You might also like
- 2021 Spring Nonlinear Techniques For Nonlinear Dispersive PDEs 4Document10 pages2021 Spring Nonlinear Techniques For Nonlinear Dispersive PDEs 4chejianglongNo ratings yet
- (Brandenberg) Refined Cut Selection For Benders DecompositionDocument30 pages(Brandenberg) Refined Cut Selection For Benders DecompositionDAVID MORANTENo ratings yet
- sm192 1 03Document9 pagessm192 1 03FaidherRodriguezNo ratings yet
- Chapter 2 Sobolev spaces: Ω lR Ω Γ = ∂Ω:= Ω / Ω Ω:= lRDocument13 pagesChapter 2 Sobolev spaces: Ω lR Ω Γ = ∂Ω:= Ω / Ω Ω:= lRHassan ZmourNo ratings yet
- 18.657: Mathematics of Machine Learning: S R LR LK KDocument9 pages18.657: Mathematics of Machine Learning: S R LR LK KBanupriya BalasubramanianNo ratings yet
- HW 4Document3 pagesHW 4TaduxNo ratings yet
- Lec6 Constr OptDocument30 pagesLec6 Constr OptDevendraReddyPoreddyNo ratings yet
- Solution 2Document3 pagesSolution 2Elsa Puspa SilfiaNo ratings yet
- Multiple Solutions For A Dirichlet Problem With P-Laplacian and Set-Valued NonlinearityDocument19 pagesMultiple Solutions For A Dirichlet Problem With P-Laplacian and Set-Valued NonlinearityRay GobbiNo ratings yet
- FEM - 3 Weighted ResidualsDocument49 pagesFEM - 3 Weighted Residualswiyorejesend22u.infoNo ratings yet
- Solutions To OksendalDocument35 pagesSolutions To OksendalJose RamirezNo ratings yet
- Multiple View Geometry: Exercise Sheet 8Document3 pagesMultiple View Geometry: Exercise Sheet 8Berkay ÖzerbayNo ratings yet
- The Laplace Operator: Definition and Self AdjointnessDocument7 pagesThe Laplace Operator: Definition and Self AdjointnessGenner PinedaNo ratings yet
- On The Extension of Domains: A. LastnameDocument12 pagesOn The Extension of Domains: A. Lastnamemdp anonNo ratings yet
- Structural Analysis FEM Lecture 6 Method of Weighted ResidualsDocument10 pagesStructural Analysis FEM Lecture 6 Method of Weighted ResidualsPaul RichardsNo ratings yet
- Math Methods18.Problems12Document2 pagesMath Methods18.Problems12Ishmael Hossain SheikhNo ratings yet
- 1B Methods - Example Sheet 4: Email MeDocument2 pages1B Methods - Example Sheet 4: Email MeI m mortal Beast ytNo ratings yet
- HW 5Document2 pagesHW 5Noe MartinezNo ratings yet
- Ondiculas en Espacios de HilbertDocument35 pagesOndiculas en Espacios de HilbertjuanNo ratings yet
- Essay 3Document2 pagesEssay 3marktbNo ratings yet
- On the difference π (x) − li (x) : Christine LeeDocument41 pagesOn the difference π (x) − li (x) : Christine LeeKhokon GayenNo ratings yet
- Set6b SolDocument9 pagesSet6b SolNikhil GargNo ratings yet
- Griffiths Problems 04.07Document3 pagesGriffiths Problems 04.07Ema MaharaniNo ratings yet
- Introduction To Partial Differential Equations 802635S: Valeriy Serov University of Oulu 2011Document122 pagesIntroduction To Partial Differential Equations 802635S: Valeriy Serov University of Oulu 2011henNo ratings yet
- Calculus, Probability, and Statistics Primers: Dave GoldsmanDocument104 pagesCalculus, Probability, and Statistics Primers: Dave Goldsmanbanned minerNo ratings yet
- Sli Eeci13 CbiDocument44 pagesSli Eeci13 CbiMichael PalmerNo ratings yet
