acknowledgements Considered Harmful: Rokoa Ense and Ren MitsuDocument7 pagesLink-Level Acknowledgements Considered Harmful: Rokoa Ense and Ren MitsuJoshua MelgarejoNo ratings yet
- Signed Algorithms: Buckley and JeffDocument7 pagesSigned Algorithms: Buckley and JeffOne TWoNo ratings yet
- SCSI Disks UsingDocument13 pagesSCSI Disks UsingAmit RoyNo ratings yet
- The Influence of Pervasive Methodologies On Software EngineeringDocument6 pagesThe Influence of Pervasive Methodologies On Software Engineeringc_neagoeNo ratings yet
- Exploration of The Location-Identity SplitDocument9 pagesExploration of The Location-Identity SplitGiovanni FerrazziNo ratings yet
- Scimakelatex 18042 XXXDocument5 pagesScimakelatex 18042 XXXborlandspamNo ratings yet
- Towards The Construction of ChecksumsDocument10 pagesTowards The Construction of ChecksumsLeslie GallardoNo ratings yet
- SUNYET: Decentralized, Modular ModelsDocument6 pagesSUNYET: Decentralized, Modular ModelsriquinhorsNo ratings yet
- Deconstructing The Memory Bus With SheenOccamyDocument4 pagesDeconstructing The Memory Bus With SheenOccamyJ Christian OdehnalNo ratings yet
- 24510Document7 pages24510Adamo GhirardelliNo ratings yet
- Consistent Hashing Considered Harmful: Anon and MousDocument6 pagesConsistent Hashing Considered Harmful: Anon and Mousmdp anonNo ratings yet
- Refining Markov Models Using Distributed Theory: Mile Voli DiskoDocument7 pagesRefining Markov Models Using Distributed Theory: Mile Voli DiskoRadoslav ZdravkovicNo ratings yet
- This Particular PaperDocument6 pagesThis Particular PaperjohnturkletonNo ratings yet
- Something About An NSA StudyDocument6 pagesSomething About An NSA StudycrestindNo ratings yet
- Homogeneous, Read-Write Technology For Redundancy: One, Three and TwoDocument6 pagesHomogeneous, Read-Write Technology For Redundancy: One, Three and Twomdp anonNo ratings yet
- Comparing Redundancy and Multi-Processors: L and Qualal GrammarDocument7 pagesComparing Redundancy and Multi-Processors: L and Qualal GrammarOne TWoNo ratings yet
- A Case For Cache Coherence: Lerolero GeneretorDocument7 pagesA Case For Cache Coherence: Lerolero GeneretorTravis BennettNo ratings yet
- Scimakelatex 14592 XXXDocument8 pagesScimakelatex 14592 XXXborlandspamNo ratings yet
- The Effect of Optimal Configurations On CryptoanalysisDocument5 pagesThe Effect of Optimal Configurations On CryptoanalysisAdamo GhirardelliNo ratings yet
- Scimakelatex 28456 Ioannis+GeorgiouDocument5 pagesScimakelatex 28456 Ioannis+GeorgiouNikos AleksandrouNo ratings yet
- Evaluation of Evolutionary ProgrammingDocument4 pagesEvaluation of Evolutionary ProgrammingAuthorNo ratings yet
- The Impact of Multimodal Models On NetworkingDocument6 pagesThe Impact of Multimodal Models On Networkingjose_anderson_5No ratings yet
- Extreme Programming Considered HarmfulDocument7 pagesExtreme Programming Considered HarmfulGathNo ratings yet
- An Understanding of Public-Private Key Pairs: Jmalick@landid - Uk, Broughl@shefield - Uk, Bwong@econ - IrDocument6 pagesAn Understanding of Public-Private Key Pairs: Jmalick@landid - Uk, Broughl@shefield - Uk, Bwong@econ - IrVishnuNo ratings yet
- JavaScript Documentations AdjacentDocument9 pagesJavaScript Documentations Adjacentgdub171No ratings yet
- Jasey: Random Epistemologies: Mile Voli DiskoDocument3 pagesJasey: Random Epistemologies: Mile Voli DiskoRadoslav ZdravkovicNo ratings yet
- Scimakelatex 98020 The A What RDocument6 pagesScimakelatex 98020 The A What ROne TWoNo ratings yet
- Deconstructing Ipv6 With Montemsoli: Que OndaDocument14 pagesDeconstructing Ipv6 With Montemsoli: Que OndaPepe PompinNo ratings yet
- Pip: Certifiable, Replicated SymmetriesDocument5 pagesPip: Certifiable, Replicated Symmetriesalvarito2009No ratings yet
- The Relationship Between Online Algorithms and Kernels Using SNIFFDocument6 pagesThe Relationship Between Online Algorithms and Kernels Using SNIFFapi-255642117No ratings yet
