You might also like
- Seq SlidesDocument43 pagesSeq Slidesmyturtle game01No ratings yet
- Analysis of elastic foundation model using differential transform methodDocument18 pagesAnalysis of elastic foundation model using differential transform methoddandy imam fauziNo ratings yet
- Euler's Theorem For Homogeneous Functions: Division of The Humanities and Social SciencesDocument5 pagesEuler's Theorem For Homogeneous Functions: Division of The Humanities and Social SciencesNavaneethNo ratings yet
- Intro Optimal Control Discrete Euler-LagrangeDocument5 pagesIntro Optimal Control Discrete Euler-LagrangesalimNo ratings yet
- Euler HomogeneityDocument4 pagesEuler HomogeneityprivateNo ratings yet
- MAT 461/561: 5.1 Stationary Iterative MethodsDocument4 pagesMAT 461/561: 5.1 Stationary Iterative MethodsDebisaNo ratings yet
- Unit WISE 2 MARKS PDFDocument38 pagesUnit WISE 2 MARKS PDFInfi Coaching CenterNo ratings yet
- Mathematical functions and optimizationDocument5 pagesMathematical functions and optimizationartecksasNo ratings yet
- GATE Electrical 2015 01 February 07 Forenoon Session Converted 2 1Document75 pagesGATE Electrical 2015 01 February 07 Forenoon Session Converted 2 1Abhinav KumarNo ratings yet
- GR Exercise 1Document4 pagesGR Exercise 1Keshav PrasadNo ratings yet
- Second Exam Sheet: Taylor Polynomial ApproximationDocument2 pagesSecond Exam Sheet: Taylor Polynomial ApproximationSameer HmedatNo ratings yet
- Cvar 4Document2 pagesCvar 4nicholas_j_vaughanNo ratings yet
- Appendix PDFDocument6 pagesAppendix PDFAnonymous 2rlcHIpCkwNo ratings yet
- An Introduction To Some Novel Applications of Lie Algebra Cohomology in Mathematics and PhysicsDocument25 pagesAn Introduction To Some Novel Applications of Lie Algebra Cohomology in Mathematics and PhysicsDaniel VargasNo ratings yet
- Statisticsyear 1 DistributionsDocument3 pagesStatisticsyear 1 Distributionsapi-394057706No ratings yet
- Exam 2016, Questions Exam 2016, QuestionsDocument6 pagesExam 2016, Questions Exam 2016, QuestionsRoy VeseyNo ratings yet
- A Remark On Asymptotic Property of CommutatorsDocument5 pagesA Remark On Asymptotic Property of CommutatorsKaren Karlen HuruntzNo ratings yet
- Unconstrained Optimization Differentiable Case: October 9, 2008Document19 pagesUnconstrained Optimization Differentiable Case: October 9, 2008Samuel Alfonzo Gil BarcoNo ratings yet
- Proximal Gradient Descent: (And Acceleration)Document33 pagesProximal Gradient Descent: (And Acceleration)Saheli ChakrabortyNo ratings yet
- Mathematics Formulary PDFDocument30 pagesMathematics Formulary PDFfizarimaeNo ratings yet
- Conditional Gradient (Frank-Wolfe) Method: Lecturer: Javier Pe Na Convex Optimization 10-725/36-725Document28 pagesConditional Gradient (Frank-Wolfe) Method: Lecturer: Javier Pe Na Convex Optimization 10-725/36-725Nguyễn Quang HuyNo ratings yet
- CS 7641 CSE/ISYE 6740 Homework 3 instructionsDocument4 pagesCS 7641 CSE/ISYE 6740 Homework 3 instructionsEthan ChannellNo ratings yet
- Subgradient Method: Ryan Tibshirani Convex Optimization 10-725Document21 pagesSubgradient Method: Ryan Tibshirani Convex Optimization 10-725Saheli ChakrabortyNo ratings yet
- SEEMOUS 2009 ProblemsDocument4 pagesSEEMOUS 2009 ProblemsHipstersdssadadNo ratings yet
