Professional Documents
Culture Documents
T.P. 8 - Exercice 1 Khi-Carre Dajustement
Uploaded by
AbdenourBelagrouzOriginal Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
T.P. 8 - Exercice 1 Khi-Carre Dajustement
Uploaded by
AbdenourBelagrouzCopyright:
Available Formats
T.P.
8 - Exercice 1
Khi-Carré d’ajustement (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Test χ 2 d’ajustement.
Table de distribution des χ .
2
Outils nécessaires :
Consignes générales : Les vacances de Pâques approchent… c’est l’occasion de revoir tous les TP en
travaillant en parallèle avec votre cours théorique.
Attention : les exercices supplémentaires font partie de la matière d’examen.
Voir cours théorique, chapitre 5.
Rappel :
Un test couramment utilisé en inférence statistique est le test khi-carré ( χ 2 ). Il est utilisé
lorsqu’on s’intéresse à des données qui se mesurent sur des échelles nominales (variables
catégorielles). À ce TP, nous allons examiner deux tests χ 2 distincts : le test χ 2
d’ajustement et le test χ 2 d’indépendance.
Le test χ 2 d’ajustement compare la distribution de fréquences d’un échantillon (fréquences
relatives ou fréquences absolues) par rapport à la distribution de fréquences attendues
(théoriques). Il permet donc d’évaluer dans quelle mesure les données que vous obtenez dans
votre échantillon lors d’une expérience sont bien ajustées aux données théoriques attendues.
Il est utilisé lorsque la procédure de mesure (par exemple un test de personnalité) permet de
classer les individus (ou tout autre éléments) en plusieurs catégories (personnalité dépressive,
schizophrène…). La proportion d’individus que vous obtenez dans chaque catégorie de votre
échantillon (vos fréquences observées) est ensuite comparée à la proportion d’individus dans
chaque catégorie qu’on s’attend à observer dans la population toute entière (fréquences
attendues). Soit :
J
( O j − E j )2
χ calculé = ∑
2
j =1 Ej
avec :
Ø Oj = fréquence observée
Ø Ej = fréquence attendue (expected)
En pratique, la première étape consiste à poser une hypothèse nulle ( H 0 ) avant de récolter
ses données. Pour un test khi-carré d’ajustement, cette H 0 est soit une répartition des sujets
au hasard dans chaque catégorie soit une répartition des sujets conforme à une distribution
connue. La seconde étape consiste à calculer la valeur du khi carré sur base de l’échantillon
(khi carré calculé) et d’observer si elle est située dans une zone de rejet ou de non rejet de
l’hypothèse nulle.
Les valeurs que peut prendre la distribution du khi carré dépendent du nombre de degrés de
liberté. Pour le trouver, la formule suivante est utilisée :
D.L. = J-1 où J = le nombre de catégories de la variable
Une fois qu’on a les degrés de liberté et la valeur calculée du khi carré calculé, on cherche
dans la table de distribution khi-carré, une valeur de khi carré théorique à laquelle on la
compare.
TTP 8 - 2006-2007 (Corrigé) 1/23
Si χ calculé < χ théorique
2 2
il y a non rejet de l’hypothèse nulle.
Si χ calculé ≥ χ théorique
2 2
il y a rejet de l’hypothèse nulle.
Dans ce dernie r cas, on considère que la différence est significative avec maximum 5% de
risque de se tromper.
.05 est le seuil habituellement utilisé en psychologie mais il existe d’autres tables plus
conservatrices qui utilisent un risque d’erreur accepté inférieur, comme par exemple .01.
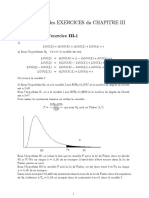
À titre d’exemple, voici une courbe de χ 2 pour 3 degrés de liberté, laissant, sur la droite une
zone de rejet de l’hypothèse nulle (avec une marge d’erreur de 5%) avec comme χ théorique
2
une
valeur de 7,81 (au-delà de laquelle nous sommes de la zone de rejet de l’hypothèse nulle).
Zone de non rejet de
l’hypothèse nulle
(NRH0 )
Zone de rejet de
l’hypothèse nulle
(RH0 )
N.B. : Dans la légende des graphiques que nous vous proposons dans ce T.P. :
• Area = Taille de la zone de rejet (en termes de probabilité d’erreur)
• Low = valeur critique qui délimité la zone de rejet et la zone de non rejet de H0 .
• Df = degrees of freedom (degrés de liberté)
Un chercheur s’intéresse aux boissons préférées dans une population. Il pose la question
suivante à un échantillon de 30 participants : « Préférez-vous boire du thé ou du café ? » Il ne
s’attend pas à observer de préférence pour une de ces 2 boissons.
1. Quelle est l’hypothèse nulle ?
Réponse :
H 0 = pas de préférence entre thé et café.
p = q = .50 (la probabilité de choisir le thé est la même que la probabilité de choisir le
café).
Dans son groupe, 11 personnes préfèrent le thé et 19 le café.
2. Représentez ces données sous la forme d’un tableau indiquant les fréquences absolues
observées et attendues.
thé café total
Fréq. observées (O j) 11 19 30
Fréq. attendues (Ej) 1 15 15 30
1
E pour expected, qui signifie attendue en anglais.
TTP 8 - 2006-2007 (Corrigé) 2/23
La question est de savoir si la différence entre les fréquences observées dans l’échantillon et
les fréquences attendues (sous l’hypothèse nulle) sont dues au hasard ou reflètent une
véritable préférence pour le café dans la population.
3. Quelle est la valeur de χ 2 ?
J
( O j − E j )2
χ 2
calculé =∑
j =1 Ej
(11 − 15) 2 (19 −15) 2
χ2= + = 2,13
15 15
4. Combien y a-t-il de degrés de liberté (D.L.) ?
Réponse :
J-1 degré de liberté où J représente le nombre de catégories (ici thé-café) de la variable
(boisson). Donc 2-1 = 1 (D.L.).
5. Au niveau de signification minimum de .05 et au niveau de D.L. approprié, quelle est la
valeur théorique de χ 2 ? Schématisez votre réponse à l’aide d’un graphique.