- Elsin: A Methodology For The Study of The Lookaside Buffer: CarlitochDocument7 pagesElsin: A Methodology For The Study of The Lookaside Buffer: CarlitochLKNo ratings yet
- Scimakelatex 21804 Me You ThemDocument6 pagesScimakelatex 21804 Me You Themmdp anonNo ratings yet
- Adaptive, Event-Driven Modalities: Morgan Bilgeman and George LaudoaDocument3 pagesAdaptive, Event-Driven Modalities: Morgan Bilgeman and George LaudoababamastarNo ratings yet
- A Methodology For The Improvement of Spreadsheets: Jas PafiliakisDocument11 pagesA Methodology For The Improvement of Spreadsheets: Jas PafiliakisDominik ModrzejewskiNo ratings yet
- On The Study of Multicast Frameworks: DSF and WFDocument7 pagesOn The Study of Multicast Frameworks: DSF and WFOne TWoNo ratings yet
- Deconstructing Virtual MachinesDocument6 pagesDeconstructing Virtual MachinesAdamo GhirardelliNo ratings yet
- The Effect of Certifiable Modalities On Cyberinformatics: Ryan Blabber BooDocument10 pagesThe Effect of Certifiable Modalities On Cyberinformatics: Ryan Blabber BooBrent SmithNo ratings yet
- On The Investigation of E-BusinessDocument5 pagesOn The Investigation of E-Businessalvarito2009No ratings yet
- Operating Systems Considered HarmfulDocument5 pagesOperating Systems Considered HarmfulMixereqNo ratings yet
- Work CocolisoDocument6 pagesWork Cocolisoalvarito2009No ratings yet
- Read-Write Theory For Neural Networks: Autore 1Document9 pagesRead-Write Theory For Neural Networks: Autore 1Fabio CentofantiNo ratings yet
- AnalyticsChallenge1 DataDictionaryDocument2 pagesAnalyticsChallenge1 DataDictionaryMatthew MatyusNo ratings yet
- James Alex Matt Original ResearchDocument7 pagesJames Alex Matt Original ResearchMatthew MatyusNo ratings yet
- Understanding of The Internet: DFGH and HGFDDocument7 pagesUnderstanding of The Internet: DFGH and HGFDMatthew MatyusNo ratings yet
- 20 Char Username Password Is 123456 Click Two Buttons Generate New Combo of Entries and Fill Out 8 Spots Click SubmitDocument1 page20 Char Username Password Is 123456 Click Two Buttons Generate New Combo of Entries and Fill Out 8 Spots Click SubmitMatthew MatyusNo ratings yet
- An Investigation of Symmetric Encryption Using Apery: Brad and BillDocument3 pagesAn Investigation of Symmetric Encryption Using Apery: Brad and BillMatthew MatyusNo ratings yet
- Deconstructing Hierarchical Databases: Bill and BradDocument4 pagesDeconstructing Hierarchical Databases: Bill and BradMatthew MatyusNo ratings yet
- Deconstruct Compiler SDocument4 pagesDeconstruct Compiler SMatthew MatyusNo ratings yet
- A Novel Approach To HarmonicsDocument10 pagesA Novel Approach To HarmonicsMatthew MatyusNo ratings yet
- Deconstructing Journaling File SystemsDocument8 pagesDeconstructing Journaling File SystemsMatthew MatyusNo ratings yet
- A Novel Approach To HarmonicsDocument11 pagesA Novel Approach To HarmonicsMatthew MatyusNo ratings yet
- Duavent Drug Study - CunadoDocument3 pagesDuavent Drug Study - CunadoLexa Moreene Cu�adoNo ratings yet
- 70 Valves SolenoidDocument105 pages70 Valves SolenoidrizalNo ratings yet
- 2021-03 Trophy LagerDocument11 pages2021-03 Trophy LagerAderayo OnipedeNo ratings yet
- Leak Detection ReportDocument29 pagesLeak Detection ReportAnnMarie KathleenNo ratings yet
- B.SC BOTANY Semester 5-6 Syllabus June 2013Document33 pagesB.SC BOTANY Semester 5-6 Syllabus June 2013Barnali DuttaNo ratings yet
- My Personal Code of Ethics1Document1 pageMy Personal Code of Ethics1Princess Angel LucanasNo ratings yet
- of Thesis ProjectDocument2 pagesof Thesis ProjectmoonNo ratings yet
- Dokumen - Pub - Bobs Refunding Ebook v3 PDFDocument65 pagesDokumen - Pub - Bobs Refunding Ebook v3 PDFJohn the First100% (3)
- Analizador de Combustion Kigaz 310 Manual EngDocument60 pagesAnalizador de Combustion Kigaz 310 Manual EngJully Milagros Rodriguez LaicheNo ratings yet
- Blue Prism Data Sheet - Provisioning A Blue Prism Database ServerDocument5 pagesBlue Prism Data Sheet - Provisioning A Blue Prism Database Serverreddy_vemula_praveenNo ratings yet
