You might also like
- Heart Disease Prediction Using Machine LearningDocument7 pagesHeart Disease Prediction Using Machine LearningIJRASETPublications100% (1)
- Software Development Framework For Cardiac Disease Prediction Using Machine Learning ApplicationsDocument10 pagesSoftware Development Framework For Cardiac Disease Prediction Using Machine Learning ApplicationsKishore Kanna Ravi Kumar100% (1)
- Forecasting of Stock Prices Using Multi Layer PerceptronDocument6 pagesForecasting of Stock Prices Using Multi Layer Perceptronijbui iir100% (1)
- Statistics For Data ScienceDocument6 pagesStatistics For Data ScienceAnubhav Chaturvedi100% (1)
- Lead Scoring Group Case Study PresentationDocument19 pagesLead Scoring Group Case Study PresentationSantosh Arakeri100% (1)
- Heart Disease Prediction ModelDocument6 pagesHeart Disease Prediction ModelIJRASETPublications100% (1)
- Logistic Regression Model Study AssignmentDocument5 pagesLogistic Regression Model Study AssignmentNathan Mustafa100% (1)
- Sajjad DSDocument97 pagesSajjad DSHey Buddy100% (1)
- Breast Cancer ClassificationDocument16 pagesBreast Cancer ClassificationTester100% (1)
- Machine Learning in Python Main Developments and TDocument44 pagesMachine Learning in Python Main Developments and Tmuhammad syaukani100% (1)
- Stock Market ForecastingDocument7 pagesStock Market ForecastingIJRASETPublications100% (1)
- EDA Lecture Module 2Document42 pagesEDA Lecture Module 2WINORLOSE100% (1)
- Python Intro to Data AnalysisDocument34 pagesPython Intro to Data AnalysisGargi Jana100% (1)
- Intro to Statistics: An Overview of Data Types, Variables & Levels of MeasurementDocument46 pagesIntro to Statistics: An Overview of Data Types, Variables & Levels of MeasurementSagar Bhardwaj100% (1)
- Human Life Span Prediction Using Machine LearningDocument9 pagesHuman Life Span Prediction Using Machine LearningIJRASETPublications100% (1)
- Approaching ML ProblemsDocument300 pagesApproaching ML ProblemsIkram Laaroussi100% (1)
- Car Price Prediction Using Various AlgorithmsDocument19 pagesCar Price Prediction Using Various AlgorithmsNAVIN CHACKO100% (1)
- Week 1 Analytics in PracticeDocument12 pagesWeek 1 Analytics in Practicepalacpac jefferson100% (1)
- Linear Regression Chap01Document7 pagesLinear Regression Chap01israel14548100% (1)
- Blank: CFC Cumulative Forecast Error or Bias ErrorDocument2 pagesBlank: CFC Cumulative Forecast Error or Bias ErrorAbhi Abhi100% (1)
- Statistical Methods for Decision MakingDocument48 pagesStatistical Methods for Decision MakingTasneem Farooque100% (1)
- Life Expectancy Using Data AnalyticsDocument9 pagesLife Expectancy Using Data AnalyticsIJRASETPublications100% (1)
- Statistical Foundations - Intro 64zlfDocument86 pagesStatistical Foundations - Intro 64zlfmanda sridhar100% (1)
- ML AssignmentDocument3 pagesML AssignmentKikuvi John100% (1)
- Classification with Decision Trees: Choosing the Best Splitting AttributeDocument62 pagesClassification with Decision Trees: Choosing the Best Splitting Attributemalik_genius100% (1)
- Chapter 1. IntroductionDocument39 pagesChapter 1. IntroductionNasrima D. Macaraya100% (1)
- Day 5 Supervised Technique-Decision Tree For Classification PDFDocument58 pagesDay 5 Supervised Technique-Decision Tree For Classification PDFamrita cse100% (1)
- Stock Price Prediction Using Transfer Learning TechniquesDocument6 pagesStock Price Prediction Using Transfer Learning TechniquesIJRASETPublications100% (1)
- Stats For Managers - IntroDocument101 pagesStats For Managers - IntroAnandita Sharma100% (1)
- Concepts and Techniques: Data MiningDocument81 pagesConcepts and Techniques: Data Miningnayanisateesh2805100% (1)