Réponse :
À .05 et 1 D.L., la valeur théorique du χ 2 vaut 3,84. Comme la valeur calculée du
χ 2 (2,13) est nettement inférieure à la valeur théorique ; on dit qu’elle est dans la
zone de non rejet de l’hypothèse nulle (NRH0 ) : on ne rejette pas l’hypothèse nulle.
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) 3,84 (RH0 )
6. Que pouvez-vous conclure par rapport aux préférences thé-café ?
Réponse :
On ne rejette pas l’hypothèse nulle qui stipulait l’absence de préférence entre thé et
café. La différence observée dans notre échantillon est donc probablement due au
hasard.
TTP 8 - 2006-2007 (Corrigé) 3/23
T.P. 8 - Exercice 2
Khi-Carré d’ajustement (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Test χ 2 d’ajustement.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
Un chercheur s’intéresse aux facteurs qui déterminent le choix des cours des étudiants. Il pose
la question suivante à un échantillon de 50 étudiants : « Parmi les 4 facteurs suivants, lequel
est le plus important lorsque vous sélectionnez un cours ?». Les étudiants doivent choisir 1
des 4 propositions suivantes :
- l’intérêt pour le contenu du cours ;
- le degré de complexité de l’examen ;
- le professeur ;
- l’heure à laquelle le cours se donne.
Voici les résultats que le chercheur obtient :
Contenu cours Examen Professeur Horaire
O (fréquences
absolues observées)
18 17 7 8
Sur base de ces données, le chercheur peut- il conclure qu’un facteur (ou plusieurs facteurs) est
(sont) plus important(s) que les autres ? Il teste à un niveau de signification .05.
1. Quelle est l’hypothèse nulle ?
Réponse :
H 0 : il n’y a pas de préférence pour un facteur particulier. Les 4 facteurs sont choisis
de façon équivalente.
2. Représentez ces données sous la forme d’un tableau indiquant les fréquences absolues
observées et attendues.
Contenu cours examen professeur horaire
Oj (fréquences 18 17 7 8
absolues observées)
Ej (fréquences 12,5 12,5 12,5 12,5
absolues attendues)
TTP 8 - 2006-2007 (Corrigé) 4/23
3. Quelle est la valeur calculée de χ 2 ?
Réponse :
Valeur calculée de χ 2 = 8,08
4. Quel est le nombre de degrés de liberté ?
Réponse :
D.L. = 3
5. Au niveau de signification .05, quelle est la valeur théorique de χ 2 ?
Réponse :
Valeur théorique de χ 2 = 7,82
6. L’hypothèse nulle est-elle rejetée ? Que concluez-vous ? Schématisez votre réponse à
l’aide d’un graphique.
8,08>7,82
La valeur calculée de χ 2 se situe dans zone de rejet de l’H0 (est supérieure à la
valeur théorique de χ 2 ). Par conséquent l’hypothèse nulle est rejetée. Le
chercheur conclut qu’au moins un des facteurs est choisi préférentiellement par
les étudiants.
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) (RH0 )
7,81
TTP 8 - 2006-2007 (Corrigé) 5/23
T.P. 8 - Exercice 3
Khi-Carré d’ajustement (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Test χ 2 d’ajustement.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
En 1908, en France, Binet publie une étude concernant la mesure de l’intelligence des enfants.
Son échelle d’intelligence se base sur un certain nombre d’épreuves classées dans un ordre
croissant de difficulté. Un niveau d’âge est attribué à chaque épreuve qui correspond au plus
jeune âge auquel un enfant d’intelligence normale réussit l’épreuve. L’enfant commence le
test de Binet par les épreuves de l’âge le plus jeune et poursuit la série d’épreuves jusqu’à ce
qu’il échoue. L’âge associé à ces dernières épreuves devient son âge mental et son niveau
intellectuel général est calculé en soustrayant son âge chronologique à son âge mental. On
peut donc «classer » l’enfant dans une des 5 catégories suivantes : retardé de 2 ans, retardé
d’1 an, régulier, avancé de 1 an et avancé de 2 ans. Voici les données, en fréquences
relatives, que Binet obtient sur un échantillon de 192 enfants :
-2 -1 0 +1 +2
0,06 0,23 0,48 0,22 0,01
Des chercheurs, un américain (Goddard) et un allemand (Bobertag) font passer le test de Binet
(traduit en anglais/allemand et adapté culturellement) à un échantillon de 1547 enfants
américains (Goddard) et 228 enfants allemands (Bobertag). Ils obtiennent les données
suivantes, en fréquences absolues :
-2 -1 0 +1 +2
Goddard 294 309 557 325 62
Bobertag 6 40 119 57 6
Les données obtenues par le chercheur américain et l’allemand reflètent-elles la distribution
obtenue chez les enfants français (niveau de signification .05) ?
1. Enfants américains (données de Goddard)
a) Quelle est l’hypothèse nulle dans cette recherche ?
Réponse :
H 0 : il n’y a pas de différence entre les enfants américains et les enfants français en ce qui
concerne leur répartition dans chaque catégorie d’âge mental.
TTP 8 - 2006-2007 (Corrigé) 6/23
b) Complétez le tableau suivant.
-2 -1 0 +1 +2
Oj 294 309 557 325 62
1547 * 0,06 = 1547 * 0,23 = 1547 * 0,48 = 1547 * 0,22 = 1547 * 0,01 =
Ej
92,82 355,81 742,56 340,34 15,47
c) Déterminez les valeurs de χ calculé , χ théorique
2 2
et les degrés de liberté. Tracez le graphique qui
vous aidera à visualiser l’idée de rejet et de non rejet de l’hypothèse nulle.
Valeur calculée de χ 2 = 629,21
D.L. = 4
Valeur théorique de χ 2 à .05 = 9,49
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) (RH0 )
9,49
d) Que pouvez- vous tirer comme conclusion ?
La valeur calculée de χ 2 se situe dans la zone de rejet et l’hypothèse nulle est donc rejetée.
Les scores au test de Binet ne se distribuent donc pas de la même façon dans la population
américaine que dans la population française.
2. Enfants allemands (données de Bobertag)
a) Quelle est l’hypothèse nulle dans cette recherche ?
