You might also like
- Statistics For Business Economics 14e Metric Version Chapter3Document73 pagesStatistics For Business Economics 14e Metric Version Chapter3Nguyễn Sĩ NhânNo ratings yet
- Notes (Chapter 1 - 3)Document15 pagesNotes (Chapter 1 - 3)Jeallaine Llena BautistaNo ratings yet
- Regression Model Equation: Sample ProblemDocument10 pagesRegression Model Equation: Sample ProblemLeann Carla Santos Adan100% (1)
- Class DiscussionDocument100 pagesClass DiscussionMadhav Chowdary Tumpati100% (1)
- Articulo - FINANCIAL ANALYSIS ON Fisher & Paykel Healthcare' - 2015 PDFDocument6 pagesArticulo - FINANCIAL ANALYSIS ON Fisher & Paykel Healthcare' - 2015 PDFFreddy VargasNo ratings yet
- WACCDocument6 pagesWACCAbhishek P BenjaminNo ratings yet
- Irr, NPV, PiDocument49 pagesIrr, NPV, PiSuraj ChaudharyNo ratings yet
- Teamwork: Chapter OutlineDocument40 pagesTeamwork: Chapter OutlineyumenashiNo ratings yet
- AF 325 Homework # 1Document3 pagesAF 325 Homework # 1Kunhong ZhouNo ratings yet
- Question #1: Jordan Enterprises Raw MaterialDocument35 pagesQuestion #1: Jordan Enterprises Raw MaterialAimen sakimdadNo ratings yet
- XLSXDocument2 pagesXLSXchristiewijaya100% (1)
- Chapter 2 - Hardware BasicsDocument5 pagesChapter 2 - Hardware BasicsJohn FrandoligNo ratings yet
- Finance Chapter 13 Cost of Capital ProjectDocument8 pagesFinance Chapter 13 Cost of Capital Projectapi-382641983No ratings yet
- Business Computing Exam NotesDocument24 pagesBusiness Computing Exam NotesAgnieszka Wesołowska100% (1)
- Ch.3 13ed Analysis of Fin Stmts MiniC SolsDocument7 pagesCh.3 13ed Analysis of Fin Stmts MiniC SolsAhmed SaeedNo ratings yet
- Reference Sheet: Form - RS6 (Rev 11/11) F&I ToolsDocument1 pageReference Sheet: Form - RS6 (Rev 11/11) F&I ToolsLiamNo ratings yet
- Group-01 Niche and Mainstream (PBME)Document15 pagesGroup-01 Niche and Mainstream (PBME)tejay356No ratings yet
- Information Security NotesDocument7 pagesInformation Security NotesSulaimanNo ratings yet
- QMT 11 NotesDocument150 pagesQMT 11 NotesJustin LeeNo ratings yet
- Capitalization: Capital Vs Operating LeaseDocument2 pagesCapitalization: Capital Vs Operating Leasejohnsmith12312312312No ratings yet
- CH 01 - Data and Statistics: Page 1Document35 pagesCH 01 - Data and Statistics: Page 1Hoang Ha100% (2)
- Chapter 1-Data and Statistics: Multiple ChoiceDocument20 pagesChapter 1-Data and Statistics: Multiple ChoicetichienNo ratings yet
- Cost of Capital Excel Temple-Free CH 10Document10 pagesCost of Capital Excel Temple-Free CH 10Mohiuddin AshrafiNo ratings yet
- Data Sciencefor BusinessDocument107 pagesData Sciencefor BusinessiltdfNo ratings yet
- Industry Analysis (6-Force) Worksheet: Horizontal RelationshipsDocument4 pagesIndustry Analysis (6-Force) Worksheet: Horizontal RelationshipsJulia ValentineNo ratings yet
- Excels For Solution ManualDocument116 pagesExcels For Solution ManualDimple PandeyNo ratings yet
- CVP FormulasDocument1 pageCVP FormulasabhanidharaNo ratings yet
- PROBLEMS ch05Document117 pagesPROBLEMS ch05InciaNo ratings yet
- Final FIN 200 (All Chapters) FIXEDDocument65 pagesFinal FIN 200 (All Chapters) FIXEDMunNo ratings yet
- RATIOSDocument136 pagesRATIOSAadiSharmaNo ratings yet
- Cover Letter TempleteDocument1 pageCover Letter TempleteVickey MehriyaNo ratings yet
- Overview of Strategic MarketingDocument5 pagesOverview of Strategic Marketingglrosaaa cNo ratings yet