- KPMG DataDocument3,723 pagesKPMG DataEdu Platform50% (2)
- Case Study 2Document12 pagesCase Study 2WiSeVirGo100% (1)
- Sas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesDocument16 pagesSas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesNISHITA MALPANI100% (1)
- Introduction To Basics of Machine Learning Algorithms: Pankaj OliDocument13 pagesIntroduction To Basics of Machine Learning Algorithms: Pankaj OliPankaj Oli100% (1)
- 4 SolvedDocument14 pages4 SolvedKinza ALvi100% (1)
- Taller Practica ChurnDocument6 pagesTaller Practica ChurnLuis Medina50% (2)
- H-311 Linear Regression Analysis With RDocument71 pagesH-311 Linear Regression Analysis With RNat Boltu100% (1)
- Data AnalyticsDocument99 pagesData Analyticscmukherjee100% (1)
- Mcdonald Project: - by Kanaga Durga VDocument26 pagesMcdonald Project: - by Kanaga Durga Vgayathri v100% (1)
- EFFIE 2002 Case StudiesDocument16 pagesEFFIE 2002 Case Studies9986212378100% (1)
- Week 1 Introduction To MLDocument42 pagesWeek 1 Introduction To MLJaurel Kouam100% (1)
- Python Vs R in Data and Machine Learning PDFDocument6 pagesPython Vs R in Data and Machine Learning PDFjagadish100% (1)
- Car Price Prediction Using Machine LearningDocument15 pagesCar Price Prediction Using Machine LearningShania Jone100% (1)
- OLS Regression Commands in RDocument38 pagesOLS Regression Commands in Rdeepak100% (1)
- Supply Chain Analytics InsightsDocument42 pagesSupply Chain Analytics InsightsRandy Lagdaan100% (1)
- ML ProjectDocument57 pagesML ProjectPranav Viswanathan100% (1)
- Silver Oal College Of Engineering And Technology Basics of Feature EngineeringDocument33 pagesSilver Oal College Of Engineering And Technology Basics of Feature EngineeringKalash Shah100% (1)
- Decision TreeDocument14 pagesDecision TreeEsha Nawaz100% (1)
- January 1, 1983 1990 5 July 1994 1930 1960Document13 pagesJanuary 1, 1983 1990 5 July 1994 1930 1960MoonRider /MoonFanG.100% (1)
- Community Medicine Trans - Epidemic Investigation 2Document10 pagesCommunity Medicine Trans - Epidemic Investigation 2Kaye Nee100% (1)
- Brain Disease Detection Using Machine LearningDocument7 pagesBrain Disease Detection Using Machine LearningIJRASETPublications100% (1)
- Informatics Practices: Numpy - ArrayDocument28 pagesInformatics Practices: Numpy - ArrayAmit Kumar100% (1)
- CPE412 Pattern Recognition (Week 8)Document25 pagesCPE412 Pattern Recognition (Week 8)Basil Albattah100% (1)
- Python For Finance - The Complete Beginner's Guide - by Behic Guven - Jul, 2020 - Towards Data Science PDFDocument12 pagesPython For Finance - The Complete Beginner's Guide - by Behic Guven - Jul, 2020 - Towards Data Science PDFEconometrista Iel Emecep100% (1)
- 8multiple Linear RegressionDocument21 pages8multiple Linear RegressionAlexis Aedelbert D. Raguini100% (1)
- Arrays in PythonDocument32 pagesArrays in Pythoneimaan afroz100% (1)
- Lung Disease Prediction Using K-Means and Naive BayesDocument35 pagesLung Disease Prediction Using K-Means and Naive BayesMohammad FarhanNo ratings yet
- Pt4 Project Report UpdateddDocument47 pagesPt4 Project Report Updateddakshatguptaec20.rvitmNo ratings yet
- A Project ReportDocument59 pagesA Project ReportRishav RajNo ratings yet
- JqueryDocument19 pagesJqueryLakshmi Vijayasimha Sarma Kaipa100% (1)
- Lung Disease Prediction Using K-Means and Naive BayesDocument35 pagesLung Disease Prediction Using K-Means and Naive BayesMohammad FarhanNo ratings yet
- BootstrapDocument24 pagesBootstrapLakshmi Vijayasimha Sarma Kaipa67% (3)