H 0 : il n’y a pas de différence entre les enfants allemands et les enfants français en ce qui
concerne leur répartition dans chaque catégorie d’âge mental.
b) Complétez le tableau suivant.
-2 -1 0 +1 +2
Oj 6 40 119 57 6
Ej 13,68 52,44 109,44 50,16 2,28
TTP 8 - 2006-2007 (Corrigé) 7/23
c) Déterminez les valeurs de χ calculé , χ théorique
2 2
et les degrés de liberté.
Valeur calculée de χ 2 = 15,09
D.L. = 4
Valeur théorique de χ 2 à .05 = 9,49
Zone de rejet de
Zone de non rejet de l’hypothèse nulle
l’hypothèse nulle (RH0 )
(NRH0 )
9,49
d) Que pouvez- vous tirer comme conclusion ?
La valeur calculée de χ 2 se situe dans la zone de rejet et l’hypothèse nulle est donc rejetée.
Les scores au test de Binet ne se distribuent pas de la même façon dans la population
allemande que dans la population française.
TTP 8 - 2006-2007 (Corrigé) 8/23
T.P. 8 - Exercice 4
Khi-Carré d’indépendance (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Test χ 2 d’indépendance.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
Le test χ 2 d’indépendance porte sur 2 variables catégorielles et a pour but d’évaluer si ces 2
variables sont indépendantes. L’hypothèse nulle est qu’il y a une parfaite indépendance entre
les 2 variables. La logique de ce test est la même que pour le test χ 2 d’ajustement. On
prélève un échantillon et chaque individu de l’échantillon est évalué sur 2 variables séparées.
L’échantillon de données servira pour tester une hypothèse par rapport à l’indépendance des
2 variables dans la population.
Par exemple, un groupe d’étudiants est classé en termes de personnalité (introvertie,
extravertie) et de groupe sanguin (A, B, AB, 0).
Ces données se notent dans un tableau de contingence des fréquences absolues observées.
Par exemple, pour un échantillon de 47 étudiants, on pourrait avoir le tableau suivant :
A B AB 0 total
introverti 6 7 6 6 25
extraverti 6 2 6 8 22
Total 12 9 12 14 N=47
Ces fréquences observées sont comparées aux fréquences attendues sous l’hypothèse nulle.
Ensuite, on calcule la valeur du χ 2 pour déterminer dans quelle mesure les valeurs observées
s’accordent avec les valeurs attendues et on se sert de la table de distribution de χ 2 pour
conclure à propos de l’indépendance des 2 variables examinées.
Le test χ 2 d’indépendance utilise exactement la même formule que le test χ 2 d’ajustement :
J K (O − E jk )
2
χ =∑ ∑
2 jk
j =1 k =1 E jk
Les fréquences attendues (Ejk ) se calculent sur base des fréquences marginales et de N.
( fréq. colonne × fréq . ligne)
= E jk
N
Les degrés de liberté s’obtiennent par le calcul suivant pour le χ 2 d’indépendance :
D.L. = ( J − 1)( K − 1)
avec :
J= nombre de catégories de la variable A (en ligne)
K = nombre de catégories de la variable B (en colonne)
TTP 8 - 2006-2007 (Corrigé) 9/23
Les conditions d’application du test χ 2 sont :
• N = 30 : c’est bien le cas dans notre exemple N = 40 ;
• tous les Ejk > 0 (c’est aussi le cas) ;
• 80% des Ejk = 5 : 7 cellules sur 8 (soit 87,5 %) possèdent une valeur attendue
supérieure à 5.
Une étude porte sur l’occurrence d’un comportement d’aide à personne en danger en fonction
du nombre d’observateurs. Les sujets sont confrontés à un individu (la victime) qui simule
une crise d’épilepsie. Les expérimentateurs observent si le sujet manifeste un comportement
d’aide à la personne en danger ou pas. La taille du groupe varie : 2 (sujet + « victime »), 3 ou
6 personnes).
Voici les fréquences observées :
2 pers 3 pers 6 pers Total
Aide 11 16 4 31
Non aide 2 10 9 21
Total 13 26 13 N=52
1. Complétez le tableau ci-dessus avec les fréquences marginales absolues.
2. Quelle est l’hypothèse nulle ?
La taille du groupe et le comportement d’aide sont des variables indépendantes dans la
population. Donc l’absence ou la présence d’un comportement d’aide ne devrait pas
varier en fonction du nombre d’observateurs.
3. Calculez les fréquences attendues.
2 pers 3 pers 6 pers total
Aide 7,75 15,5 7,75 31
Non aide 5,25 10,5 5,25 21
total 13 26 13 N = 52
TTP 8 - 2006-2007 (Corrigé) 10/ 23
4. Calculez les degrés de liberté et localisez la région critique pour un seuil de .05.
Représentez la valeur de χ 2 trouvée sur un graphique et indiquez-y les zones de rejet et
de non rejet de l’hypothèse nulle.
D.L. = (2-1)(3-1) = 2
La valeur critique de χ 2 vaut 5,99.
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) (RH0 )
5,99
5. Calculez la valeur du χ calculé .
2
J K (O − E jk )
2
χ =∑ ∑
2 jk
j =1 k =1 E jk
(11 − 7,75) 2 (16 − 15,5) 2 ( 4 − 7,75) 2 ( 2 − 5,25) 2 (10 − 10,5) 2 (9 − 5,25) 2
χ2 = + + + + +
7,75 15,5 7,75 5, 25 10,5 5,25
= 1,363 + 0,016 + 1,815 + 2,012 + 0,024 + 2,679
= 7,91
6. Que pouvez-vous conclure ?
La valeur du χ 2 calculé est supérieure au χ 2 théorique. Il y a donc rejet de l’hypothèse
nulle. On conclut qu’il y a un lien entre comportement d’aide et nombre
d’observateurs.
TTP 8 - 2006-2007 (Corrigé) 11/ 23
T.P. 8 - Exercice supplémentaire 1
Khi-Carré (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Tests χ 2 ; choix du test.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
Un chercheur prétend que la répartition de la population sur les 4 classes de groupe sanguin
est uniforme, en d’autres termes la population se répartit sur les 4 classes de manière
identique.