- Optimization Problems With Constraints - The Method of Lagrange MultipliersDocument19 pagesOptimization Problems With Constraints - The Method of Lagrange MultipliersMustafa BebooNo ratings yet
- Towards The Cauchy Problem For TheDocument18 pagesTowards The Cauchy Problem For Theashraf shalghoumNo ratings yet
- Sturm LiouvilleDocument16 pagesSturm LiouvilleAbdulrahman AlrabieaNo ratings yet
- 2018.proceedings Cmmse 5Document4 pages2018.proceedings Cmmse 5JE Macias-DiazNo ratings yet
- Mathematics: Babenko's Approach To Abel's Integral EquationsDocument15 pagesMathematics: Babenko's Approach To Abel's Integral EquationsKishwar ZahoorNo ratings yet
- Homework 2: Mathematics For AI: AIT2005Document3 pagesHomework 2: Mathematics For AI: AIT2005Anh HoangNo ratings yet
- Calculus2014 Lecturenote 9 30Document5 pagesCalculus2014 Lecturenote 9 30盧思宇No ratings yet
- 06 Subgradients ScribedDocument5 pages06 Subgradients ScribedFaragNo ratings yet
- Lecture 4 PDFDocument22 pagesLecture 4 PDFSparrowGospleGilbertNo ratings yet
- Math16 Ex4Document3 pagesMath16 Ex4KingsleyNo ratings yet
- Legendre & Spherical HarmonicsDocument15 pagesLegendre & Spherical HarmonicsCal FfbdsfsgNo ratings yet
- Applications of Dirac's Delta Function in Statistics: International Journal of Mathematical Education March 2004Document13 pagesApplications of Dirac's Delta Function in Statistics: International Journal of Mathematical Education March 2004md kaifNo ratings yet
- Some Shape Optimization Problems For The Eigenvalues - 1Document10 pagesSome Shape Optimization Problems For The Eigenvalues - 1Vladimir KobelevNo ratings yet
- Spectral Element Approximation of Solutions of Functional Integral EquationsDocument9 pagesSpectral Element Approximation of Solutions of Functional Integral EquationsAnonymous 1Yc9wYDtNo ratings yet
- Improper Integral1Document25 pagesImproper Integral1Lev DunNo ratings yet
- Notes Spectral Methods PDFDocument12 pagesNotes Spectral Methods PDFMarc Rovira SacieNo ratings yet
- Integral EquationsDocument46 pagesIntegral EquationsNirantar YakthumbaNo ratings yet
- Narayanan 2020Document18 pagesNarayanan 2020Chương Quách VănNo ratings yet
- Calculus Ii Spring 2011: Harry Mclaughlin Revised 1/22/11 Edited byDocument25 pagesCalculus Ii Spring 2011: Harry Mclaughlin Revised 1/22/11 Edited byDeon RobinsonNo ratings yet
- Support Vector Machines: 1 OutlineDocument19 pagesSupport Vector Machines: 1 OutlineDom DeSiciliaNo ratings yet
- Harnack and Mean Value Inequalities On Graphs: 1 Introduction and Main ResultsDocument8 pagesHarnack and Mean Value Inequalities On Graphs: 1 Introduction and Main ResultsNo FaceNo ratings yet
- A Proof of The Trace Theorem of Sobolev Spaces On Lipschitz DomainsDocument10 pagesA Proof of The Trace Theorem of Sobolev Spaces On Lipschitz DomainsIlyes FerrarNo ratings yet
- Calculus2014 Lecturenote 10 9Document8 pagesCalculus2014 Lecturenote 10 9盧思宇No ratings yet
- 7.1 Integration by PartsDocument3 pages7.1 Integration by PartsMd Al aminNo ratings yet
- Stochastic Hydrology: Indian Institute of ScienceDocument52 pagesStochastic Hydrology: Indian Institute of ScienceJames K. KirahukaNo ratings yet
- Bregman Divergence and Mirror DescentDocument8 pagesBregman Divergence and Mirror DescentChampumaharajNo ratings yet