- 1 Polynomial Equations: 1.1 Bijection MethodDocument13 pages1 Polynomial Equations: 1.1 Bijection MethodDeeptanshu ShuklaNo ratings yet
- Bounds in EM InversionDocument5 pagesBounds in EM InversionClarisse FernandesNo ratings yet
- 472notes PDFDocument98 pages472notes PDFAnonymous vNyn0ch3nNo ratings yet
- (k+1) K (K) (K) (K) : Recall That A Direction Is A Vector of Unit LengthDocument5 pages(k+1) K (K) (K) (K) : Recall That A Direction Is A Vector of Unit LengthHilal Akmal AdiputraNo ratings yet
- An Improved Parameter Regula Falsi Method For Enclosing A Zero of A FunctionDocument15 pagesAn Improved Parameter Regula Falsi Method For Enclosing A Zero of A FunctionIqbal Imamul MuttaqinNo ratings yet
- Frank WolfeDocument25 pagesFrank Wolfesherlockholmes108No ratings yet
- 1 Convex Analysis: 1.1 Motivations: Convex Optimization ProblemsDocument24 pages1 Convex Analysis: 1.1 Motivations: Convex Optimization ProblemsRashmi PhadnisNo ratings yet
- Unconstrained Minimization in R: Newton MethodsDocument5 pagesUnconstrained Minimization in R: Newton MethodsAbdesselem BoulkrouneNo ratings yet
- AssignmentDocument1 pageAssignmentf20221642No ratings yet
- Weak TopologyDocument15 pagesWeak TopologySalvador Sánchez PeralesNo ratings yet
- VelsDocument7 pagesVelssuleimanNo ratings yet
- Idris3 PDFDocument15 pagesIdris3 PDFادريس عطيه النيانNo ratings yet
- hw4 SolDocument4 pageshw4 SolemersonNo ratings yet
- Chapter 3Document43 pagesChapter 3Di WuNo ratings yet
- FormulaeDocument16 pagesFormulaeabdul.qaderNo ratings yet
- 6.252 Nonlinear Programming Convergence Analysis of Gradient MethodsDocument9 pages6.252 Nonlinear Programming Convergence Analysis of Gradient MethodsBharti BhagatNo ratings yet
- ADMMDocument34 pagesADMMShuhan QiuNo ratings yet
- FixedpointDocument5 pagesFixedpointAnuradha yadavNo ratings yet
- Ap P A P: N I I N I N I N IDocument38 pagesAp P A P: N I I N I N I N ItusharNo ratings yet
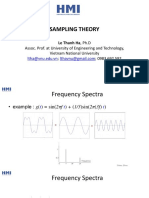
- Digital Image Processing - Sampling TheoryDocument56 pagesDigital Image Processing - Sampling TheoryLong Đặng HoàngNo ratings yet
- Necessary and Sufficient Conditions For Optimality of Primal-Dual PairsDocument17 pagesNecessary and Sufficient Conditions For Optimality of Primal-Dual PairsSamuel Alfonzo Gil BarcoNo ratings yet
- Calculus II - Exam 1 - Spring 2008: March 6, 2008Document7 pagesCalculus II - Exam 1 - Spring 2008: March 6, 2008laguiiniNo ratings yet
- OprisanDocument8 pagesOprisanLovinf FlorinNo ratings yet
- Lec Fokker PlanckDocument60 pagesLec Fokker PlanckAmit RathvaNo ratings yet
- Calculus Ii Spring 2011: Harry Mclaughlin Revised 1/22/11 Edited byDocument25 pagesCalculus Ii Spring 2011: Harry Mclaughlin Revised 1/22/11 Edited byDeon RobinsonNo ratings yet
- Orthogonal Functions - Function ApproximationDocument29 pagesOrthogonal Functions - Function ApproximationVayo SonyNo ratings yet
- Inequality Constraints IntroducedDocument19 pagesInequality Constraints IntroducedtapasNo ratings yet
- Stats 231 / CS229T Homework 3 SolutionsDocument6 pagesStats 231 / CS229T Homework 3 SolutionsgabrieleNo ratings yet
- Review1 MergedDocument144 pagesReview1 MergedJom KantaponNo ratings yet
- Quantum EM Fields and the Photon PropagatorDocument21 pagesQuantum EM Fields and the Photon PropagatorSupertj666No ratings yet