- Industry and Competitive AnalysisDocument39 pagesIndustry and Competitive AnalysisNahian HasanNo ratings yet
- Financial Calculator Find Future Value - Time Line: Solving ForDocument3 pagesFinancial Calculator Find Future Value - Time Line: Solving ForPiyush KakkarNo ratings yet
- Capital Budgeting: Factors of Consideration Net Investments Net Returns Cost of CapitalDocument2 pagesCapital Budgeting: Factors of Consideration Net Investments Net Returns Cost of CapitalMary Hazell Victori100% (1)
- Bond Valuation Formulas in ExcelDocument22 pagesBond Valuation Formulas in Excelrameessalam852569No ratings yet
- Statistics Homework Help, Statistics Tutoring, Statistics Tutor - by Online Tutor SiteDocument30 pagesStatistics Homework Help, Statistics Tutoring, Statistics Tutor - by Online Tutor SitemathhomeworkhelpNo ratings yet
- Cheat SheetDocument4 pagesCheat SheetshaziadurraniNo ratings yet
- Valuation of Bonds and Shares: Problem 1Document29 pagesValuation of Bonds and Shares: Problem 1Sourav Kumar DasNo ratings yet
- Ratio CalculationDocument8 pagesRatio CalculationSohel MahmudNo ratings yet
- Financial Management BY Prasanna Chandra Financial Management BY Khan and Jain Financial Management BY I.M.PandeyDocument73 pagesFinancial Management BY Prasanna Chandra Financial Management BY Khan and Jain Financial Management BY I.M.PandeyAksh KhandelwalNo ratings yet
- Principles of Management-OpenStax-part 2Document271 pagesPrinciples of Management-OpenStax-part 2lt castroNo ratings yet
- FINA Chapter 6 HWDocument7 pagesFINA Chapter 6 HWBrandonNo ratings yet
- Financial Management Assignment 1Document8 pagesFinancial Management Assignment 1Puspita RamadhaniaNo ratings yet
- Chapter 2 FUNCTIONS - Microsoft Excel Tutorial #1Document3 pagesChapter 2 FUNCTIONS - Microsoft Excel Tutorial #1Bea GarciaNo ratings yet
- Detailed Chapter Outline: Product Characteristics and ClassificationsDocument44 pagesDetailed Chapter Outline: Product Characteristics and ClassificationsSahar Al-JoburyNo ratings yet
- ACC 230 Coca Cola Final PaperDocument9 pagesACC 230 Coca Cola Final PaperKrissi EbbensNo ratings yet
- Mgac CustomDocument123 pagesMgac CustomJoana TrinidadNo ratings yet
- Answers Are Given in Color: Multiple ChoiceDocument13 pagesAnswers Are Given in Color: Multiple ChoiceMorgan Sills100% (2)
- Ch01 Solutions Manual An Overview of FM and The Financial Management and The FinancialDocument4 pagesCh01 Solutions Manual An Overview of FM and The Financial Management and The FinancialAM FMNo ratings yet
- Chapter 4 QuestionsDocument49 pagesChapter 4 QuestionsJames TaylorNo ratings yet
- CH 4 4-35 SpreadsheetDocument34 pagesCH 4 4-35 Spreadsheetcherishwisdom_997598No ratings yet
- Capital Budgeting WorkShop 2 2020-1Document3 pagesCapital Budgeting WorkShop 2 2020-1Valentina Barreto Puerta0% (1)
- CHAPTER 1 StatisticsDocument41 pagesCHAPTER 1 StatisticsAyushi JangpangiNo ratings yet
- Assignment 2Document1 pageAssignment 2Sumbal JameelNo ratings yet
- Bond Valuation With PluginsDocument23 pagesBond Valuation With PluginsHu-Jean RussellNo ratings yet
- FormulaPlugins For Stats 103013Document7,404 pagesFormulaPlugins For Stats 103013ZackBryant0% (1)
- HW 1, FIN 604, Sadhana JoshiDocument40 pagesHW 1, FIN 604, Sadhana JoshiSadhana JoshiNo ratings yet
- Hand Notes On Cost of Capital and Capital Structure: Composed By: H. B. HamadDocument55 pagesHand Notes On Cost of Capital and Capital Structure: Composed By: H. B. HamadHamad Bakar HamadNo ratings yet
