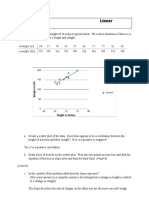
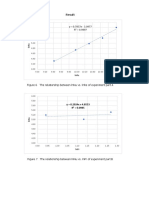
You might also like
- Standard-Slope Integration: A New Approach to Numerical IntegrationFrom EverandStandard-Slope Integration: A New Approach to Numerical IntegrationNo ratings yet
- 07 Solutions RegressionDocument74 pages07 Solutions Regressionijaz afzal50% (2)
- Mechanical Aptitude & Spatial Relations Practice QuestionsFrom EverandMechanical Aptitude & Spatial Relations Practice QuestionsNo ratings yet
- Statap Practicetest 27Document7 pagesStatap Practicetest 27Hoa Dinh NguyenNo ratings yet
- 5.04 Linear Regression and Calibration CurvesDocument14 pages5.04 Linear Regression and Calibration CurvesVero ArellanoNo ratings yet
- XR 607 SolDocument3 pagesXR 607 SolDaríoNo ratings yet
- Two Variable StatisticsDocument12 pagesTwo Variable StatisticsdarlingtonmabayaNo ratings yet
- Sol To Assign2 (2018)Document15 pagesSol To Assign2 (2018)Zac NastNo ratings yet
- Curve Fitting - Lecturers - 2Document21 pagesCurve Fitting - Lecturers - 2Girma JankaNo ratings yet
- Impact of Coefficients On Prognosis of Heart Failure: UK Heart 1 StudyDocument4 pagesImpact of Coefficients On Prognosis of Heart Failure: UK Heart 1 StudyAntonio EleuteriNo ratings yet
- Lab Physics Hook's LawDocument7 pagesLab Physics Hook's LawSouvik GhoshNo ratings yet
- Regression and CorrelationDocument27 pagesRegression and CorrelationDinah Jane MartinezNo ratings yet
- Solution Manual For Interactive Statistics Classic Version 3rd Edition Martha AliagaDocument15 pagesSolution Manual For Interactive Statistics Classic Version 3rd Edition Martha AliagaTiffanyMilleredpn100% (40)
- SSMDocument7 pagesSSMSurya DewantaraNo ratings yet
- WK4 Session 8 Workshop (CH 10)Document28 pagesWK4 Session 8 Workshop (CH 10)Zaeem AsgharNo ratings yet
- Share Chapter # 04Document20 pagesShare Chapter # 04Aaila AkhterNo ratings yet
- Week 8 AssessmentDocument14 pagesWeek 8 AssessmentJames BowmanNo ratings yet
- Qusetion 111 2 Data Analysis Assignment (問題卷)Document4 pagesQusetion 111 2 Data Analysis Assignment (問題卷)huangNo ratings yet
- Correlation and Regression Skill SetDocument8 pagesCorrelation and Regression Skill SetKahloon ThamNo ratings yet
- VII Pearson RDocument4 pagesVII Pearson RJamaica AntonioNo ratings yet
- Chapter 13 SolDocument21 pagesChapter 13 SolPloy SuNo ratings yet
- Linear Regression LabDocument6 pagesLinear Regression Labapi-356010793100% (2)
- Exercise 1Document5 pagesExercise 1Lemi Taye0% (1)
- Unit 1 Review: Scientific Methods: Time (S) Mass (KG) Trial 1 Trial 2 Trial 3 Trial 4Document6 pagesUnit 1 Review: Scientific Methods: Time (S) Mass (KG) Trial 1 Trial 2 Trial 3 Trial 4Marina QuaveNo ratings yet
- Lesson 7 Pearson Product of Moment Coefficient CorrelationDocument6 pagesLesson 7 Pearson Product of Moment Coefficient CorrelationMaricar PinedaNo ratings yet
- CME106 Problem Set 6Document2 pagesCME106 Problem Set 6Tony HuaNo ratings yet
- Numerical Method - BisectionDocument13 pagesNumerical Method - BisectionAmeq Azaulmay100% (1)