Sur base des données de la variable « groupe sanguin », pouvez- vous confirmer ou infirmer
cette affirmation ?
Groupe Effectif Effectif Probabilité Effectif (O j-Ej)²/Ej
sanguin relatif attendue attendu
1. A 73 0,40331 0,25 45,25 17,018
2. B 22 0,12155 0,25 45,25 11,946
3. AB 9 0,04972 0,25 45,25 29,04
4. O 77 0,42541 0,25 45,25 22,278
Total 181 1,0000 1,00 181 80,282
1. Complétez le tableau ci-dessus.
2. Déterminez les 3 dernières colonnes du tableau.
Nous souhaitons vérifier si la distribution de la variable groupe sanguin est uniforme, ce qui
revient à dire que les 4 groupes sont équiprobables.
3. Quel test allons-nous utiliser pour vérifier cela ?
Un test χ 2 d’ajustement, puisque nous souhaitons vérifier si la répartition des individus
entre les groupes sanguins est équiprobable.
4. Quelle est l’hypothèse nulle ?
Réponse :
H0 = La variable groupe sanguin est distribuée uniformément sur ses quatre modalités.
TTP 8 - 2006-2007 (Corrigé) 12/ 23
5. Que vaut la statistique de test χ calculé
2
?
Réponse :
Il s’agit de la somme de la dernière colonne du tableau = 80,282.
6. Combien de degrés de liberté compte la loi Khi-carré pour ce test ?
Réponse :
Nombre de modalités de la variable « sang » - 1 = 4 – 1 = 3
7. Si nous fixons le niveau d’erreurs à 5 %, à partir de quelle valeur pourrons-nous rejeter
l’hypothèse que la distribution du groupe sanguin sur la population est uniforme ? Que
faut- il faire pour répondre à cette question ? Représentez graphiquement la zone de rejet et
la zone de non rejet de l’hypothèse nulle.
Réponse :
Pour répondre à cette question, il faut chercher le χ théorique
2
dans la table.
Ainsi, nous trouver qu’à partir de 7,815 nous pourrons rejeter l’hypothèse que la
distribution du groupe sanguin sur la population est uniforme.
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) (RH0 )
7,815
8. Que pouvez-vous conclure ?
Réponse :
La statistique de test ( χ calculé ) valant 80,282 est largement supérieure à 7,815 ( χ théorique
2 2
);
nous pouvons donc très franchement rejeter l’hypothèse que la variable groupe sanguin
est distribuée uniformément avec un risque d’erreur nettement inférieure à 5%.
TTP 8 - 2006-2007 (Corrigé) 13/ 23
T.P. 8 - Exercice supplémentaire 2
Khi-Carré (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Tests χ 2 ; choix du test.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
Nous souhaitons vérifier si la répartition du groupe sanguin entre les 4 classes dépend du sexe
des individus. À cet effet, considérons les 181 données de notre échantillon.
1. Quel test devrons-nous utiliser pour répondre à cette question sur base de notre échantillon
ci-dessous.
Réponse :
Un test χ 2 d’indépendance.
2. Le tableau ci-dessous est le tableau de contingence des deux variables SANG et SEXE
(O jk ). Déterminez les fréquences marginales et indiquez- les dans le tableau.
SEXE
SANG Masculin Féminin Total
A 12 61 73
B 6 16 22
AB 1 8 9
O 25 52 77
Total 44 137 181
TTP 8 - 2006-2007 (Corrigé) 14/ 23
3. Déterminez le tableau des effectifs attendus (Ejk ) s’il y a indépendance entre les deux
variables :
SEXE
SANG Masculin Féminin Total
A 17,746 55,254 73
B 5,348 16,652 22
AB 2,188 6,812 9
O 18,718 58,282 77
Total 44 137 181
4. Déterminez le tableau des carrés des écarts entre les effectifs observés et attendus divisés
par les effectifs attendus ((O jk – Ejk )²/ Ejk ) :
SEXE
SANG Masculin Féminin
(12-17,746)² /
A 0,598
17.746 =1,861
B 0,079 0,026
AB 0,645 0,207
O 2,108 0,677
5. Que vaut la statistique de test χ calculé
2
(mesure de l’écart entre les deux tableaux) :
Réponse :
C’est la somme de toutes les cellules du tableau précédent = 6,201
6. Combien de degrés de liberté compte la loi Khi-carré que nous utilisons ici ?
Réponse :
(nombre de modalités de la variable SANG - 1)x (nombre de modalités de la variable
SEXE – 1) = (4 – 1)(2 – 1) = 3
TTP 8 - 2006-2007 (Corrigé) 15/ 23
7. Si nous fixons le niveau d’erreurs à 5 %, à partir de quelle valeur de χ théorique
2
pourrons- nous
rejeter l’hypothèse que les distributions du groupe sanguin et du sexe sont indépendantes ?
Représentez graphiquement la zone de rejet et la zone de non rejet de l’hypothèse nulle.
Réponse :
À partir de χ théorique
2
= 7,815 nous pourrons rejeter l’hypothèse que les deux variables sont
indépendantes.
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) 7,815 (RH0 )
8. Que pouvez-vous conclure ?
Réponse :
La statistique de test χ calculé valant 6,201, elle est inférieure à χ théorique
2 2
=7,815 ; nous ne
pouvons donc pas rejeter l’hypothèse que les deux variables « groupe sanguin » et
« sexe » sont indépendantes.
Autrement dit, avec une marge d’erreur de 5%, nous pouvons dire que les deux variables
« groupe sanguin » et « sexe » sont indépendantes ou encore, que la répartition de la
population dans les quatre classes de groupes sanguin ne diffère pas suivant le sexe
auquel les individus appartiennent.
9. Les conditions d’application du test Khi-carré sont-elles bien remplies ?
Réponse :
Les conditions d’application du test sont bien remplies en effet :
• N = 30 : c’est bien le cas N =181 ;
• tous les Ejk > 0 (c’est aussi le cas) ;
• 80% des Ejk = 5 : 7 cellules sur 8 (soit 87,5 %) contiennent une valeur attendue
supérieure à 5.
