You might also like
- 5 6329898847812190445 PDFDocument2 pages5 6329898847812190445 PDFWita ManaluNo ratings yet
- Soal Try Out Kimia Dan PembahasanDocument9 pagesSoal Try Out Kimia Dan PembahasanWita ManaluNo ratings yet
- Hasil Two Way ANOVADocument25 pagesHasil Two Way ANOVAWita ManaluNo ratings yet
- Template 1Document2 pagesTemplate 1Wita ManaluNo ratings yet
- Coal Dewatering TechnologyDocument39 pagesCoal Dewatering TechnologyWita ManaluNo ratings yet
- Thesis The Effect of Moisture On The Hgi of Coal PDFDocument206 pagesThesis The Effect of Moisture On The Hgi of Coal PDFWita ManaluNo ratings yet
- Grafik R-80 (Batu Gamping) : Ukuran Undersize 9,5 81,6 4,75 53,07 2,36 41,34 1,7 37,34 1,18 35,21Document2 pagesGrafik R-80 (Batu Gamping) : Ukuran Undersize 9,5 81,6 4,75 53,07 2,36 41,34 1,7 37,34 1,18 35,21Wita ManaluNo ratings yet
- Template 1Document2 pagesTemplate 1Wita ManaluNo ratings yet
- Q-System (Mekbat)Document6 pagesQ-System (Mekbat)Wita ManaluNo ratings yet
- Analysis of Ash Testing of Coal on the Potential Formation of Slagging and Fouling Indices in BoilersDocument1 pageAnalysis of Ash Testing of Coal on the Potential Formation of Slagging and Fouling Indices in BoilersWita ManaluNo ratings yet
- ContrastinSelf-HeatingRateBehaviourforCoalsofSimilarRank BeamishandTheiler 2015Document7 pagesContrastinSelf-HeatingRateBehaviourforCoalsofSimilarRank BeamishandTheiler 2015Wita ManaluNo ratings yet
- Kurva Washability Test Wita FixDocument2 pagesKurva Washability Test Wita FixWita ManaluNo ratings yet
- Ash Fusion Temperature (AFT) (AFT) Ash Analysis Proximate (AFT)Document1 pageAsh Fusion Temperature (AFT) (AFT) Ash Analysis Proximate (AFT)Wita ManaluNo ratings yet
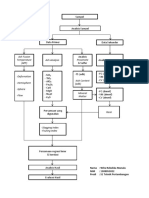
- Presentasi Flow ChartDocument6 pagesPresentasi Flow ChartWita ManaluNo ratings yet
- Flowchart PenelitianDocument1 pageFlowchart PenelitianWita Manalu0% (1)
- The Effect of Product Design, Price and Location Toward PurchaseDocument9 pagesThe Effect of Product Design, Price and Location Toward PurchaseWita ManaluNo ratings yet
- Spesifikasi Alat BeratDocument36 pagesSpesifikasi Alat BeratWita Manalu100% (1)
- The Impact of Landscape QualityDocument16 pagesThe Impact of Landscape QualityWita ManaluNo ratings yet
- Mining Excavator: Operating Weight With Backhoe Attachment: Shovel Attachment: Engine: Bucket Capacity: Shovel CapacityDocument10 pagesMining Excavator: Operating Weight With Backhoe Attachment: Shovel Attachment: Engine: Bucket Capacity: Shovel CapacityWita ManaluNo ratings yet
- New Headway Elementary Student Book Cover PDFDocument146 pagesNew Headway Elementary Student Book Cover PDFWita Manalu100% (2)
- Washability TestDocument2 pagesWashability TestWita ManaluNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Impact of School Facilities On The Learning EnvironmentDocument174 pagesThe Impact of School Facilities On The Learning EnvironmentEnrry Sebastian71% (31)
- Rubber Chemical Resistance Chart V001MAR17Document27 pagesRubber Chemical Resistance Chart V001MAR17Deepak patilNo ratings yet