- Unit IVDocument77 pagesUnit IVChetanNo ratings yet
- MODULE-1-PART-1 (Hydraulics)Document6 pagesMODULE-1-PART-1 (Hydraulics)Light HouseNo ratings yet
- Horizontal Motion : Rectilinear Translation (Moving Vessel)Document4 pagesHorizontal Motion : Rectilinear Translation (Moving Vessel)Light HouseNo ratings yet
- MODULE 2 PART 1 (Hydraulics)Document9 pagesMODULE 2 PART 1 (Hydraulics)Light HouseNo ratings yet
- Module 2 Task 1Document2 pagesModule 2 Task 1Light HouseNo ratings yet
- Module 2 Task 2Document2 pagesModule 2 Task 2Light HouseNo ratings yet
- Post Assessment 1Document2 pagesPost Assessment 1Light HouseNo ratings yet
- Lesson 2: Principles of Hydrostatics: Units: Lb/in or Psi (English) N/M or Pa. (S.I.)Document5 pagesLesson 2: Principles of Hydrostatics: Units: Lb/in or Psi (English) N/M or Pa. (S.I.)Light HouseNo ratings yet
- Problem No: 1: Submitted ToDocument4 pagesProblem No: 1: Submitted ToLight HouseNo ratings yet
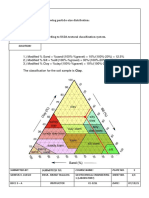
- II. United States Department of Agriculture (USDA) Textural ClassificationDocument17 pagesII. United States Department of Agriculture (USDA) Textural ClassificationLight House100% (1)
- MODULE 2 PART 1 (Hydraulics)Document9 pagesMODULE 2 PART 1 (Hydraulics)Light HouseNo ratings yet
- Lesson IV - Stresses in SoilDocument6 pagesLesson IV - Stresses in SoilLight HouseNo ratings yet
- Module 3Document7 pagesModule 3Light HouseNo ratings yet
- My Respect To Our University President DRDocument1 pageMy Respect To Our University President DRLight HouseNo ratings yet
- Universal Values & Filipino ValuesDocument6 pagesUniversal Values & Filipino ValuesLight House67% (3)
- Probability - Probability Is A Numerical Description of How Likely An Event Is To Occur or How Likely It IsDocument2 pagesProbability - Probability Is A Numerical Description of How Likely An Event Is To Occur or How Likely It IsLight HouseNo ratings yet
- MODULE-1-PART-1 (Hydraulics)Document6 pagesMODULE-1-PART-1 (Hydraulics)Light HouseNo ratings yet
- Universal Values & Filipino ValuesDocument6 pagesUniversal Values & Filipino ValuesLight House67% (3)
- MyanmarsDocument1 pageMyanmarsLight HouseNo ratings yet
- TheBalance Cover Letter 2061569Document1 pageTheBalance Cover Letter 2061569Mj EdinNo ratings yet
- Probability - Probability Is A Numerical Description of How Likely An Event Is To Occur or How Likely It IsDocument2 pagesProbability - Probability Is A Numerical Description of How Likely An Event Is To Occur or How Likely It IsLight HouseNo ratings yet
- FrancisDocument1 pageFrancisLight HouseNo ratings yet
- Rubrics For TeacherDocument1 pageRubrics For TeacherLight HouseNo ratings yet
- TheBalance Cover Letter 2061569Document1 pageTheBalance Cover Letter 2061569Mj EdinNo ratings yet
- MyanmarsDocument1 pageMyanmarsLight HouseNo ratings yet
- MyanmarsDocument1 pageMyanmarsLight HouseNo ratings yet
- Ethics Activity 1Document7 pagesEthics Activity 1Light HouseNo ratings yet
- Rubrics For TeacherDocument1 pageRubrics For TeacherLight HouseNo ratings yet
- Olszewski ClusteringDocument4 pagesOlszewski ClusteringkalokosNo ratings yet
- Quiz April 6 MA 212M: Maths Minor: Instructor: Dr. Arabin Kumar Dey, Department of Mathematics, IIT GuwahatiDocument2 pagesQuiz April 6 MA 212M: Maths Minor: Instructor: Dr. Arabin Kumar Dey, Department of Mathematics, IIT GuwahatiShreya RaiNo ratings yet
