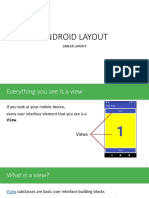
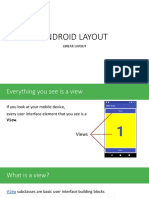
You might also like
- UAP UFO Military Threat Updated August 4Document182 pagesUAP UFO Military Threat Updated August 4jgomezd19791No ratings yet
- Euler's Pioneering Work on Integer PartitionsDocument22 pagesEuler's Pioneering Work on Integer PartitionsHimanshu KumarNo ratings yet
- Kernel PCADocument6 pagesKernel PCAशुभमपटेलNo ratings yet
- D Alembert SolutionDocument22 pagesD Alembert SolutionDharmendra Kumar0% (1)
- De Broglie Berg Schrodinger Quantum ModelDocument41 pagesDe Broglie Berg Schrodinger Quantum ModelEamon BarkhordarianNo ratings yet
- Reich Contact SpaceDocument86 pagesReich Contact SpaceClayton RobertsonNo ratings yet
- Figurate NumbersDocument10 pagesFigurate Numbersjmertes100% (1)
- Subtraction and Division of Neutrosophic NumbersDocument8 pagesSubtraction and Division of Neutrosophic NumbersMia AmaliaNo ratings yet
- Einstein's Gravitational Waves DetectedDocument4 pagesEinstein's Gravitational Waves DetectedPrakash HiremathNo ratings yet
- Bohrs Correspondence Principle PDFDocument23 pagesBohrs Correspondence Principle PDFsmeenaNo ratings yet
- Pseudo GravityDocument5 pagesPseudo GravityLuis De Melo TassinariNo ratings yet
- From the Big Bang to Dark EnergyDocument8 pagesFrom the Big Bang to Dark EnergyWasyhun AsefaNo ratings yet
- Michael Harney and Ioannis Iraklis Haranas - The Dark Energy ProblemDocument3 pagesMichael Harney and Ioannis Iraklis Haranas - The Dark Energy ProblemMuths999999No ratings yet
- Unit 1: Fourier Series: X X X F X NX N NX N NDocument2 pagesUnit 1: Fourier Series: X X X F X NX N NX N NHarish ManikandanNo ratings yet
- Milne - Fields and Galois TheoryDocument111 pagesMilne - Fields and Galois TheoryDavid FerreiraNo ratings yet
- Comparing Areas Under Correlated ROC Curves Using Nonparametric ApproachDocument10 pagesComparing Areas Under Correlated ROC Curves Using Nonparametric Approachajax_telamonioNo ratings yet
- Geometry and Groups T. K. CarneDocument107 pagesGeometry and Groups T. K. CarnePriscila Gutierres100% (1)
- Probability and Statistics ConceptsDocument73 pagesProbability and Statistics ConceptsatifNo ratings yet
- 430258214maths Psa Quantitative Aptitude For Class Ix and X 2014-15Document95 pages430258214maths Psa Quantitative Aptitude For Class Ix and X 2014-15jpsmu09100% (1)
- Relativity and Color TheoryDocument32 pagesRelativity and Color TheoryasifbaltiNo ratings yet
- Phys 2o6 Sol Assign5Document13 pagesPhys 2o6 Sol Assign5a1malik420No ratings yet
- Structure of Atom MAster Explanation PRESS4Document105 pagesStructure of Atom MAster Explanation PRESS4Chad Ashley VandenbergNo ratings yet
- Lecture Notes On Statistical Physics by Peter JohanssonDocument66 pagesLecture Notes On Statistical Physics by Peter JohanssonhumejiasNo ratings yet
- Integral: Integration Is An Important Concept in Mathematics And, Together WithDocument22 pagesIntegral: Integration Is An Important Concept in Mathematics And, Together WithSabith GassaliNo ratings yet
- Spectral Analysis of Julia Sets Reveals Geometric PropertiesDocument142 pagesSpectral Analysis of Julia Sets Reveals Geometric Propertiessysche100% (1)
- Gravitational Flux and Space Curvatures Under Gravitational ForcesDocument4 pagesGravitational Flux and Space Curvatures Under Gravitational ForcespaharalalageNo ratings yet
- Feynman's Lost LectureDocument3 pagesFeynman's Lost Lectureggriff24No ratings yet
- Quantum Mechanics NotesDocument21 pagesQuantum Mechanics NotesPujan MehtaNo ratings yet
- Sequences Generated by PolynomialsDocument5 pagesSequences Generated by PolynomialsE Frank CorneliusNo ratings yet
- Clarifications Pertaining To The Observer RaceDocument5 pagesClarifications Pertaining To The Observer RaceGuthrie Douglas PrenticeNo ratings yet
