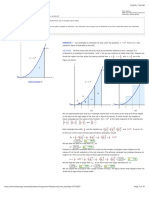
You might also like
- Lab 5 Combined LoadingDocument13 pagesLab 5 Combined Loadingapi-3730129100% (1)
- Practice Exercise 5.1Document16 pagesPractice Exercise 5.1Chris RamosNo ratings yet
- A1 Tutorial Problems QE1 2015-16Document11 pagesA1 Tutorial Problems QE1 2015-16Avelyn Tang100% (1)
- Linear Algebra With ApplicationsDocument1,032 pagesLinear Algebra With ApplicationsAzima TarannumNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Botswana Manual On Pavement TestingDocument99 pagesBotswana Manual On Pavement TestingMargaret Sipatela100% (1)
- Project 2: Technical University of DenmarkDocument11 pagesProject 2: Technical University of DenmarkRiyaz AlamNo ratings yet
- Nur Syuhada Binti Safaruddin - Rba2403a - 2020819322Document6 pagesNur Syuhada Binti Safaruddin - Rba2403a - 2020819322syuhadasafar000No ratings yet
- Department of Computer Science Engineering: SolutionDocument5 pagesDepartment of Computer Science Engineering: SolutionAnuj guptaNo ratings yet
- Agribot Result AnalysisDocument27 pagesAgribot Result AnalysistskssNo ratings yet
- Asm 1Document4 pagesAsm 1Hằng TốngNo ratings yet
- Poe AnswersDocument78 pagesPoe AnswersNguyen Xuan Nguyen100% (2)
- Solution Chapter 2 MandenhallDocument29 pagesSolution Chapter 2 MandenhallUzair KhanNo ratings yet
- An Assignment of Data Treatment and AnalysisDocument18 pagesAn Assignment of Data Treatment and AnalysisOlivia2201No ratings yet
- Kelompok 6Document7 pagesKelompok 6Bervie RondonuwuNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Department of Statistics: Course Stats 330Document5 pagesDepartment of Statistics: Course Stats 330PETERNo ratings yet
- Second Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions ManualDocument11 pagesSecond Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions Manualdulcitetutsanz9u100% (18)
- Week 5Document9 pagesWeek 5sachinNo ratings yet
- Quantitative Aptitude Shortcuts and Tricks For Competitive ExamsDocument20 pagesQuantitative Aptitude Shortcuts and Tricks For Competitive ExamsDilip Yadav100% (1)
- Chapter 9: Selection of VariablesDocument30 pagesChapter 9: Selection of VariablesMerk GetNo ratings yet
- Eda Finals ExamDocument23 pagesEda Finals ExamJamael AbulaisNo ratings yet
- Chapter FourandfiveDocument18 pagesChapter FourandfiveSimeon Paul taiwoNo ratings yet
- Multiple Linear RegressionDocument25 pagesMultiple Linear Regression3432meesala100% (1)
- Chapter 15Document13 pagesChapter 15Udevir SinghNo ratings yet
- Prediction 2Document7 pagesPrediction 2slarasaaNo ratings yet
- Advertising Sales ($) Average # of Viewers (Millions) Length of Program (Minutes) Average Viewer Age (Years)Document9 pagesAdvertising Sales ($) Average # of Viewers (Millions) Length of Program (Minutes) Average Viewer Age (Years)Kiran JawaidNo ratings yet
- MTH10007 Notes s1-2015Document208 pagesMTH10007 Notes s1-2015Dylan Ngu Tung Hong0% (1)
- Final Exam, Data Mining (CEN 871) : Name Surname: Student's IDDocument2 pagesFinal Exam, Data Mining (CEN 871) : Name Surname: Student's IDDimitrios A. KarrasNo ratings yet
- ANOVA Treatment of FiberDocument11 pagesANOVA Treatment of Fibernsg032288No ratings yet
- Model ReportDocument3 pagesModel ReportMuneeb ButtNo ratings yet