- The Challenges of Adopting New Engineering Contract A Hong Kong StudyDocument21 pagesThe Challenges of Adopting New Engineering Contract A Hong Kong Studyajmal100% (1)
- Decision Tree Algorithm, ExplainedDocument20 pagesDecision Tree Algorithm, ExplainedAli KhanNo ratings yet
- Modify-Use Bio. IB Book IB Biology Topic 1: Statistical AnalysisDocument25 pagesModify-Use Bio. IB Book IB Biology Topic 1: Statistical AnalysissarfarazNo ratings yet
- AP Statistics Unit 5 Progress Check MCQ Part A Report DetailsDocument1 pageAP Statistics Unit 5 Progress Check MCQ Part A Report DetailsHannah OtnessNo ratings yet
- Pamantasan NG Cabuyao: Senior High School DepartmentDocument11 pagesPamantasan NG Cabuyao: Senior High School DepartmentJOHN RAVEN BUCAONo ratings yet
- Ega Beq Q&A Web Qa 1 32Document34 pagesEga Beq Q&A Web Qa 1 32KhoranaNo ratings yet
- Quantitative MethodsDocument18 pagesQuantitative MethodsNikhil SawantNo ratings yet
- Teme Pentru Referate La Cursul "Retele Neuronale"Document3 pagesTeme Pentru Referate La Cursul "Retele Neuronale"cernatandNo ratings yet
- Chapter 3 Comm 215 ConcordiaDocument34 pagesChapter 3 Comm 215 Concordiahenry gNo ratings yet
- UGRD-IT6200B Quantitative Methods ALL INDocument11 pagesUGRD-IT6200B Quantitative Methods ALL INWILDRAT CLIPS67% (3)
- Random Motors BriefingDocument43 pagesRandom Motors BriefingAndy KumarNo ratings yet
- Statistical Process ControlDocument40 pagesStatistical Process ControlBrixter GervacioNo ratings yet
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningJiyual MustiNo ratings yet
- Desscriptive Questions: Statistical LabDocument4 pagesDesscriptive Questions: Statistical LabDarshan sakleNo ratings yet
- Normal Probability DistributionsDocument61 pagesNormal Probability DistributionsJuliana Marie RarasNo ratings yet
- The Fim Instrument: Its Background, Structure, and UsefulnessDocument31 pagesThe Fim Instrument: Its Background, Structure, and UsefulnesssamiratumananNo ratings yet
- ISYE 6413: Design and Analysis of Experiments Fall, 2020: Jeffwu@isye - Gatech.eduDocument3 pagesISYE 6413: Design and Analysis of Experiments Fall, 2020: Jeffwu@isye - Gatech.eduYasin Çağatay GültekinNo ratings yet
- Analytical Chemistry - CHEM 3111 - Yong Liu - SI 4112 2-3:15Document24 pagesAnalytical Chemistry - CHEM 3111 - Yong Liu - SI 4112 2-3:15Jeanne KimNo ratings yet
- EstimationDocument12 pagesEstimationwe_spidus_2006No ratings yet
- Tuo Zhao NotesDocument47 pagesTuo Zhao NotesMarc RomaníNo ratings yet
- Assign Ssa 4-5 6 7Document9 pagesAssign Ssa 4-5 6 7parulmoshi0% (1)
- What Is The Central Tendency FormulaDocument18 pagesWhat Is The Central Tendency FormulaCarel Faith AndresNo ratings yet
- Assignment CLO-4 - Attempt ReviewDocument6 pagesAssignment CLO-4 - Attempt ReviewGenerfen FatihNo ratings yet
- Yorke MantzDocument14 pagesYorke MantzChristian Angelo BautistaNo ratings yet
- MODULE 15 Hypothesis TestingDocument30 pagesMODULE 15 Hypothesis TestingEza HasnanNo ratings yet
- Mathematical Model Building and Public Policy - The Games Some Bureaucrats PlayDocument26 pagesMathematical Model Building and Public Policy - The Games Some Bureaucrats PlayGeorge NunesNo ratings yet
- Chapter1&0 (Business Statistics 107 Exercises and Summary)Document26 pagesChapter1&0 (Business Statistics 107 Exercises and Summary)Wejdan NasserNo ratings yet
- Research Workbook Group 2Document9 pagesResearch Workbook Group 2Rexsha ConoNo ratings yet