You might also like
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Xcode Cheat Sheet: Search Navigation EditingDocument2 pagesXcode Cheat Sheet: Search Navigation EditingYouJian Low0% (1)
- Microelectronics TechDocument33 pagesMicroelectronics TechmailstonaikNo ratings yet
- The Patent Analyst - Patent Analysis and Patent Program Processes and Best PracticesDocument64 pagesThe Patent Analyst - Patent Analysis and Patent Program Processes and Best PracticesmailstonaikNo ratings yet
- PHP The Ultimate Step by Step Guide For BeginnersDocument182 pagesPHP The Ultimate Step by Step Guide For BeginnersAnonymous 6WUzAScL2100% (1)
- CH06 Memory OrganizationDocument85 pagesCH06 Memory OrganizationBiruk KassahunNo ratings yet
- Crystall GrowthDocument41 pagesCrystall Growthmailstonaik100% (1)
- Unit 5 Memory SystemDocument77 pagesUnit 5 Memory SystemsubithavNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Cache MemoryDocument43 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Cache MemoryabbasNo ratings yet
- 11 Cache Memory, Internal, ExternalDocument102 pages11 Cache Memory, Internal, Externalbezelx1No ratings yet
- Memory CacheDocument18 pagesMemory CacheFunsuk VangduNo ratings yet
- Memory OrganizationDocument57 pagesMemory OrganizationvpriyacseNo ratings yet
- 04 Cache Memory ComparcDocument47 pages04 Cache Memory ComparcMekonnen WubshetNo ratings yet
- 23 Cache Memory Basics 11-03-2024Document19 pages23 Cache Memory Basics 11-03-2024suhas kodakandlaNo ratings yet
- 04 Cache MemoryDocument36 pages04 Cache Memorymubarra shabbirNo ratings yet
- Advanced Computer Architecture: BY Dr. Radwa M. TawfeekDocument32 pagesAdvanced Computer Architecture: BY Dr. Radwa M. TawfeekRadwa TawfeekNo ratings yet
- Lecture MemoryDocument55 pagesLecture MemoryMohamad YassineNo ratings yet
- Lecture Memory RemovedDocument33 pagesLecture Memory RemovedMohamad YassineNo ratings yet
- CA-unit 5-Material-For ReferenceDocument16 pagesCA-unit 5-Material-For Reference22iz014No ratings yet
- Week 4,5 Cache MemoryDocument54 pagesWeek 4,5 Cache MemoryMahrukh KhanNo ratings yet
- R RRRRRRRR FinalDocument28 pagesR RRRRRRRR FinalRachell BenemeritoNo ratings yet
- Chapter 3 CacheDocument38 pagesChapter 3 CacheSetina AliNo ratings yet
- Characteristics Location Capacity Unit of Transfer Access Method Performance Physical Type Physical Characteristics OrganisationDocument53 pagesCharacteristics Location Capacity Unit of Transfer Access Method Performance Physical Type Physical Characteristics OrganisationMarkNo ratings yet
- Main Memory: IS104 Operating Systems ConceptDocument62 pagesMain Memory: IS104 Operating Systems ConceptGABRIEL BUFFON HARAHAP (00000061688)No ratings yet
- Parallel 2Document14 pagesParallel 2sivakumarb92No ratings yet
- Computer Organization and Architecture William Stallings (PDFDrive)Document120 pagesComputer Organization and Architecture William Stallings (PDFDrive)Shean QuinonesNo ratings yet
- 11 MemoryDocument41 pages11 MemoryKhoa PhamNo ratings yet
- Module 4: Memory System Organization & ArchitectureDocument97 pagesModule 4: Memory System Organization & ArchitectureSurya SunderNo ratings yet
- Chache Memory, Internal Memory and External MemoryDocument113 pagesChache Memory, Internal Memory and External MemoryEphraimNo ratings yet
- Chapter 5 Memory OrganizationDocument75 pagesChapter 5 Memory Organizationendris yimerNo ratings yet
- Cache Memory - January 2014Document90 pagesCache Memory - January 2014Dare DevilNo ratings yet
- Comarch - Week 5 MemoryDocument31 pagesComarch - Week 5 MemoryT VinassaurNo ratings yet
- Memory ManagementDocument71 pagesMemory ManagementRaza AhmadNo ratings yet