- Regresión Lineal Jorge Andrés Grenett Munita Estadística Instituto IACC 10 de Diciembre 2017Document5 pagesRegresión Lineal Jorge Andrés Grenett Munita Estadística Instituto IACC 10 de Diciembre 2017patricioNo ratings yet
- Scientific MethodDocument10 pagesScientific Methodassf7235No ratings yet
- Chart Title: ensayo m (kg) T (N) β n velocidad de propagacion (m/s)Document1 pageChart Title: ensayo m (kg) T (N) β n velocidad de propagacion (m/s)Danilo BurgosNo ratings yet
- Calculus: Describing Change:Rates - Project 2.1 - "Fee Refund Schedules"Document20 pagesCalculus: Describing Change:Rates - Project 2.1 - "Fee Refund Schedules"veer12311No ratings yet
- Indian Institute of Technology: MS 5031: Data Analysis Applications in Class Assignment-1 October 24, 2016Document2 pagesIndian Institute of Technology: MS 5031: Data Analysis Applications in Class Assignment-1 October 24, 2016Vikas SinghNo ratings yet
- Statistics For Business Decision Making and Analysis 3rd Edition Stine Test BankDocument7 pagesStatistics For Business Decision Making and Analysis 3rd Edition Stine Test Bankselinaanhon9a100% (20)
- Question 1 - 9310226Document6 pagesQuestion 1 - 9310226mehdiNo ratings yet
- LmodelDocument12 pagesLmodelRaghavendra SwamyNo ratings yet
- MaglevDocument23 pagesMaglevsara_shedidNo ratings yet
- Part A A) : How I Used The MoneyDocument8 pagesPart A A) : How I Used The MoneyAizat Helmi AliNo ratings yet
- Learning Guide Module: Examine The Graph Shown in Figure 1. What Have You Noticed?Document10 pagesLearning Guide Module: Examine The Graph Shown in Figure 1. What Have You Noticed?Maeve DizonNo ratings yet
- Simple Linear Regression: Interpreting Minitab OutputDocument4 pagesSimple Linear Regression: Interpreting Minitab Outputrkrajesh86No ratings yet
- Tutorial 6 Linear Regression and CorrelationDocument4 pagesTutorial 6 Linear Regression and CorrelationPeeka Syuhada RosliNo ratings yet
- Solutions To End-of-Section and Chapter Review Problems 517Document39 pagesSolutions To End-of-Section and Chapter Review Problems 517Selly Anastassia Amellia KharisNo ratings yet
- Written Report1 V3Document11 pagesWritten Report1 V3Timothy XiongNo ratings yet
- Edur 8131 Notes 6 CorrelationDocument25 pagesEdur 8131 Notes 6 CorrelationNazia SyedNo ratings yet
- CHPT 12 HomeworkDocument22 pagesCHPT 12 HomeworkManish Gupta100% (1)
- Chi Squares and Analysis of VarianceDocument48 pagesChi Squares and Analysis of VarianceAkum obenNo ratings yet
- ReportDocument12 pagesReportJoaquinNo ratings yet
- Repaso Final - Estadistica, Spring 2022 - WebAssignDocument20 pagesRepaso Final - Estadistica, Spring 2022 - WebAssignMarlene Hernández OcadizNo ratings yet
- Environmental EconDocument10 pagesEnvironmental EconEMINAT PRINCENo ratings yet
- Problem Set 6Document4 pagesProblem Set 6PeaceNo ratings yet
- Time: 3 Hours Total Marks: 100: MBA (Sem I) Theory Examination 2017-18 Business StatisticsDocument2 pagesTime: 3 Hours Total Marks: 100: MBA (Sem I) Theory Examination 2017-18 Business StatisticsNishant TripathiNo ratings yet
- Lab7 1Document2 pagesLab7 1Paweekan HansungnoenNo ratings yet
- Graphing DataDocument8 pagesGraphing DatamphoNo ratings yet