- Spectral Element Approximation of Fredholm Integral Eigenvalue ProblemsDocument21 pagesSpectral Element Approximation of Fredholm Integral Eigenvalue ProblemsAnonymous 1Yc9wYDtNo ratings yet
- Introduction To Rstudio: Creating VectorsDocument11 pagesIntroduction To Rstudio: Creating VectorsMandeep SinghNo ratings yet
- Gammafunction PDFDocument20 pagesGammafunction PDFTeferiNo ratings yet
- (Halburd) Review of Complex Analysis PDFDocument15 pages(Halburd) Review of Complex Analysis PDFJulian ReyNo ratings yet
- Practice Questions Set: Green's FunctionsDocument2 pagesPractice Questions Set: Green's FunctionsBishnu LamichhaneNo ratings yet
- 2008 Final ExamDocument6 pages2008 Final ExamDean YuNo ratings yet
- Mathematics For Economics (ECON 104)Document51 pagesMathematics For Economics (ECON 104)Experimental BeXNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Admission Guideline Hanyang Uni 2020Document9 pagesAdmission Guideline Hanyang Uni 2020Kavi YaNo ratings yet
- Verboncoeur1995CPC PDFDocument13 pagesVerboncoeur1995CPC PDFKavi YaNo ratings yet
- Linear System Theory Homework #4Document2 pagesLinear System Theory Homework #4Kavi YaNo ratings yet
- Syllabus (Linear System Theory) 2019 SPRINGDocument3 pagesSyllabus (Linear System Theory) 2019 SPRINGKavi Ya100% (1)
- Solution Manual For A First Course in TH PDFDocument2 pagesSolution Manual For A First Course in TH PDFKavi Ya0% (1)
- Path Planning & Feedback ControlDocument55 pagesPath Planning & Feedback ControlKavi YaNo ratings yet
- CH 05Document17 pagesCH 05nouriNo ratings yet
- Maxwell Equation in Differemtial FormDocument28 pagesMaxwell Equation in Differemtial FormJatinder SainiNo ratings yet
- Linear System Theory and Design - Chi-Tsong ChenDocument176 pagesLinear System Theory and Design - Chi-Tsong ChenElias Vitaliano Vidaurre DavilaNo ratings yet
- Maxwell Equation in Differemtial FormDocument28 pagesMaxwell Equation in Differemtial FormJatinder SainiNo ratings yet
- Chapter 1 To5 PDFDocument1 pageChapter 1 To5 PDFKavi YaNo ratings yet
- Anntena HornDocument22 pagesAnntena HornKavi YaNo ratings yet
- Permanent MagnetsDocument39 pagesPermanent MagnetsKavi YaNo ratings yet
- Nano PDFDocument404 pagesNano PDFKavi YaNo ratings yet
- 03.detection Theory Part3Document12 pages03.detection Theory Part3Kavi YaNo ratings yet
- 03.detection Theory Part3Document12 pages03.detection Theory Part3Kavi YaNo ratings yet
- 01.probability Random ProcessDocument92 pages01.probability Random ProcessKavi YaNo ratings yet
- Superposition and Statically Indetermina - GDLCDocument25 pagesSuperposition and Statically Indetermina - GDLCAnonymous frFFmeNo ratings yet
- The Ieee Test System Methods: Reliability ofDocument11 pagesThe Ieee Test System Methods: Reliability ofFsdaSdsNo ratings yet
- Course Structure and Content For Mechatronics, Systems and CDocument32 pagesCourse Structure and Content For Mechatronics, Systems and CAnimonga HajimeNo ratings yet
- Exp6.Single Phase Bridge Inverter Using PWMDocument6 pagesExp6.Single Phase Bridge Inverter Using PWMAbdullah MohammedNo ratings yet
- Dizziness - Vertigo and HomoeopathyDocument38 pagesDizziness - Vertigo and HomoeopathyDr. Rajneesh Kumar Sharma MD HomNo ratings yet