TTP 8 - 2006-2007 (Corrigé) 16/ 23
T.P. 8 - Exercice supplémentaire 3
Khi-Carré (Corrigé)
Connaissances préalables : Distribution de fréquences, proportions.
Buts spécifiques : Tests χ 2 ; choix du test.
Outils nécessaires : Table de distribution des χ2.
Consignes générales :
Nous avons vu au TP 7 que, lors de lancers d’un dé bien équilibré, le nombre de fois que le 6
sortait au cours de 5 lancers successifs suivait une loi binomiale Bi(5;1/6). Pour vérifier que
cette séquence est bien distribuée suivant une loi Bi(5; 1/6), un joueur incrédule décide de
faire 30 séries de 5 lancers successifs et dénomb re pour chaque série le nombre de fois que le
6 est sorti. Il obtient le tableau suivant reprenant le résultat des 30 séries :
1 1 2 1 1 1 0 2 1 0
1 0 0 0 1 2 2 0 1 0
0 0 1 2 1 0 1 1 0 0
Nombre Probabilité
Effectif
de sorties Effectif Effectif relatif attendue [Oj-Ej]²/Ej
attendu
du 6 Bi(5;1/6)
0 12 0,400 0,402 12,056 0,000
1 13 0,433 0,402 12,056 0,074
2 5 0,167 0,161 4,823 0,006
3 0 0,000 0,032 0,965 0,965
4 0 0,000 0,003 0,096 0,096
5 0 0,000 0,000 0,004 0,004
Total 30 1,0000 1,000 30 1,146
1. Complétez le tableau ci-dessus.
2. Que vaut la statistique de test χ calculé
2
?
Réponse :
Il s’agit de la somme de la dernière colonne du tableau = 1,146
TTP 8 - 2006-2007 (Corrigé) 17/ 23
3. Combien de degrés de liberté compte la loi Khi-carré dans ce cas-ci ?
Réponse :
Nombre de modalités de la variable « Nombre de 6 »- 1 = 6 – 1 = 5
4. Si nous fixons le niveau d’erreurs à 5 %, à partir de quelle valeur de χ théorique
2
pourrons- nous
rejeter l’hypothèse que la distribution de la variable « Nombre de sorties du 6 au cours de 5
lancers successifs » suit une loi binomiale Bi(5;1/6) ? Représentez la distribution χ 2 en
indiquant les zones de rejet et de non rejet ainsi qu’en y plaçant (approximativement) les
χ théorique
2
et χ calculé
2
.
Réponse :
Pour les valeurs de χ calculé
2
supérieures à 11,07 nous pourrons rejeter l’hypothèse que la
distribution « nombre de sorties du 6 au cours de 5 lancers successifs » se distribue bien
suivant une loi binomiale Bi(5;1/6).
Zone de non rejet de Zone de rejet de
l’hypothèse nulle l’hypothèse nulle
(NRH0 ) (RH0 )
11,07
6. Que pouvez-vous conclure ?
Réponse :
La statistique de test χ calculé
2
valant 1,146, elle est inférieure à 11,07 ; nous ne pouvons
donc pas rejeter l’hypothèse que la variable « nombre de sorties du 6 au cours de 5
lancers successifs » se distribue bien suivant une loi binomiale Bi(5;1/6). Notre dé ne
semble donc pas pipé.
7. Les conditions d’application du test Khi-carré sont-elles bien remplies ?
Réponse :
Les conditions d’application du test ne sont pas remplies. En effet, les effectifs attendus
(Ei) doivent être supérieurs à 5 or pour X=2, 3, 4 et 5 les effectifs attendus sont inférieurs
à 5.
TTP 8 - 2006-2007 (Corrigé) 18/ 23
T.P. 8 - Exercice supplémentaire 4
Khi-Carré (Corrigé)
Trente sept étudiants d’une promotion ont été répartis, en début d’année académique, de
manière strictement aléatoire dans trois séries de travaux pratiques de statistique dirigés par
trois assistants différents A1, A2 et A3. Les résultats obtenus par les étudiants de chaque série
sont notés sur 10 et regroupés dans le tableau suivant.
Assistant Note des étudiants (sur 10)
A1 9 5,5 6 3 3 2 7 5 0 8 4,5 7
A2 4 3 6 8 2 3 5 7 7 4,5 3,5 0
A3 8 6 4 8 10 4 4,5 5 7 8 10 9 6
Afin d’étudier l’indépendance des résultats par rapport à la série d’appartenance de l’étudiant,
un chercheur fait un décompte en termes de nombre de réussites et d’échecs par série de
travaux pratiques.
1. Quel test devons-nous utiliser?
Réponse :
Un test χ 2 d’indépendance.
2. Quelle est l’hypothèse nulle de notre chercheur ?
Réponse :
H0 = Il y a indépendance entre les résultats et l’appartenance à une série de T.P.
3. Complétez le tableau ci-dessous par les effectifs observés (à partir de 5/10 le résultat est
considéré comme une réussite) :
Série A1 Série A2 Série A3 Total
Echec 5 7 3 15
Réussite 7 5 10 22
Total 12 12 13 37
4. Complétez le tableau de contingence ci-dessous avec les effectifs théoriques attendus sous
l’hypothèse d’indépendance.
Série A1 Série A2 Série A3 Total
Echec 4,865 4,865 5,270 15
Réussite 7,135 7,135 7,730 22
Total 12 12 13 37
TTP 8 - 2006-2007 (Corrigé) 19/ 23
5. Complétez le tableau de mesure des écarts entre le tableau de contingence observé et le
tableau de contingence attendu sous l’hypothèse d’indépendance.
Série A1 Série A2 Série A3
(5-4,865)²
Echec 0,937 0,978
/4,865 =0,004
Réussite 0,003 0,639 0,667
6. Que vaut la statistique de test χ calculé
2
?
Réponse : χ calculé
2
= 3,228
7. Combien de degrés de liberté comporte la distribution Khi-carré de notre exercice ?
Réponse : (2 – 1)(3 – 1) = 2
8. Si le niveau d’erreur auquel nous souhaitons travailler est fixé à 5 %, déterminez la limite
séparant la zone d’acceptation et la zone de rejet de l’hypothèse d’indépendance. Placez
cette valeur sur un graphique ainsi que le χ calculé
2
.