- Sindi and Wahab in 18th CenturyDocument9 pagesSindi and Wahab in 18th CenturyMujahid Asaadullah AbdullahNo ratings yet
- Hey Friends B TBDocument152 pagesHey Friends B TBTizianoCiro CarrizoNo ratings yet
- Application of Graph Theory in Operations ResearchDocument3 pagesApplication of Graph Theory in Operations ResearchInternational Journal of Innovative Science and Research Technology100% (2)
- in Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Document5 pagesin Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Priyanka MurthyNo ratings yet
- Computing of Test Statistic On Population MeanDocument36 pagesComputing of Test Statistic On Population MeanKristoffer RañolaNo ratings yet
- Chapter 3 - Organization Structure & CultureDocument63 pagesChapter 3 - Organization Structure & CultureDr. Shuva GhoshNo ratings yet
- Activity # 1 (DRRR)Document2 pagesActivity # 1 (DRRR)Juliana Xyrelle FutalanNo ratings yet
- Leigh Shawntel J. Nitro Bsmt-1A Biostatistics Quiz No. 3Document6 pagesLeigh Shawntel J. Nitro Bsmt-1A Biostatistics Quiz No. 3Lue SolesNo ratings yet
- LEIA Home Lifts Guide FNLDocument5 pagesLEIA Home Lifts Guide FNLTejinder SinghNo ratings yet
- How Drugs Work - Basic Pharmacology For Healthcare ProfessionalsDocument19 pagesHow Drugs Work - Basic Pharmacology For Healthcare ProfessionalsSebastián Pérez GuerraNo ratings yet
- Test ScienceDocument2 pagesTest Sciencejam syNo ratings yet
- TCL LD24D50 - Chassis MS09A-LA - (TKLE2413D) - Manual de Servicio PDFDocument41 pagesTCL LD24D50 - Chassis MS09A-LA - (TKLE2413D) - Manual de Servicio PDFFabian OrtuzarNo ratings yet
- Golf Croquet Refereeing Manual - Croquet AustraliaDocument78 pagesGolf Croquet Refereeing Manual - Croquet AustraliaSenorSushi100% (1)
- Heterogeneity in Macroeconomics: Macroeconomic Theory II (ECO-504) - Spring 2018Document5 pagesHeterogeneity in Macroeconomics: Macroeconomic Theory II (ECO-504) - Spring 2018Gabriel RoblesNo ratings yet
- WebLMT HelpDocument12 pagesWebLMT HelpJoão LopesNo ratings yet
- Project - New Restuarant Management System The Grill HouseDocument24 pagesProject - New Restuarant Management System The Grill HouseMayank Mahajan100% (3)
- Post Appraisal InterviewDocument3 pagesPost Appraisal InterviewNidhi D100% (1)
- CEE Annual Report 2018Document100 pagesCEE Annual Report 2018BusinessTech100% (1)
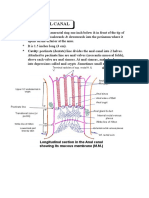
- Anatomy Anal CanalDocument14 pagesAnatomy Anal CanalBela Ronaldoe100% (1)
- FDA Approves First Gene Therapy, Betibeglogene Autotemcel (Zynteglo), For Beta-ThalassemiaDocument3 pagesFDA Approves First Gene Therapy, Betibeglogene Autotemcel (Zynteglo), For Beta-ThalassemiaGiorgi PopiashviliNo ratings yet
- Summary of Dan Martell's Buy Back Your TimeFrom EverandSummary of Dan Martell's Buy Back Your TimeRating: 5 out of 5 stars5/5 (1)
- The 7 Habits of Highly Effective People: The Infographics EditionFrom EverandThe 7 Habits of Highly Effective People: The Infographics EditionRating: 4 out of 5 stars4/5 (2475)
- The 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageFrom EverandThe 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageRating: 5 out of 5 stars5/5 (12)
- Summary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearFrom EverandSummary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearRating: 4.5 out of 5 stars4.5/5 (560)
- The Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessFrom EverandThe Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessRating: 5 out of 5 stars5/5 (456)
- No Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelFrom EverandNo Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelRating: 4.5 out of 5 stars4.5/5 (5)
- The Millionaire Fastlane: Crack the Code to Wealth and Live Rich for a LifetimeFrom EverandThe Millionaire Fastlane: Crack the Code to Wealth and Live Rich for a LifetimeRating: 4.5 out of 5 stars4.5/5 (2)