- Classical Descriptive Set Theory: 1.1 Topological and Metric SpacesDocument14 pagesClassical Descriptive Set Theory: 1.1 Topological and Metric SpacesKarn KumarNo ratings yet
- Capacitive Feed Through Calculations in MOSFET IC'sDocument2 pagesCapacitive Feed Through Calculations in MOSFET IC'sharishkumarsinghNo ratings yet
- Quantum Confined StructuresDocument19 pagesQuantum Confined StructuresHaris AmirNo ratings yet
- Fundamentals of The Electromagnetic MethodDocument8 pagesFundamentals of The Electromagnetic MethodEder VacaNo ratings yet
- 6.1.07 Ra Music Write UpDocument40 pages6.1.07 Ra Music Write Updanobikwelu_scribd100% (1)
- Teaching Electromagnetic Field Theory Using Differential Forms PDFDocument18 pagesTeaching Electromagnetic Field Theory Using Differential Forms PDFmukulNo ratings yet
- Doug Bates Mixed ModelsDocument75 pagesDoug Bates Mixed ModelsDuy NguyenNo ratings yet
- Millikan Oil Drop ExperimentDocument6 pagesMillikan Oil Drop ExperimentruleevanNo ratings yet
- Bob Coecke - Quantum Information-Flow, Concretely, AbstractlyDocument17 pagesBob Coecke - Quantum Information-Flow, Concretely, AbstractlyGholsasNo ratings yet
- Partial Differential Equations Assignment #1 SolutionsDocument3 pagesPartial Differential Equations Assignment #1 SolutionsabysmeNo ratings yet
- ElectromagnetismDocument89 pagesElectromagnetismTeh Boon SiangNo ratings yet
- Choudhary) - Metric SpacesDocument28 pagesChoudhary) - Metric SpacesKhmer ChamNo ratings yet
- Hydrogen AtomDocument8 pagesHydrogen AtomElyasse B.No ratings yet
- The Hall Effect Experiment ExplainedDocument10 pagesThe Hall Effect Experiment ExplainedNidaul Muiz Aufa100% (1)
- PDE DiscretizationDocument13 pagesPDE DiscretizationMostafa MangalNo ratings yet
- Lorentz Invariant 3vectorsDocument6 pagesLorentz Invariant 3vectorskrebilasNo ratings yet
- Handout 9 PDFDocument79 pagesHandout 9 PDFGabriel J. González CáceresNo ratings yet
- Generalised Linear Models and Bayesian StatisticsDocument35 pagesGeneralised Linear Models and Bayesian StatisticsClare WalkerNo ratings yet
- Calculating Wavelength of Light Using Single Slit DiffractionDocument30 pagesCalculating Wavelength of Light Using Single Slit DiffractionRajneilNo ratings yet
- Finite Element Maxwell's EquationsDocument6 pagesFinite Element Maxwell's EquationsHFdzAlNo ratings yet
- Constructing Numbers in Quantum GravityDocument11 pagesConstructing Numbers in Quantum GravityKlee IrwinNo ratings yet
- (Catherine Q. Howe, Dale Purves) Perceiving Geomet (B-Ok - Xyz)Document126 pages(Catherine Q. Howe, Dale Purves) Perceiving Geomet (B-Ok - Xyz)lover.foreverNo ratings yet
- 183 - PR 23 - Foucault Pendulum AnalysisDocument2 pages183 - PR 23 - Foucault Pendulum AnalysisBradley NartowtNo ratings yet
- Minimal of ?-Open Sets and ?-Closed SetsDocument5 pagesMinimal of ?-Open Sets and ?-Closed SetsIAEME PublicationNo ratings yet
- Java Debugging with Visual Studio CodeDocument5 pagesJava Debugging with Visual Studio CodebmwliNo ratings yet
- Java Debugging with Eclipse IDEDocument4 pagesJava Debugging with Eclipse IDEbmwliNo ratings yet
- Lab 3 - Bài thực hành NMLTDocument5 pagesLab 3 - Bài thực hành NMLTbmwliNo ratings yet
- 04 Layout - LinearLayoutDocument33 pages04 Layout - LinearLayoutbmwliNo ratings yet
- 03 DebuggingDocument10 pages03 DebuggingbmwliNo ratings yet
- 04 Layout - LinearLayoutDocument33 pages04 Layout - LinearLayoutbmwliNo ratings yet
- 02 Flower AppDocument24 pages02 Flower AppbmwliNo ratings yet
- 02 Flower AppDocument24 pages02 Flower AppbmwliNo ratings yet
- Face Recognition Based On SVM and 2DPCADocument10 pagesFace Recognition Based On SVM and 2DPCAbmwliNo ratings yet
- 03 DebuggingDocument10 pages03 DebuggingbmwliNo ratings yet
- Gabor FilterDocument23 pagesGabor Filtervitcon1909No ratings yet