- Lung Disease Prediction Using K-Means & Naive BayesDocument5 pagesLung Disease Prediction Using K-Means & Naive BayesMohammad FarhanNo ratings yet
- 1) What Is Python? What Are The Benefits of Using Python?Document28 pages1) What Is Python? What Are The Benefits of Using Python?Mohammad FarhanNo ratings yet
- 1) What Is Python? What Are The Benefits of Using Python?Document28 pages1) What Is Python? What Are The Benefits of Using Python?Mohammad FarhanNo ratings yet
- PythonDocument12 pagesPythonMohammad FarhanNo ratings yet
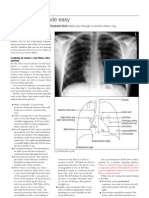
- Cara Membaca Foto Thoraks Yang BaikDocument2 pagesCara Membaca Foto Thoraks Yang BaikIdi Nagan RayaNo ratings yet
- Monaco Treatment Planning Enhances Departmental EfficienciesDocument9 pagesMonaco Treatment Planning Enhances Departmental Efficienciesricky rdnNo ratings yet
- Case Summary For BurialDocument22 pagesCase Summary For Burialzxaii VIINo ratings yet
- Cancer of The Ovary PDFDocument12 pagesCancer of The Ovary PDFDiego Fernando Alzate GomezNo ratings yet
- Bank Pharmacology and Clinical Pharmacy ENGDocument99 pagesBank Pharmacology and Clinical Pharmacy ENGSh A NiNo ratings yet
- REFLEX Final ReportDocument291 pagesREFLEX Final ReportDisicienciaNo ratings yet
- 85 Linearny Urychlovac Clinac IxDocument12 pages85 Linearny Urychlovac Clinac IxTài NguyễnNo ratings yet
- Nclex TipsDocument93 pagesNclex TipsJohn Ernest Varilla86% (7)
- Miso Soup For GERDDocument7 pagesMiso Soup For GERDRippie RifdahNo ratings yet
- Components of Breast MilkDocument2 pagesComponents of Breast MilkAlya Putri KhairaniNo ratings yet
- MIND DietDocument21 pagesMIND DietFrank Lavilla100% (3)
- Fibrous Dysplasia Bone ConditionDocument19 pagesFibrous Dysplasia Bone ConditionNurul RamadaniNo ratings yet
- Fluids P GNTDocument32 pagesFluids P GNTJacinth Florido FedelinNo ratings yet
- Breve Historia Da RadiologiaDocument8 pagesBreve Historia Da RadiologiadridepmatNo ratings yet
- Obstetric Nursing RevisedDocument345 pagesObstetric Nursing Revisedkarendelarosa06100% (1)
- Role of Adjuvant (Chemo) Radiotherapy in Oral Oncology in Contemporary EraDocument9 pagesRole of Adjuvant (Chemo) Radiotherapy in Oral Oncology in Contemporary ErajayeshEPGPNo ratings yet
- Theories of the Aging ProcessDocument110 pagesTheories of the Aging ProcessVhandy Ramadhan100% (3)
- Wound Care - HandoutDocument8 pagesWound Care - HandoutAryanto HabibieNo ratings yet
- New York Health Welcomes Jay B. Adlersberg, M.D.Document2 pagesNew York Health Welcomes Jay B. Adlersberg, M.D.PR.comNo ratings yet
- OSHA's Asbestos Standard For The Construction IndustryDocument80 pagesOSHA's Asbestos Standard For The Construction IndustrySuhaib SghaireenNo ratings yet
- Nclex Exam PrepDocument26 pagesNclex Exam PrepPascal St Peter Nwaorgu100% (1)
- Assignment Cover Page - PathophysiologyDocument6 pagesAssignment Cover Page - PathophysiologyAnonymous HcjWDGDnNo ratings yet
- Prostate CancerDocument34 pagesProstate CancerKoRnflakes100% (1)
- About Cervical Cancer: Overview and TypesDocument9 pagesAbout Cervical Cancer: Overview and TypesAlexa jaye BalinoNo ratings yet
- Toxicological Profiles AmmoniaDocument248 pagesToxicological Profiles AmmoniaHugh MantaNo ratings yet
- Nurses Practice in LeukemiaDocument8 pagesNurses Practice in LeukemiaConstantinNo ratings yet
- NutrigeneticaDocument12 pagesNutrigeneticaCiocirlan CameliaNo ratings yet
- Fibro PathwayDocument2 pagesFibro Pathwayapi-163168129No ratings yet
- Diarrhea & Constipation GuideDocument100 pagesDiarrhea & Constipation GuidePanee KowNo ratings yet
- Checklist For Breast ExamDocument5 pagesChecklist For Breast ExamKaira Denise BilaloNo ratings yet