- Qn:Explain Different Latency Hiding Techniques /mechanisms? (Ans:Describe Sections 6.1.2,6.1.3, 6.1.5, 6.2.2.)Document28 pagesQn:Explain Different Latency Hiding Techniques /mechanisms? (Ans:Describe Sections 6.1.2,6.1.3, 6.1.5, 6.2.2.)ripcord jakeNo ratings yet
- Lecture 06Document43 pagesLecture 06Meena ShahNo ratings yet
- Memory Sub-System: CT101 - Computing SystemsDocument46 pagesMemory Sub-System: CT101 - Computing SystemstopherskiNo ratings yet
- Chapter - 3 Memory SystemsDocument78 pagesChapter - 3 Memory SystemscudarunNo ratings yet
- Storage ManagementDocument11 pagesStorage ManagementSimbisoNo ratings yet
- Memory Hierarchy & Cache MemoryDocument40 pagesMemory Hierarchy & Cache MemorybiliNo ratings yet
- CH 4.ppt Type IDocument60 pagesCH 4.ppt Type Ilaraibnawaz86No ratings yet
- Chapter 1 Part 2Document33 pagesChapter 1 Part 2Mat Dunlop Bin Senapang GajahNo ratings yet
- Main MemoryDocument57 pagesMain MemoryBilal WarraichNo ratings yet
- Chapter 8: Memory ManagementDocument51 pagesChapter 8: Memory ManagementRashi KumariNo ratings yet
- Mega Code: Access MethodsDocument5 pagesMega Code: Access MethodsMahmoud ElmahdyNo ratings yet
- Computer Org - L5Document43 pagesComputer Org - L5محمد العموديNo ratings yet
- UNIT-IV Memory and I/ODocument36 pagesUNIT-IV Memory and I/OJeshanth KaniNo ratings yet
- Lecture: Cache Hierarchies: Topics: Cache Innovations (Sections B.1-B.3, 2.1)Document20 pagesLecture: Cache Hierarchies: Topics: Cache Innovations (Sections B.1-B.3, 2.1)Matthew BattleNo ratings yet
- Module 4 Memory (BKM)Document50 pagesModule 4 Memory (BKM)Adyasha mishraNo ratings yet
- Osunit 3Document72 pagesOsunit 3prins lNo ratings yet
- CH 06Document58 pagesCH 06Yohannes DerejeNo ratings yet
- Virtu RalDocument48 pagesVirtu Ral21070106 Nguyễn Xuân ThếNo ratings yet
- Cache MemoryDocument39 pagesCache MemoryhariprasathkNo ratings yet
- Computer Organization Architecture - Topic 5Document36 pagesComputer Organization Architecture - Topic 5asj233510377No ratings yet
- Cache MemoryDocument12 pagesCache MemoryNikhita VNo ratings yet
- The Memory System (Part I) : Computer Science Department Second StageDocument22 pagesThe Memory System (Part I) : Computer Science Department Second Stagejimmy8788No ratings yet
- Cache Memory: 13 March 2013Document80 pagesCache Memory: 13 March 2013Guru BalanNo ratings yet
- UNIT-3 What Does It Mean by Memory Management Unit?Document15 pagesUNIT-3 What Does It Mean by Memory Management Unit?Alwin HiltonNo ratings yet
- 07 Main MemoryDocument80 pages07 Main MemoryBùi Đức HảiNo ratings yet
- MemoryDocument57 pagesMemorydokumbaro30No ratings yet
- Memory SystemsDocument36 pagesMemory SystemsBisma AmirNo ratings yet
- Unit 5-Memory OrganizationDocument34 pagesUnit 5-Memory Organizationpanigrahysagar7No ratings yet
- Chapter5-The Memory SystemDocument36 pagesChapter5-The Memory Systemv69gnf5csyNo ratings yet
- CS4310 MemoryManagementDocument40 pagesCS4310 MemoryManagementtototoNo ratings yet
- Memory ManagementDocument33 pagesMemory ManagementSpence EliverNo ratings yet
- Memory OrganizationDocument30 pagesMemory OrganizationPARITOSHNo ratings yet
- EC 2007 With SolutionsDocument46 pagesEC 2007 With SolutionsmailstonaikNo ratings yet
- Semiconductor Manufacturing ProcessesDocument32 pagesSemiconductor Manufacturing ProcessesmailstonaikNo ratings yet
- Phase Diagram: - Only Certain Compositions of Materials Are Allowed at ADocument16 pagesPhase Diagram: - Only Certain Compositions of Materials Are Allowed at AmailstonaikNo ratings yet
- Crystal Growth TechniquesDocument29 pagesCrystal Growth TechniquesmailstonaikNo ratings yet
- Decoding of Linear Block Codes: Syndrome and Error CorrectionDocument25 pagesDecoding of Linear Block Codes: Syndrome and Error CorrectionmailstonaikNo ratings yet
- Convolutional CodesDocument16 pagesConvolutional CodesmailstonaikNo ratings yet