- CS6011: Kernel Methods For Pattern Analysis: Submitted byDocument26 pagesCS6011: Kernel Methods For Pattern Analysis: Submitted byPawan GoyalNo ratings yet
- ENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierDocument13 pagesENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierAli O DalkiNo ratings yet
- Statistical Learning Master ReportsDocument11 pagesStatistical Learning Master ReportsValentina Mendoza ZamoraNo ratings yet
- Supporting Material: Robust Probabilistic Superposition and Comparison of Protein StructuresDocument12 pagesSupporting Material: Robust Probabilistic Superposition and Comparison of Protein StructuresGuilhermeAntónioCossoulNo ratings yet
- STA302 Mid 2009FDocument10 pagesSTA302 Mid 2009FexamkillerNo ratings yet
- Answered Sheets CombinedDocument52 pagesAnswered Sheets CombinedrayanmaazsiddigNo ratings yet
- Stat 2032 2014 Final SolutionsDocument12 pagesStat 2032 2014 Final SolutionsJasonNo ratings yet
- Solution: A) Since 65.5 - 62.5 3, The Interval Must Be 3.: N F Rel N F RelDocument6 pagesSolution: A) Since 65.5 - 62.5 3, The Interval Must Be 3.: N F Rel N F RelevanaannNo ratings yet
- LAB4Document5 pagesLAB4dam huu khoaNo ratings yet
- Lab 9 ReportDocument5 pagesLab 9 ReportMaira SulaimanovaNo ratings yet
- Assignment 6 Regression Solution PDFDocument5 pagesAssignment 6 Regression Solution PDFlyriemaecutara0No ratings yet
- Lab 1 ReportDocument13 pagesLab 1 Reportapi-247384029No ratings yet
- Econometrics FinalDocument16 pagesEconometrics FinalDanikaLiNo ratings yet
- Stat 252-Practice Final-Greg-SolutionsDocument14 pagesStat 252-Practice Final-Greg-Solutionsdeep81204No ratings yet
- Regression: Standardized CoefficientsDocument8 pagesRegression: Standardized CoefficientsgedleNo ratings yet
- BFA TCP Exam Brief 21-22 Final 080322Document5 pagesBFA TCP Exam Brief 21-22 Final 080322tanay chakrabortyNo ratings yet
- ProjectreportemgDocument9 pagesProjectreportemgOscar De SilvaNo ratings yet
- Educate - Empower: EnhanceDocument8 pagesEducate - Empower: EnhanceRaka Adhwa MaharikaNo ratings yet
- Ch18 Multiple RegressionDocument51 pagesCh18 Multiple Regressionbugti1986No ratings yet
- Linear Programming Method Application in A Solar CellDocument12 pagesLinear Programming Method Application in A Solar CellKaty Flores OrihuelaNo ratings yet
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Assignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranDocument8 pagesAssignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranThrilling MeherabNo ratings yet
- Part 1: Guidelines For Fitting A Multilevel Model in SPSS MixedDocument10 pagesPart 1: Guidelines For Fitting A Multilevel Model in SPSS MixedHenio MillanNo ratings yet
- Mark Scheme (Results) January 2015: Pearson Edexcel International Advanced Level in Physics (WPH06) Paper 01Document13 pagesMark Scheme (Results) January 2015: Pearson Edexcel International Advanced Level in Physics (WPH06) Paper 01sedara samarasingheNo ratings yet
- Solution Manual For Probability and Statistics For Engineers and Scientists 9Th Edition Walpole Myers Ye 0134115856 9780134115856 Full Chapter PDFDocument36 pagesSolution Manual For Probability and Statistics For Engineers and Scientists 9Th Edition Walpole Myers Ye 0134115856 9780134115856 Full Chapter PDFjohn.rosenstock869100% (12)