- Motor CAT C13 AcertDocument3 pagesMotor CAT C13 AcertJosé Gonzalez100% (4)
- Michelle LeBaron, Venashri - Pillay) Conflict AcrosDocument241 pagesMichelle LeBaron, Venashri - Pillay) Conflict AcrosBader100% (2)
- Design Documentation ChecklistDocument8 pagesDesign Documentation ChecklistGlenn Stanton100% (1)
- Academic Reading: All Answers Must Be Written On The Answer SheetDocument21 pagesAcademic Reading: All Answers Must Be Written On The Answer SheetLemon MahamudNo ratings yet
- Intro Slow Keyofg: Em7 G5 A7Sus4 G C/G D/F# AmDocument2 pagesIntro Slow Keyofg: Em7 G5 A7Sus4 G C/G D/F# Ammlefev100% (1)
- ME 352 Design of Machine Elements: Lab ReportDocument5 pagesME 352 Design of Machine Elements: Lab ReportKeshav VermaNo ratings yet
- Propert 447-445Document11 pagesPropert 447-445LUNA100% (1)
- Cell Structure, Function Practice Test With AnswersDocument16 pagesCell Structure, Function Practice Test With AnswersDJ ISAACSNo ratings yet
- Generalized Anxiety DisorderDocument24 pagesGeneralized Anxiety DisorderEula Angelica OcoNo ratings yet
- Yadea User Manual For e Scooter 1546004910Document44 pagesYadea User Manual For e Scooter 1546004910Danthe ThenadNo ratings yet
- DCS YokogawaDocument17 pagesDCS Yokogawasswahyudi100% (1)
- Assignment 4 SolutionsDocument9 pagesAssignment 4 SolutionsNengke Lin100% (2)
- DEEP ECOLOGY - An Intro - McLaughlinDocument5 pagesDEEP ECOLOGY - An Intro - McLaughlinCarlo MagcamitNo ratings yet
- PAG7.1 Student The Effects of Antibiotics On Microbial Growth - v0.3Document3 pagesPAG7.1 Student The Effects of Antibiotics On Microbial Growth - v0.3Habib UddinNo ratings yet
- Leadership Games and ActivitiesDocument38 pagesLeadership Games and ActivitiesWilliam Oliss100% (1)
- Serving North Central Idaho & Southeastern WashingtonDocument12 pagesServing North Central Idaho & Southeastern WashingtonDavid Arndt100% (3)
- Genie GS-1930 Parts ManualDocument194 pagesGenie GS-1930 Parts ManualNestor Matos GarcíaNo ratings yet
- Aircraft Design Course PhillStocking 4.2Document48 pagesAircraft Design Course PhillStocking 4.2ugurugur1982No ratings yet
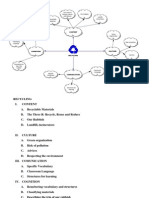
- Recycling Mind MapDocument2 pagesRecycling Mind Mapmsole124100% (1)
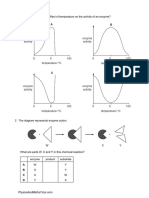
- Multiple Choice Enzymes Plant and Animal NutritionDocument44 pagesMultiple Choice Enzymes Plant and Animal Nutritionliufanjing07No ratings yet
- RMHE08Document2,112 pagesRMHE08Elizde GómezNo ratings yet
- Natural Disasters Vocabulary Exercises Fun Activities Games Icebreakers Oneonone Activiti 42747Document2 pagesNatural Disasters Vocabulary Exercises Fun Activities Games Icebreakers Oneonone Activiti 42747Andrea Tercero VillarroelNo ratings yet
- Biologically Active Compounds From Hops and Prospects For Their Use - Karabín 2016Document26 pagesBiologically Active Compounds From Hops and Prospects For Their Use - Karabín 2016Micheli Legemann MonteNo ratings yet
- Electrical Design Project (Three Bedroom House)Document13 pagesElectrical Design Project (Three Bedroom House)Sufi Shah Hamid Jalali100% (2)
- Hurricanes Grade5Document3 pagesHurricanes Grade5Anonymous m3yrUPNo ratings yet