- Systematic Cyclic Codes Parity Check PolynomialDocument15 pagesSystematic Cyclic Codes Parity Check PolynomialmailstonaikNo ratings yet
- Lecture 12Document13 pagesLecture 12mailstonaikNo ratings yet
- ECE 563: Information Theory Moulin, Fall 2012 Solutions To Problem Set 5 (CT 7.33)Document8 pagesECE 563: Information Theory Moulin, Fall 2012 Solutions To Problem Set 5 (CT 7.33)mailstonaikNo ratings yet
- Coding Theory: A Bird S Eye View: Continued Block Codes: BasicsDocument32 pagesCoding Theory: A Bird S Eye View: Continued Block Codes: BasicsmailstonaikNo ratings yet
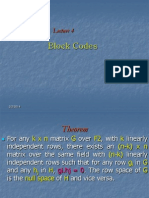
- Lecture 4Document20 pagesLecture 4mailstonaikNo ratings yet
- BCH CodesDocument23 pagesBCH CodesmailstonaikNo ratings yet
- The Fundamental Approach: Decoding Procedure For BCH CodesDocument16 pagesThe Fundamental Approach: Decoding Procedure For BCH CodesmailstonaikNo ratings yet
- 10 Extension FiledsDocument18 pages10 Extension FiledsmailstonaikNo ratings yet
- 1532214918601Document176 pages1532214918601Ferry FirmansyahNo ratings yet
- C Mcqs PDFDocument98 pagesC Mcqs PDFansabNo ratings yet
- HP MSM765 ZL Mobility Controller Installation GuideDocument25 pagesHP MSM765 ZL Mobility Controller Installation GuideMichael McCormickNo ratings yet
- Chapter 11B: Survey of Database SystemsDocument17 pagesChapter 11B: Survey of Database SystemsMurtaza MoizNo ratings yet
- Shihab Saadi ResumeDocument1 pageShihab Saadi ResumeMd. Nazmus ShakibNo ratings yet
- Lenovo Z500 DatasheetDocument2 pagesLenovo Z500 DatasheetMahendra KammaNo ratings yet
- EmulogDocument2 pagesEmulogTigerNo ratings yet
- SAP Solution Manager 4.0 SR3 On Linux MaxDBDocument140 pagesSAP Solution Manager 4.0 SR3 On Linux MaxDBmouladjNo ratings yet
- Microsoft Software Assurance BenefitsDocument6 pagesMicrosoft Software Assurance BenefitsbrookptNo ratings yet
- QWupdateDocument9 pagesQWupdatekgskgmNo ratings yet
- CAN Bus-Based I/O Module, CIO 116: Installation and Commissioning GuideDocument19 pagesCAN Bus-Based I/O Module, CIO 116: Installation and Commissioning Guidemiguel oswaldo gonzalez benitezNo ratings yet
- MS WmiDocument234 pagesMS WmibubbaoriellyNo ratings yet
- XnView User ManualDocument57 pagesXnView User ManualAngieNo ratings yet
- Manual Center 390Document20 pagesManual Center 390aleNo ratings yet
- Approval WFPosted Purch InvoiceDocument8 pagesApproval WFPosted Purch InvoiceMeddah MehdiNo ratings yet
- Data ConduitDocument176 pagesData ConduitLuciano Rodrigues E RodriguesNo ratings yet
- WCF Rest XML PostDocument3 pagesWCF Rest XML PostRajesh SamanthNo ratings yet
- Time Table For Individual Staff - EvenDocument5 pagesTime Table For Individual Staff - EvenRaja ANo ratings yet
- B66273L Vol3 PDFDocument116 pagesB66273L Vol3 PDFsami belkhiriaNo ratings yet
- (TWRP) For KIW-L24, L22, L21 (Kiwi) - Honor 5X PDFDocument14 pages(TWRP) For KIW-L24, L22, L21 (Kiwi) - Honor 5X PDFHassan Mody TotaNo ratings yet
- LC-3 Assembly LanguageDocument18 pagesLC-3 Assembly LanguageElad TalicNo ratings yet
- RoboDK Doc EN Robots KUKADocument7 pagesRoboDK Doc EN Robots KUKAПаша БыковNo ratings yet
- ShipRight FDA Level 2 FAQDocument11 pagesShipRight FDA Level 2 FAQnkoreisha7752No ratings yet
- Reusable Verification Environment For Verification of Ethernet PDFDocument4 pagesReusable Verification Environment For Verification of Ethernet PDFRachel GreenNo ratings yet
- Xilinx Behavioral SimulationDocument4 pagesXilinx Behavioral SimulationSandeep Kumar KrishnarajNo ratings yet
- DartDocument12 pagesDartarunbm777No ratings yet
- Microcontrollers: MC68HC705J1A MC68HRC705J1A MC68HSC705J1A MC68HSR705J1ADocument162 pagesMicrocontrollers: MC68HC705J1A MC68HRC705J1A MC68HSC705J1A MC68HSR705J1ADiego GoncalvesNo ratings yet
- Supplied PackageDocument10 pagesSupplied Packageapi-3831209No ratings yet