- The Imaginary Theorem of Large Samples: How Many Data Do You Need? Donald J. WheelerDocument5 pagesThe Imaginary Theorem of Large Samples: How Many Data Do You Need? Donald J. Wheelertehky63No ratings yet
- Neutralization Reaction Mathematics Internal Assessment: Candidate Number: Session: SupervisorDocument14 pagesNeutralization Reaction Mathematics Internal Assessment: Candidate Number: Session: Supervisoribrahim fadelNo ratings yet
- BCHEM 365 November 20, 2017: Sample Channel Ratio (SCR)Document21 pagesBCHEM 365 November 20, 2017: Sample Channel Ratio (SCR)Duodu StevenNo ratings yet
- 06 Simple ModelingDocument16 pages06 Simple Modelingdéborah_rosalesNo ratings yet
- Peason Product Moment Correlation Coefficient Numata Izumi C. ProjectDocument16 pagesPeason Product Moment Correlation Coefficient Numata Izumi C. ProjectJohn Marvin CanariaNo ratings yet
- Notes6 CorrelationDocument28 pagesNotes6 CorrelationNazia SyedNo ratings yet
- Chapter 7Document6 pagesChapter 7Mohammad AnikNo ratings yet
- Curve Fitting ST Line and ParabolaDocument12 pagesCurve Fitting ST Line and ParabolaRakesh K0% (1)
- Comprehensive Company DatabseDocument62 pagesComprehensive Company Databseijaz afzalNo ratings yet
- Chapter Four Introduction To Probability Concepts ReviewerDocument3 pagesChapter Four Introduction To Probability Concepts Reviewerijaz afzalNo ratings yet
- 2018Q4 Factory Disclosure ListDocument60 pages2018Q4 Factory Disclosure Listijaz afzalNo ratings yet
- Understanding PID Control SystemsDocument13 pagesUnderstanding PID Control Systemsijaz afzalNo ratings yet
- Factor: 12 App MethodologyDocument42 pagesFactor: 12 App Methodologyijaz afzalNo ratings yet
- Command LineDocument87 pagesCommand Lineijaz afzalNo ratings yet
- EGA324 C1 Surname StudentID 000000 (17 18)Document4 pagesEGA324 C1 Surname StudentID 000000 (17 18)ijaz afzalNo ratings yet
- Chromosome: ClassDocument3 pagesChromosome: Classijaz afzalNo ratings yet
- A Fast Algorithm To Determine Normal Polynomial Over Finite FieldsDocument6 pagesA Fast Algorithm To Determine Normal Polynomial Over Finite Fieldsijaz afzalNo ratings yet
- Math Lab 007Document8 pagesMath Lab 007ijaz afzalNo ratings yet
- Expression) To Find The Susceptible WebsiteDocument1 pageExpression) To Find The Susceptible Websiteijaz afzalNo ratings yet
- Assignment 4 Template-ForecastsDocument1 pageAssignment 4 Template-Forecastsijaz afzalNo ratings yet
- Application (30 Points) :: and Monitoring Schedule For The Next Year Based On The Results From The Outside ReviewDocument7 pagesApplication (30 Points) :: and Monitoring Schedule For The Next Year Based On The Results From The Outside Reviewijaz afzalNo ratings yet
- Chapter 1 5 Newest 4Document37 pagesChapter 1 5 Newest 4bell pakseNo ratings yet
- Welcome To Forecasting Using R: Rob J. HyndmanDocument33 pagesWelcome To Forecasting Using R: Rob J. HyndmanNathan GurgelNo ratings yet
- Chapter6. Analytical Chemistry - Dr.RIMADocument19 pagesChapter6. Analytical Chemistry - Dr.RIMAObada SibaiNo ratings yet
- CHAPTER 6lesson 4Document11 pagesCHAPTER 6lesson 4Leandro Ulysis Tayco OronganNo ratings yet
- DATA SCIENCE With DA, ML, DL, AI Using Python & R PDFDocument10 pagesDATA SCIENCE With DA, ML, DL, AI Using Python & R PDFSaikumar ReddyNo ratings yet