- Lecture 10Document33 pagesLecture 10anushkaNo ratings yet
- EEET321 Circuit Analysis 2 Rev0 AolDocument8 pagesEEET321 Circuit Analysis 2 Rev0 AolJethro Exequiel SibayanNo ratings yet
- 7232 01 Data Management Trends Powerpoint Template 16x9Document11 pages7232 01 Data Management Trends Powerpoint Template 16x9Eduardo Espinoza GCPNo ratings yet
- Summer Project Guideline Final 2019Document12 pagesSummer Project Guideline Final 2019Aniket WaghNo ratings yet
- Exercise Statistic Chapter 1 Page 17Document5 pagesExercise Statistic Chapter 1 Page 17Vita ShanyNo ratings yet
- DWM Microproject Report GRP No.24Document24 pagesDWM Microproject Report GRP No.24Aryan BuchakeNo ratings yet
- Correlation in SPSSDocument2 pagesCorrelation in SPSSRyenFoongChanYen100% (1)
- Machine Learning - An Algorithmic Perspective (2nd Ed.) (Marsland 2014-10-08)Document15 pagesMachine Learning - An Algorithmic Perspective (2nd Ed.) (Marsland 2014-10-08)Orwell HUxleyNo ratings yet
- Coporate Profile Venkat ResumeDocument3 pagesCoporate Profile Venkat ResumePrashanth GupthaNo ratings yet
- Power BI Class NotesDocument18 pagesPower BI Class Notesramu9999No ratings yet
- BBSS 1103Document14 pagesBBSS 1103hdeenNo ratings yet
- Newbold Stat7 Ism 07Document28 pagesNewbold Stat7 Ism 07tawamagconNo ratings yet
- Decision Trees For Classification - DocumentDocument4 pagesDecision Trees For Classification - DocumentKaunga KivunziNo ratings yet
- Lecture 10 Clustering and ClassificationDocument41 pagesLecture 10 Clustering and ClassificationNoud JaspersNo ratings yet
- Non Parametrical Statics Biological With R PDFDocument341 pagesNon Parametrical Statics Biological With R PDFJhon ReyesNo ratings yet
- 6187b86b53dad Professional Assignment 2 Clo 1 Clo 2 Clo 3 Clo 5 Clo 7 Clo 10Document6 pages6187b86b53dad Professional Assignment 2 Clo 1 Clo 2 Clo 3 Clo 5 Clo 7 Clo 10Sơn TùngNo ratings yet
- Data CollectionDocument44 pagesData Collection282030 ktr.pg.iscf.18No ratings yet
- Chapter 8 "RICK HAYES" "Analytical Procedures"Document15 pagesChapter 8 "RICK HAYES" "Analytical Procedures"Joan AnindaNo ratings yet
- Correlation & RegressionDocument28 pagesCorrelation & RegressionANCHAL SINGHNo ratings yet
- CarDocument169 pagesCarooooooooooNo ratings yet
- Results Example Research PaperDocument7 pagesResults Example Research Paperefjddr4z100% (1)
- Module 5 - Post TaskDocument5 pagesModule 5 - Post TaskTHEA BEATRICE GARCIANo ratings yet
- Ghemawats - Apollo HospitalDocument5 pagesGhemawats - Apollo HospitalNilesh GaidhaneNo ratings yet
- FEU Diliman - Forecasting TechniquesDocument5 pagesFEU Diliman - Forecasting TechniquesM.E. Foods, Inc.No ratings yet
- Exercises For QUIZ 3Document2 pagesExercises For QUIZ 3louise carinoNo ratings yet
- Healthcare AnayticsDocument26 pagesHealthcare Anayticstamara_0021No ratings yet
- Hypothesis Testing: W&W, Chapter 9Document27 pagesHypothesis Testing: W&W, Chapter 9alotfyaNo ratings yet
- SPSSTutorial Math CrackerDocument43 pagesSPSSTutorial Math CrackerKami4038No ratings yet
- Lesson 8 - ClassificationDocument74 pagesLesson 8 - ClassificationrimbrahimNo ratings yet