- GIS Multi-Criteria Analysis by Ordered Weighted Averaging (OWA) : Toward An Integrated Citrus Management StrategyDocument17 pagesGIS Multi-Criteria Analysis by Ordered Weighted Averaging (OWA) : Toward An Integrated Citrus Management StrategyJames DeanNo ratings yet
- Pub - Essentials of Nuclear Medicine Imaging 5th Edition PDFDocument584 pagesPub - Essentials of Nuclear Medicine Imaging 5th Edition PDFNick Lariccia100% (1)
- Service and Maintenance Manual: Models 600A 600AJDocument342 pagesService and Maintenance Manual: Models 600A 600AJHari Hara SuthanNo ratings yet
- Jfif 1.02Document9 pagesJfif 1.02Berry Hoekstra100% (1)
- Rohit Patil Black BookDocument19 pagesRohit Patil Black BookNaresh KhutikarNo ratings yet
- #### # ## E232 0010 Qba - 0Document9 pages#### # ## E232 0010 Qba - 0MARCONo ratings yet
- Axe Case Study - Call Me NowDocument6 pagesAxe Case Study - Call Me NowvirgoashishNo ratings yet
- Tigo Pesa Account StatementDocument7 pagesTigo Pesa Account StatementPeter Ngicur Carthemi100% (1)
- Rtsa 2012Document7 pagesRtsa 2012Justin RobinsonNo ratings yet
- DECA IMP GuidelinesDocument6 pagesDECA IMP GuidelinesVuNguyen313No ratings yet
- Three-D Failure Criteria Based on Hoek-BrownDocument5 pagesThree-D Failure Criteria Based on Hoek-BrownLuis Alonso SANo ratings yet
- NewspaperDocument11 pagesNewspaperКристина ОрёлNo ratings yet
- Riddles For KidsDocument15 pagesRiddles For KidsAmin Reza100% (8)
- Book Networks An Introduction by Mark NewmanDocument394 pagesBook Networks An Introduction by Mark NewmanKhondokar Al MominNo ratings yet
- S5-42 DatasheetDocument2 pagesS5-42 Datasheetchillin_in_bots100% (1)
- #3011 Luindor PDFDocument38 pages#3011 Luindor PDFcdouglasmartins100% (1)
- Neuropsychological Deficits in Disordered Screen Use Behaviours - A Systematic Review and Meta-AnalysisDocument32 pagesNeuropsychological Deficits in Disordered Screen Use Behaviours - A Systematic Review and Meta-AnalysisBang Pedro HattrickmerchNo ratings yet
- Instrumentation Positioner PresentationDocument43 pagesInstrumentation Positioner PresentationSangram Patnaik100% (1)
- Katie Tiller ResumeDocument4 pagesKatie Tiller Resumeapi-439032471No ratings yet
- Math5 Q4 Mod10 DescribingAndComparingPropertiesOfRegularAndIrregularPolygons v1Document19 pagesMath5 Q4 Mod10 DescribingAndComparingPropertiesOfRegularAndIrregularPolygons v1ronaldNo ratings yet
- Olympics Notes by Yousuf Jalal - PDF Version 1Document13 pagesOlympics Notes by Yousuf Jalal - PDF Version 1saad jahangirNo ratings yet
- Rounded Scoodie Bobwilson123 PDFDocument3 pagesRounded Scoodie Bobwilson123 PDFStefania MoldoveanuNo ratings yet
- Exercises2 SolutionsDocument7 pagesExercises2 Solutionspedroagv08No ratings yet
- Conv VersationDocument4 pagesConv VersationCharmane Barte-MatalaNo ratings yet
- Sewage Pumping StationDocument35 pagesSewage Pumping StationOrchie DavidNo ratings yet
- Lifespan Development Canadian 6th Edition Boyd Test BankDocument57 pagesLifespan Development Canadian 6th Edition Boyd Test Bankshamekascoles2528zNo ratings yet
- Steam Turbine Theory and Practice by Kearton PDF 35Document4 pagesSteam Turbine Theory and Practice by Kearton PDF 35KKDhNo ratings yet
- Disaster Management Plan 2018Document255 pagesDisaster Management Plan 2018sifoisbspNo ratings yet