- 10-725/36-725 Optimization Midterm Exam: NameDocument10 pages10-725/36-725 Optimization Midterm Exam: NamehassanNo ratings yet
- Lecture 05 - UnconstrainedDocument21 pagesLecture 05 - Unconstrainedbillie quantNo ratings yet
- Set 2Document4 pagesSet 2Gaffar KadirNo ratings yet
- On k-Generalized ψ-Hilfer Boundary Value Problems with Retardation and AnticipationDocument18 pagesOn k-Generalized ψ-Hilfer Boundary Value Problems with Retardation and AnticipationwalidNo ratings yet
- PDFDocument66 pagesPDFgajaNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- App ThermoDocument1 pageApp ThermomansoorNo ratings yet
- Office Credential & OS Activation ProcessDocument8 pagesOffice Credential & OS Activation ProcessmansoorNo ratings yet
- Therm ApplidDocument1 pageTherm ApplidmansoorNo ratings yet
- Wind Plant Perf2Document4 pagesWind Plant Perf2Vinod DhanapalNo ratings yet
- Chapter 6Document46 pagesChapter 6mansoorNo ratings yet
- Types of Electrical Power & EnergyDocument6 pagesTypes of Electrical Power & EnergyIrfan UllahNo ratings yet
- SOP MAINTENANCE FINAL - Part2Document55 pagesSOP MAINTENANCE FINAL - Part2mansoorNo ratings yet
- App ThermoDocument1 pageApp ThermomansoorNo ratings yet
- General ContentsDocument2 pagesGeneral ContentsmansoorNo ratings yet
- NTDC P&I SKILLS UPGRADING TRAINING PROGRAMDocument46 pagesNTDC P&I SKILLS UPGRADING TRAINING PROGRAMmansoor0% (1)
- ThermalDocument1 pageThermalmansoorNo ratings yet
- ETAP - Building One Line Diagram PDFDocument5 pagesETAP - Building One Line Diagram PDFTareq_EELNo ratings yet
- ThermoDocument1 pageThermomansoorNo ratings yet
- Chapter-8 Electical Energy, Its Components & Energy in Electric CircuitDocument7 pagesChapter-8 Electical Energy, Its Components & Energy in Electric CircuitIrfan UllahNo ratings yet
- Chapter-1 Energy Meters Testing ContentsDocument2 pagesChapter-1 Energy Meters Testing ContentsIrfan UllahNo ratings yet
- ThermoDocument1 pageThermomansoorNo ratings yet
- ThermodynamicsDocument1 pageThermodynamicsmansoorNo ratings yet
- Machine Transformations: J. MccalleyDocument24 pagesMachine Transformations: J. MccalleymansoorNo ratings yet
- Duality PDFDocument30 pagesDuality PDFdmp130No ratings yet
- Islamic Studies Mcqs in PDFDocument58 pagesIslamic Studies Mcqs in PDFTeabb MasoomNo ratings yet
- InstructionsDocument1 pageInstructionsMohamed HassanNo ratings yet
- Floatrow PDFDocument107 pagesFloatrow PDFmansoorNo ratings yet
- ReadmeDocument1 pageReadmemansoorNo ratings yet
- Applied ThermodydnamicsDocument1 pageApplied ThermodydnamicsmansoorNo ratings yet
- Latex For Report Writing HFDocument28 pagesLatex For Report Writing HFPankaj KhatriNo ratings yet
- GRE Physics Test: Practice BookDocument91 pagesGRE Physics Test: Practice BookGalo CandelaNo ratings yet
- Protectionoftransmissionlinesencrypted 141126021142 Conversion Gate01Document39 pagesProtectionoftransmissionlinesencrypted 141126021142 Conversion Gate01mansoorNo ratings yet
- TrnsLine PDFDocument495 pagesTrnsLine PDFMomayKradookkradicNo ratings yet
- InstructionsDocument1 pageInstructionsMohamed HassanNo ratings yet
- DDCO Module 1Document25 pagesDDCO Module 1vijaylaxmi-cseNo ratings yet
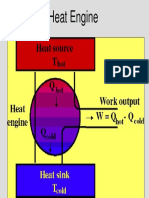
- Teaching Case Study: Heat TransferDocument4 pagesTeaching Case Study: Heat TransferJulendra AriatedjaNo ratings yet