9. Que pouvez-vous conclure ?
Réponse :
χ calculé (= 3,228) < χ théorique (= 5,991). Nous ne rejetons donc pas l’indépendance entre les
2 2
deux variables. La mesure de l’écart entre les deux tableaux de contingence (observé et
attendu) n’est pas suffisamment grande que pour conclure à une différence statistique
significative entre ceux-ci. L’échec (ou la réussite) d’un étudiant est donc indépendant de
la série de travaux pratiques qu’il a suivis.
TTP 8 - 2006-2007 (Corrigé) 20/ 23
T.P. 8 - Exercice supplémentaire 5
Khi-Carré (Corrigé)
Supposons qu’un sondage d’opinion réalisé dans les années ’70 donne les résultats suivants :
15% des sujets sont en faveur de la régularisation de la marijuana, 79% sont contres et 6%
sont sans opinion.
Admettons qu’aujourd’hui, nous prenions un échantillon de 220 personnes et que 38 des
personnes interrogées soient pour, 165 contre et que 17 soient sans opinion.
En acceptant une marge d’erreur de 5%, pourrions- nous dire qu’il y a une différence
significative entre les résultats obtenus dans notre échantillon et celui des années ’70 ?
N.B. : Pour cet exercice, nous ne vous posons pas de questions intermédiaires. Il faut
cependant que votre réponse soit complète.
Réponse :
Pour répondre à la question, nous devons effectuer un test χ 2 d’ajustement.
Pour ce faire, il faut déterminer les fréquences observées aujourd’hui et les fréquences
attendus (c’est-à-dire celles des années ’70). On peut le faire avec les fréquences relatives
ou absolues, mais il faut prendre la même chose pour les 2 et donc ici faire un choix et
tout mettre en pourcentages.
Pour Contre Sans opinion
Années ‘70 15% 79% 6%
Aujourd’hui 17,27% 75% 7,73
Puis, il faut déterminer la valeur du χ calculé
2
:
J (O j − E j ) 2 (17, 27 − 15 )2 (75 − 79)2 (7,73 − 6)2
χ 2
calculé =∑ = + + = 1,04
j =1 Ej 15 79 6
et la comparer à la valeur du χ théorique
2
à .05 et 2 degrés de liberté qui vaut 5,99 :
1,04<5,99
Nous nous situons donc dans la zone de non rejet de l’hypothèse nulle. Nous ne pouvons
pas affirmer même avec une marge d’erreur de 5% que ces valeurs sont différentes.
TTP 8 - 2006-2007 (Corrigé) 21/ 23
2. Un scientifique veut savoir s’il y a un lien entre la dominance manuelle et la dominance
oculaire. Un échantillon aléatoire de 150 sujets est sélectionné. Pour chaque sujet, le
chercheur détermine deux choses :
- Si la personne est droitière ou gauchère ;
- Quel est l’œil que la personne préfère utiliser pour regarder à travers le
viseur d’un appareil photo.
Le tableau des fréquences observées est le suivant :
Préférence manuelle
Gauche Droite
Gauche 20 40
Préférence oculaire
Droite 10 80
Y a-t-il une relation entre les deux variables ? Choisissez un seuil de .05.
Réponse :
Pour répondre à la question, nous devons effectuer un test χ 2 d’indépendance.
Pour ce faire, il faut déterminer les fréquences attend ues sous l’hypothèse
d’indépendance, en ayant préalablement calculé les fréquences marginales :
Préférence manuelle
Gauche Droite Total
Gauche (30*60)/150 = 12 (120*60)/150 = 48 60
Préférence
Droite (30*90)/150 = 18 (120*90)/150 = 72 90
oculaire
Total 30 120 72
Puis, il faut déterminer la valeur du χ calculé
2
:
J (O j − E j ) 2 (20 − 12)2 (40 − 48)2 (10 − 18)2 (80 − 72)2
χ 2
calculé =∑ = + + + = 11,11
j =1 Ej 12 48 18 72
et la comparer à la valeur du χ théorique
2
à .05 et 1 degré de liberté qui vaut 3,84 :
3,84<<11,11
Nous nous situons donc dans la zo ne de rejet de l’hypothèse nulle. Nous pouvons
affirmer avec un risque d’erreur maximal de 5% qu’il n’y a pas indépendance entre les
deux variables et qu’il y a donc un lien entre les deux.
TTP 8 - 2006-2007 (Corrigé) 22/ 23
2. Un chercheur pense que les personnes avec une faible estime d’eux-mêmes auront
tendance à éviter les situations qui attireront l’attention sur elles. Un échantillon aléatoire
de 72 personnes est sélectionné. Chaque personne est soumise à un test standardisé qui
mesure l’estime de soi en la définissant comme haute, moyenne ou faible. Les sujets sont
ensuite placés dans une situation dans laquelle ils doivent choisir entre une tâche qui devra
être effectuée devant les autres et une tâche qui devra être effectuée par la personne seule.
Le chercheur note le choix de ses sujets et dresse le tableau de fréquences suivant :
Tâche
En public Sans public
Faible 4 16
Estime de soi Moyenne 14 14
Haute 18 6
Y a-t-il un lien entre estime de soi et le choix de la tâche à un seuil de .05.
Réponse :
Pour répondre à la question, nous devons effectuer un test χ 2 d’indépendance.
Pour ce faire, il faut déterminer les fréquences attendues sous l’hypothèse
d’indépendance, en ayant préalablement calculé les fréquences marginales :
Tâche
En public Sans public Total
Faible (36*20)/72 = 10 (36*20)/72 = 10 20
Estime de Moyenne (36*28)/72 = 14 (36*28)/72 = 14 28
soi Haute (36*24)/72 = 12 (36*24)/72 = 12 24
Total 36 36 72
Puis, il faut déterminer la valeur du χ calculé
2
:
J (O j − E j ) 2 (4 − 10)2 (16 − 10)2 (14 − 14)2
χ 2
calculé =∑ = + +
j =1 Ej 10 10 14
(14 − 14)2 (18 − 12)2 (6 − 12 )2
+ + + = 13,2
14 12 12
et la comparer à la valeur du χ théorique
2
à .05 et 2 degrés de liberté qui vaut 5,99:
5,99<13,2
Nous nous situons donc dans la zone de rejet de l’hypothèse nulle. Nous pouvons
affirmer avec un risque d’erreur maximal de 5% qu’il n’y a pas indépendance entre les
deux variables et qu’il y a donc un lien entre les deux.