- Thermo Finnigan ELEMENT2 Operating ManualDocument378 pagesThermo Finnigan ELEMENT2 Operating ManualVladislavDultsevNo ratings yet
- Regression ANOVA CompiledDocument112 pagesRegression ANOVA Compiledsumit kumarNo ratings yet
- Activity Template - Course 1 PACE Strategy DocumentDocument6 pagesActivity Template - Course 1 PACE Strategy DocumentGodwinNo ratings yet
- Krajewski Om9 PPT 13Document83 pagesKrajewski Om9 PPT 13Burcu Karaöz100% (1)
- Table of Standard Scores Child's Record 2Document1 pageTable of Standard Scores Child's Record 2Francis Nicor100% (4)
- History of RegressionDocument13 pagesHistory of Regressiontoms446No ratings yet
- MAHE - MIT 12042019 Attendance PDFDocument33 pagesMAHE - MIT 12042019 Attendance PDFNilesh GajwaniNo ratings yet
- 74 Data IngestionDocument3 pages74 Data IngestionGGNo ratings yet
- The Importance of Medico-Legal Officer in Crime Scene ProcessingDocument71 pagesThe Importance of Medico-Legal Officer in Crime Scene ProcessingJack SisibanNo ratings yet
- MBA Fintech I II SEM SYLLABUS FINAL 05.09.2018Document19 pagesMBA Fintech I II SEM SYLLABUS FINAL 05.09.2018Suriya KakaniNo ratings yet
- Faculty of Management: Syllabus For Master of Business AdministrationDocument19 pagesFaculty of Management: Syllabus For Master of Business AdministrationSri NandhuNo ratings yet
- F 1Document18 pagesF 1damandaaruNo ratings yet
- Sankalan 2017 (Pratibha National Level Summer Project Competition)Document81 pagesSankalan 2017 (Pratibha National Level Summer Project Competition)biotech_savvyNo ratings yet
- MGT555 CH 6 Regression AnalysisDocument19 pagesMGT555 CH 6 Regression AnalysisSITI MADHIHAH OTHMANNo ratings yet
- Handel, 2020Document29 pagesHandel, 2020BENITO LUIS SOVERO SOTONo ratings yet
- Financial Management in The Public SectorDocument216 pagesFinancial Management in The Public SectorRubens KöthNo ratings yet
- A Study On Financial Performance With SpecialDocument37 pagesA Study On Financial Performance With SpecialSarin SayalNo ratings yet
- Practical Research 2 Quarter 2 Module 1Document18 pagesPractical Research 2 Quarter 2 Module 1renierpardz09No ratings yet
- Spark LabDocument6 pagesSpark LabNistor GrozavuNo ratings yet
- Data Analysis & Exploratory Data Analysis (EDA)Document14 pagesData Analysis & Exploratory Data Analysis (EDA)John Luis Masangkay BantolinoNo ratings yet
- Research Methodology PracticalDocument64 pagesResearch Methodology PracticalRitik ThakurNo ratings yet
- Idem - Adyanto Armando PurbaDocument3 pagesIdem - Adyanto Armando PurbaIlman AshariNo ratings yet
- Data Analysis With Python - FreeCodeCampDocument28 pagesData Analysis With Python - FreeCodeCamptekula akhilNo ratings yet
- Single-Case Research Design and Analysis New Directions For Psychology and Education Thomas R. KratochwillDocument247 pagesSingle-Case Research Design and Analysis New Directions For Psychology and Education Thomas R. Kratochwilliting.samNo ratings yet
- Marketing Research For A Restaurant in Hendon, London.Document27 pagesMarketing Research For A Restaurant in Hendon, London.Manzil MadhwaniNo ratings yet