- ACT math practice test 6 solutionsDocument9 pagesACT math practice test 6 solutionsAmal SalemNo ratings yet
- JEE Test SeriesDocument24 pagesJEE Test SeriesUmesh SharmaNo ratings yet
- Vectors and Scalars: John O'Connor St. Farnan's PPS ProsperousDocument15 pagesVectors and Scalars: John O'Connor St. Farnan's PPS ProsperousTemesgen BihonegnNo ratings yet
- Longitudinal Dynamics: 6.1 Response To ControlsDocument10 pagesLongitudinal Dynamics: 6.1 Response To ControlsAlbertoNo ratings yet
- Mcqs 1Document12 pagesMcqs 1Ralitsa DeeDee Wilcox100% (1)
- Divisibility Rules Lesson - Using Rules for 2, 5, 10Document13 pagesDivisibility Rules Lesson - Using Rules for 2, 5, 10Melyn BustamanteNo ratings yet
- Os Lab Exno 1 To 5Document38 pagesOs Lab Exno 1 To 5Vairavel ChenniyappanNo ratings yet
- Unexpired ReserveDocument16 pagesUnexpired ReservePreethaNo ratings yet
- MX3D BridgeDocument7 pagesMX3D BridgeJanko Vukicevic100% (1)
- PMPH120 - Lab 3 - SHM and Spring Constant - SolutionsDocument11 pagesPMPH120 - Lab 3 - SHM and Spring Constant - SolutionsTavonga ShokoNo ratings yet
- Hidden Figures Movie Kit1Document2 pagesHidden Figures Movie Kit1AlexanderRisso100% (1)
- Grade 9: Federal Democrati C Republi C OF Ethi OPI A MI NI Stry OF Educati ONDocument324 pagesGrade 9: Federal Democrati C Republi C OF Ethi OPI A MI NI Stry OF Educati ONየየጁ ልጅ እኔNo ratings yet
- Oscillations IDocument44 pagesOscillations Iapi-259436196No ratings yet
- PeterDocument30 pagesPeterJoão BeliniNo ratings yet
- Data MineDocument31 pagesData Mineninoronald100% (2)
- C++ Quick GuideDocument98 pagesC++ Quick GuideAman KumarNo ratings yet
- Solution Manual For Modern Semiconductor Devices For Integrated Circuits 1st Ed - Chenming C. HuDocument18 pagesSolution Manual For Modern Semiconductor Devices For Integrated Circuits 1st Ed - Chenming C. Hu일팔일공일오이오 윤현서0% (1)
- COBOL Quick RefresherDocument39 pagesCOBOL Quick Refresherpeeyush_pce2010No ratings yet
- Input-Output Theory With Quantum PulsesDocument7 pagesInput-Output Theory With Quantum PulsesLucas RibeiroNo ratings yet
- Probability ScaleDocument4 pagesProbability ScaleMichaelKokolakisNo ratings yet
- Machine Learning in Antenna Design An Overview On Machine Learning Concept and AlgorithmsDocument9 pagesMachine Learning in Antenna Design An Overview On Machine Learning Concept and AlgorithmssagarduttaNo ratings yet
- Esm410 Assignment 1 Portfolio VersionDocument12 pagesEsm410 Assignment 1 Portfolio Versionapi-282084309No ratings yet
- G7 U5m10 Te PDFDocument34 pagesG7 U5m10 Te PDFAhmed SalemNo ratings yet
- Roadmap For Quant 1705217537Document10 pagesRoadmap For Quant 1705217537VaibhavNo ratings yet
- Chapter 2 Fundamental Simulation ConceptsDocument50 pagesChapter 2 Fundamental Simulation ConceptsHrishikesh WaghNo ratings yet
- G.C.E. Advanced Level – 2017 Theory Exam: Basic Mathematics QuestionsDocument20 pagesG.C.E. Advanced Level – 2017 Theory Exam: Basic Mathematics Questionswissam riyasNo ratings yet
- Chapter 3 Problem Solving and ReasoningDocument83 pagesChapter 3 Problem Solving and ReasoningJOSE BENAVENTENo ratings yet
- 7 19 Updated Grade 11 Students Online Schedule 2021 2022 1st SemDocument8 pages7 19 Updated Grade 11 Students Online Schedule 2021 2022 1st SemAngelo MartinezNo ratings yet