TTP 8 - 2006-2007 (Corrigé) 23/ 23
You might also like
- Équations différentielles: Les Grands Articles d'UniversalisFrom EverandÉquations différentielles: Les Grands Articles d'UniversalisNo ratings yet
- Chap 5Document11 pagesChap 5warriormind001No ratings yet
- Chapitre 2 Les Tests D'hypothèse PDFDocument17 pagesChapitre 2 Les Tests D'hypothèse PDFÎlŸãş MïmøNo ratings yet
- S1 Modelisation RLDocument20 pagesS1 Modelisation RLAmine ChettatNo ratings yet
- Master1 PCP Analyse Statistique M1 Physio BenabdallahDocument6 pagesMaster1 PCP Analyse Statistique M1 Physio BenabdallahAmira AmouraNo ratings yet
- TD5 TH 2020Document6 pagesTD5 TH 2020Wael KhemakhemNo ratings yet
- CHAPITRE 7 StatistiqueDocument32 pagesCHAPITRE 7 StatistiqueAbdallahi SidiNo ratings yet
- Chap 6Document17 pagesChap 6rabia lbNo ratings yet
- Tests D'hypothèsesDocument19 pagesTests D'hypothèsesKarin RiveraNo ratings yet
- Biostatistique Test D'hommogéinitéDocument4 pagesBiostatistique Test D'hommogéinitéLudocris Zizman EvilnessNo ratings yet
- Corrige Type - td9 2122Document8 pagesCorrige Type - td9 2122LoudjeineNo ratings yet
- Partie 2-2022Document32 pagesPartie 2-2022Med Reda ElwafiNo ratings yet
- Stat1 Chapitres5Document6 pagesStat1 Chapitres5Adam BouhadmaNo ratings yet
- Biostatistique Master 1Document4 pagesBiostatistique Master 1Blast MindNo ratings yet
- 4 Tests Paramétriques1Document18 pages4 Tests Paramétriques1Med JDNo ratings yet
- Chapitre 3 Hétéroscedasticite Des ErreursDocument7 pagesChapitre 3 Hétéroscedasticite Des ErreursNgos JeanNo ratings yet
- ProbaDocument6 pagesProbaetoiledemer123No ratings yet
- Biostatistique Chap 3 - Tests Statistiques-Analyse de La VarianceDocument40 pagesBiostatistique Chap 3 - Tests Statistiques-Analyse de La VariancebichakuayougalandNo ratings yet
- Chap2 Autocorrélations Les ErreursDocument15 pagesChap2 Autocorrélations Les ErreursNgos Jean100% (1)
- Stat InferentielleDocument55 pagesStat InferentielleWilson Daniche KissieNo ratings yet
- Exercice de Test D'hypothèseDocument58 pagesExercice de Test D'hypothèseScribdTranslations100% (1)
- (Final) Cour5 Tests - CopyfinalDocument15 pages(Final) Cour5 Tests - CopyfinalNinineNo ratings yet
- Esti Test SMC4 StatDocument12 pagesEsti Test SMC4 StatEddouks FatimazahraeNo ratings yet
- Chapitre 2Document10 pagesChapitre 2Lina alikhNo ratings yet
- Probabilités Et Statistiques Examen 02Document10 pagesProbabilités Et Statistiques Examen 02oly tsihivaNo ratings yet
- Séances 8 9 Et 10 s3 Echantillonnage Et Estimation PR Smouni Dec 2020Document14 pagesSéances 8 9 Et 10 s3 Echantillonnage Et Estimation PR Smouni Dec 2020abdelmoutalebNo ratings yet
- Corriges - Exo - Revisions - 1137669199970 - Copie PDFDocument9 pagesCorriges - Exo - Revisions - 1137669199970 - Copie PDFsabrineNo ratings yet
- FisherDocument5 pagesFisherHatim El OtmaniNo ratings yet
- Résumé Économétrie (By Fayssel Merraoui)Document6 pagesRésumé Économétrie (By Fayssel Merraoui)Óthmãňe Eřŕîfi100% (3)
- Cours S5 10 13 - TOUIJARDocument177 pagesCours S5 10 13 - TOUIJARmalaga04No ratings yet
- Exercices Stat Non ParametriqueDocument20 pagesExercices Stat Non ParametriqueNora HabrichNo ratings yet
- Test Khi-DeuxDocument8 pagesTest Khi-DeuxibrahimaNo ratings yet
- Regression LogistiqueDocument4 pagesRegression Logistiquesoraya ferhiNo ratings yet
- Khi DeuxDocument11 pagesKhi DeuxOussama El MkhayarNo ratings yet
- Tests D'hypothèses ParamétriquesDocument16 pagesTests D'hypothèses ParamétriquesSouheil BéjiNo ratings yet
- Sci1018 l5 TheorieDocument24 pagesSci1018 l5 TheorieEzekiel TakaNo ratings yet
- Chapitre V Tests D'hypothesesDocument12 pagesChapitre V Tests D'hypothesesMayssa ChakrounNo ratings yet
- Subm 120Document6 pagesSubm 120Sefiane El-kassimiNo ratings yet
- Test Hyp SlidesDocument25 pagesTest Hyp SlidesIheb DerwichNo ratings yet
- Statistique II C: Hapitre 3Document30 pagesStatistique II C: Hapitre 3sa saNo ratings yet
- Analyse de Régression LinéaireDocument12 pagesAnalyse de Régression LinéairekarimNo ratings yet
- Seance_5_Distributions de probabilitésDocument45 pagesSeance_5_Distributions de probabilitéssorimalika66No ratings yet
- Psycho Slides Stat L3 S6Document76 pagesPsycho Slides Stat L3 S6Bvictor Boni100% (1)
- Les Tests D - HypothèseDocument19 pagesLes Tests D - Hypothèseoussama100% (2)
