You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Unit-2-Computer Aided DesignDocument42 pagesUnit-2-Computer Aided DesignMuthuvel M80% (5)
- BMM10233 - Chapter 4 - Theory of EquationsDocument19 pagesBMM10233 - Chapter 4 - Theory of EquationsMohanakrishnaNo ratings yet
- Here A Few Examples of Polynomial FunctionsDocument15 pagesHere A Few Examples of Polynomial FunctionsErigbese Johnson EdiriNo ratings yet
- Dania - 22 - 12363 - 1-Lecture 2 Coordinate System-Fall 2015Document34 pagesDania - 22 - 12363 - 1-Lecture 2 Coordinate System-Fall 2015erwin100% (1)
- Spline Interpolation: ProblemsDocument17 pagesSpline Interpolation: Problemsrazlan ghazaliNo ratings yet
- C2 Algebra - Remainder and Factor TheoremDocument37 pagesC2 Algebra - Remainder and Factor TheoremDermot ChuckNo ratings yet
- Year 9 Teacher Pack 3Document228 pagesYear 9 Teacher Pack 3Mohamed Fouad100% (12)
- AlgebraDocument262 pagesAlgebraOnline EducatorNo ratings yet
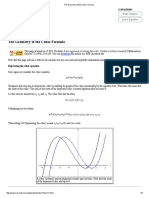
- The Geometry of The Cubic FormulaDocument8 pagesThe Geometry of The Cubic FormuladfygtiuhiNo ratings yet
- Circulant MatricesDocument20 pagesCirculant MatricesAbeer ZahidNo ratings yet
- EquationsDocument5 pagesEquationsmuralikrishnan1994No ratings yet
- Polynomials As PolygonsDocument6 pagesPolynomials As Polygonscandra21No ratings yet
- Monotonic Cubic Spline InterpolationDocument8 pagesMonotonic Cubic Spline InterpolationRMolina65No ratings yet
- Complex NumbersDocument3 pagesComplex Numbersapi-280328793No ratings yet
- How To Sketch The Graph of The DerivativeDocument23 pagesHow To Sketch The Graph of The DerivativeRonak ShahNo ratings yet
- 3.4 Transformations of Power FunctionsDocument2 pages3.4 Transformations of Power FunctionsVasile NicoletaNo ratings yet
- Advanced Ps SamplesDocument12 pagesAdvanced Ps SamplesStuart ClarkNo ratings yet
- AQA IGCSE FM "Full Coverage": DifferentiationDocument12 pagesAQA IGCSE FM "Full Coverage": Differentiationstella FrancisNo ratings yet
- The Cubic FormulaDocument2 pagesThe Cubic Formulabraulio.dantasNo ratings yet
- FEMDocument47 pagesFEMRichard Ore CayetanoNo ratings yet
- Contributions of Islamic Civilization To The Mathematics DevelopmentDocument15 pagesContributions of Islamic Civilization To The Mathematics DevelopmentAbdulRahim059No ratings yet
- Smath StudioDocument47 pagesSmath StudiokeikunbrNo ratings yet
- Types of Geometry in PatranDocument9 pagesTypes of Geometry in PatranNoorul Adha BaharomNo ratings yet
- Cubic FunctionsDocument9 pagesCubic FunctionsShrey JainNo ratings yet
- Extension of Integral Tables FINAL PDFDocument7 pagesExtension of Integral Tables FINAL PDFsolebNo ratings yet
- Sample Algebra 2 Lesson Ipad ActivityDocument4 pagesSample Algebra 2 Lesson Ipad Activityapi-215517770No ratings yet
- ErrorsDocument106 pagesErrorsapi-375687150% (2)
- C1 (Core Mathematics 1) 2008 New SyllabusDocument2 pagesC1 (Core Mathematics 1) 2008 New Syllabusj_amornNo ratings yet
- SM CH PDFDocument14 pagesSM CH PDFHector NaranjoNo ratings yet
- Math 55 A Honors Abstract AlgebraDocument3 pagesMath 55 A Honors Abstract AlgebraccclllNo ratings yet