- A. R. Mitchell - D. F. Griffiths - The Finite Difference Method in Partial Differential Equations-John Wiley & Sons Incorporated (1980)Document296 pagesA. R. Mitchell - D. F. Griffiths - The Finite Difference Method in Partial Differential Equations-John Wiley & Sons Incorporated (1980)Eisten Daniel Neto Bomba100% (1)
- Answer Key: Grade: IX Total Marks: 15 Subject: Mathematics Duration: 30 Minutes BhopalDocument5 pagesAnswer Key: Grade: IX Total Marks: 15 Subject: Mathematics Duration: 30 Minutes BhopalrahulNo ratings yet
- R23 SyllabusDocument65 pagesR23 SyllabusMUKESH KUMARNo ratings yet
- Wu-Ki Tung - Group Theory in Physics-World Scientific (1985)Document364 pagesWu-Ki Tung - Group Theory in Physics-World Scientific (1985)Natalia Elena SolísNo ratings yet
- Linear Algebra Stress AnalysisDocument5 pagesLinear Algebra Stress Analysistemestruc71No ratings yet
- 26 - The Variational Method PDFDocument7 pages26 - The Variational Method PDFUltrazordNo ratings yet
- LecturePlan AE201 22SMT-121Document9 pagesLecturePlan AE201 22SMT-121FghjNo ratings yet
- 18MAT11 Course ModuleDocument3 pages18MAT11 Course ModuleEER, BC-DHAKANo ratings yet
- An application of eigenvalue methods to identify structural domainsDocument6 pagesAn application of eigenvalue methods to identify structural domainsFlávia Braga100% (1)
- Rayleigh Ritz MethodDocument7 pagesRayleigh Ritz MethodRoshni TNo ratings yet
- Limits Continuity and Differentiability GATE Study Material in PDFDocument9 pagesLimits Continuity and Differentiability GATE Study Material in PDFkavinkumareceNo ratings yet
- Simulating quantum devices with MATLAB modelsDocument4 pagesSimulating quantum devices with MATLAB modelsReally SexyNo ratings yet
- R18 SyllabusDocument121 pagesR18 SyllabusSapa Moulali SkNo ratings yet
- A Answers To Exercises: Section 1.4Document8 pagesA Answers To Exercises: Section 1.4Bonaventure NzeyimanaNo ratings yet
- Perturbation Methods PDFDocument173 pagesPerturbation Methods PDFMark Fernando100% (1)
- Computer Network Assignment HelpDocument11 pagesComputer Network Assignment HelpComputer Network Assignment Help100% (1)
- Vdoc - Pub Nonlinear Pdes A Dynamical Systems ApproachDocument593 pagesVdoc - Pub Nonlinear Pdes A Dynamical Systems ApproachAidan Holwerda100% (2)
- Instrumentation Engineering - GATE 2011 ExplanationsDocument17 pagesInstrumentation Engineering - GATE 2011 Explanationsshaswata7263No ratings yet
- GMT ManpagesDocument263 pagesGMT ManpagesOks OkiNo ratings yet
- Q Miii NotesDocument63 pagesQ Miii NotesJumar CadondonNo ratings yet
- 15MA101 Calculus and Solid GeometryDocument2 pages15MA101 Calculus and Solid GeometryAravind Chandar BNo ratings yet
- Matlab Lmi Lab LMI: Linear Matrix InequalityDocument27 pagesMatlab Lmi Lab LMI: Linear Matrix InequalityAntonio Soto UgaldiNo ratings yet
- Dorf App GDF GeDocument10 pagesDorf App GDF GerafaelkiNo ratings yet
- MIMO Channels and Space-Time Coding: OutlineDocument68 pagesMIMO Channels and Space-Time Coding: Outlinesaeedfirstman66No ratings yet
- Petroleum EnggDocument102 pagesPetroleum EnggHameed Bin AhmadNo ratings yet
- Probability of getting assigned seat as last passengerDocument10 pagesProbability of getting assigned seat as last passengerKhang TranNo ratings yet
- Introduction To Pseudopotential MethodDocument7 pagesIntroduction To Pseudopotential Methodxabi EriceNo ratings yet
- Diagonalization: Linear AlgebraDocument3 pagesDiagonalization: Linear AlgebraLohit KNo ratings yet
- Quantum Fast-Forwarding Accelerates Random Walk Graph Property TestingDocument32 pagesQuantum Fast-Forwarding Accelerates Random Walk Graph Property TestingTrong DuongNo ratings yet
- GATE Mathematics Questions All Branch by S K MondalDocument192 pagesGATE Mathematics Questions All Branch by S K Mondalmyidprince96% (23)