- Biométrie P2Document53 pagesBiométrie P2manarlahbibNo ratings yet
- M1 Poly TD Modules 1 2 BaseDocument35 pagesM1 Poly TD Modules 1 2 BaseHedi cherifNo ratings yet
- 5 Chi2 AnovaDocument16 pages5 Chi2 AnovaLAZARRENo ratings yet
- Le Test Du Khi DeuxDocument40 pagesLe Test Du Khi DeuxTommy Helson0% (1)
- CM_seance_07Document11 pagesCM_seance_07virgile.gibertNo ratings yet
- Corrigés Exercices Chapitre IIIDocument12 pagesCorrigés Exercices Chapitre IIIBérenger NikirehiNo ratings yet
- Séance 7 - TH - Corrigé TD3 - QuaramDocument11 pagesSéance 7 - TH - Corrigé TD3 - QuaramHajarNo ratings yet
- Enoncetd 4Document4 pagesEnoncetd 4MichelNo ratings yet
- PDF Cours EtuDocument32 pagesPDF Cours EtuNaim ChNo ratings yet
- Examen Credit1920Document9 pagesExamen Credit1920imen.rashdi.etudesNo ratings yet
- Labarere Jose p07 PDFDocument56 pagesLabarere Jose p07 PDFYassine TazizNo ratings yet
- Cours Inférence CH IV - Ouazza - 22-23Document47 pagesCours Inférence CH IV - Ouazza - 22-23Aymane SguigaaNo ratings yet
- Introduction Aux Statistiques Et À L'utilisation Du Logiciel R 16pDocument16 pagesIntroduction Aux Statistiques Et À L'utilisation Du Logiciel R 16pradoniainaNo ratings yet
- Chapitr 3 Traitment JG & HZ TAC S6Document3 pagesChapitr 3 Traitment JG & HZ TAC S6elbakaliloubna11No ratings yet
- 5 L Insertion de Tableau Graphique Et Du Son Dans Une DiapositiveDocument1 page5 L Insertion de Tableau Graphique Et Du Son Dans Une DiapositiveZAHRA FASKA100% (1)
- TigerDocument35 pagesTigerolazagutiaNo ratings yet
- Texte Partiel FrançaisDocument3 pagesTexte Partiel FrançaisDaniel Quiroz OspinaNo ratings yet
- 1-Electrodes en PotentiométrieDocument28 pages1-Electrodes en Potentiométriechahira chahiraNo ratings yet
- 101 Idées de Blog Qui Rapportent en 2020 (Niches Rentables) PDFDocument1 page101 Idées de Blog Qui Rapportent en 2020 (Niches Rentables) PDFCarine NgahNo ratings yet
- Devoir 1Document3 pagesDevoir 1ربيعه ربيعه عريشNo ratings yet
- Document(Autosaved)Document1 pageDocument(Autosaved)Belmond NONONo ratings yet
- A. Présentation Générale Des "Cahiers de Douai" Et D'arthur RimbaudDocument3 pagesA. Présentation Générale Des "Cahiers de Douai" Et D'arthur RimbaudmasmoudirayaNo ratings yet
- Nouveaux Coups en Points AoSDocument33 pagesNouveaux Coups en Points AoSValentin MOREAUNo ratings yet
- Five Note ConcertoDocument8 pagesFive Note ConcertoVirgílio VidinhaNo ratings yet
- Livret Du Coffret DVD René Allio Et Marseille (Shellac)Document29 pagesLivret Du Coffret DVD René Allio Et Marseille (Shellac)MargueriteVappereauNo ratings yet
- Hulas PipesDocument17 pagesHulas PipesThakur AdhikariNo ratings yet
- Expressions Pour Demander, Accepter Ou Refuser Une AutorisationDocument1 pageExpressions Pour Demander, Accepter Ou Refuser Une AutorisationMomoKonanNo ratings yet
- OnomancieDocument2 pagesOnomanciejcpiasentinNo ratings yet
- Chorégraphie Et Fiche Juge AEROBICDocument2 pagesChorégraphie Et Fiche Juge AEROBIChamza.alexNo ratings yet
- Les Figures de StylesDocument2 pagesLes Figures de StylesJamesNo ratings yet
- CHICLAYANITA - Marinera-1-1 PDFDocument12 pagesCHICLAYANITA - Marinera-1-1 PDFJorge VasquezNo ratings yet
- Faire Son TofuDocument5 pagesFaire Son TofuOzoNo ratings yet
- Bda md21058 FR PDFDocument97 pagesBda md21058 FR PDFAboubacar N'dji CoulibalyNo ratings yet
- 05a Activites Autour Du VerbeDocument162 pages05a Activites Autour Du VerbeMariann Sek SanNo ratings yet
- Os MozisDocument4 pagesOs Mozissanguinarius_contactNo ratings yet
- FICHE DE TRAVAIL - Les Sports IX BDocument3 pagesFICHE DE TRAVAIL - Les Sports IX BMorenita MadyNo ratings yet
- Allah-Initche-Ini-Baradji AbelDocument3 pagesAllah-Initche-Ini-Baradji AbelYao jean Jaurès KouadioNo ratings yet
- Regle Du Jeu VF2 Eme EditionDocument18 pagesRegle Du Jeu VF2 Eme EditionvolovNo ratings yet
- Fournier Rapport Nov2012Document49 pagesFournier Rapport Nov2012CondéNo ratings yet
- C'est L'heure de La Pause Active - Fiche Explicative EnseignantsDocument4 pagesC'est L'heure de La Pause Active - Fiche Explicative Enseignantsdemai100% (1)
- Liste Des ChainesDocument16 pagesListe Des ChainesAlexander KingsNo ratings yet
- Chapitre 4Document18 pagesChapitre 4sdcsdcsNo ratings yet
- Solution TD SEDocument21 pagesSolution TD SEsabri rabieNo ratings yet
- Formalités Visa 2022Document1 pageFormalités Visa 2022Dip ShootsNo ratings yet