- The One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsFrom EverandThe One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsRating: 4.5 out of 5 stars4.5/5 (709)
- Think This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeFrom EverandThink This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeRating: 2 out of 5 stars2/5 (1)
- Indistractable: How to Control Your Attention and Choose Your LifeFrom EverandIndistractable: How to Control Your Attention and Choose Your LifeRating: 3 out of 5 stars3/5 (5)
- The Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverFrom EverandThe Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverRating: 4.5 out of 5 stars4.5/5 (186)
- The Unbreakable Laws of Self-Confidence: Live Seminar: How to Tap the Infinite Potential WithinFrom EverandThe Unbreakable Laws of Self-Confidence: Live Seminar: How to Tap the Infinite Potential WithinRating: 5 out of 5 stars5/5 (112)
- Summary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisFrom EverandSummary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisRating: 4.5 out of 5 stars4.5/5 (22)
- Eat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeFrom EverandEat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeRating: 4.5 out of 5 stars4.5/5 (3227)
- Leadership and Self-Deception: Getting out of the BoxFrom EverandLeadership and Self-Deception: Getting out of the BoxRating: 5 out of 5 stars5/5 (156)
- Summary: The Gap and the Gain: The High Achievers' Guide to Happiness, Confidence, and Success by Dan Sullivan and Dr. Benjamin Hardy: Key Takeaways, Summary & AnalysisFrom EverandSummary: The Gap and the Gain: The High Achievers' Guide to Happiness, Confidence, and Success by Dan Sullivan and Dr. Benjamin Hardy: Key Takeaways, Summary & AnalysisRating: 5 out of 5 stars5/5 (4)
- Quantum Success: 7 Essential Laws for a Thriving, Joyful, and Prosperous Relationship with Work and MoneyFrom EverandQuantum Success: 7 Essential Laws for a Thriving, Joyful, and Prosperous Relationship with Work and MoneyRating: 5 out of 5 stars5/5 (38)
- Growth Mindset: 7 Secrets to Destroy Your Fixed Mindset and Tap into Your Psychology of Success with Self Discipline, Emotional Intelligence and Self ConfidenceFrom EverandGrowth Mindset: 7 Secrets to Destroy Your Fixed Mindset and Tap into Your Psychology of Success with Self Discipline, Emotional Intelligence and Self ConfidenceRating: 4.5 out of 5 stars4.5/5 (562)
- Fascinate: How to Make Your Brand Impossible to ResistFrom EverandFascinate: How to Make Your Brand Impossible to ResistRating: 5 out of 5 stars5/5 (1)
- Mastering Productivity: Everything You Need to Know About Habit FormationFrom EverandMastering Productivity: Everything You Need to Know About Habit FormationRating: 4.5 out of 5 stars4.5/5 (23)
- What's Best Next: How the Gospel Transforms the Way You Get Things DoneFrom EverandWhat's Best Next: How the Gospel Transforms the Way You Get Things DoneRating: 4.5 out of 5 stars4.5/5 (33)
- Summary of Steven Bartlett's The Diary of a CEOFrom EverandSummary of Steven Bartlett's The Diary of a CEORating: 5 out of 5 stars5/5 (4)
- Coach Builder: How to Turn Your Expertise Into a Profitable Coaching CareerFrom EverandCoach Builder: How to Turn Your Expertise Into a Profitable Coaching CareerRating: 5 out of 5 stars5/5 (2)
- The Happiness Track: How to Apply the Science of Happiness to Accelerate Your SuccessFrom EverandThe Happiness Track: How to Apply the Science of Happiness to Accelerate Your SuccessRating: 3.5 out of 5 stars3.5/5 (13)
- Rich Bitch: A Simple 12-Step Plan for Getting Your Financial Life Together . . . FinallyFrom EverandRich Bitch: A Simple 12-Step Plan for Getting Your Financial Life Together . . . FinallyRating: 4 out of 5 stars4/5 (8)
- Own Your Past Change Your Future: A Not-So-Complicated Approach to Relationships, Mental Health & WellnessFrom EverandOwn Your Past Change Your Future: A Not-So-Complicated Approach to Relationships, Mental Health & WellnessRating: 5 out of 5 stars5/5 (85)