You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
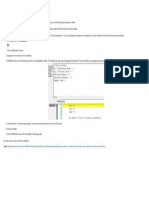
- OS. User Type Not DefinedDocument1 pageOS. User Type Not DefinedFrancis CayananNo ratings yet
- OS. UserDialog EditorDocument1 pageOS. UserDialog EditorFrancis CayananNo ratings yet
- OS. TroubleshootingDocument1 pageOS. TroubleshootingFrancis CayananNo ratings yet
- OS. Type MismatchDocument1 pageOS. Type MismatchFrancis CayananNo ratings yet
- OS. To Test Your MacroDocument1 pageOS. To Test Your MacroFrancis CayananNo ratings yet
- OS. User Type Not DefinedDocument1 pageOS. User Type Not DefinedFrancis CayananNo ratings yet
- OS. To Start A New Macro ProjectDocument1 pageOS. To Start A New Macro ProjectFrancis CayananNo ratings yet
- OS. TroubleshootingDocument1 pageOS. TroubleshootingFrancis CayananNo ratings yet
- OS. Type MismatchDocument1 pageOS. Type MismatchFrancis CayananNo ratings yet
- OS. To Test Your MacroDocument1 pageOS. To Test Your MacroFrancis CayananNo ratings yet
- OS. UserDialog EditorDocument1 pageOS. UserDialog EditorFrancis CayananNo ratings yet
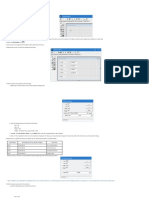
- OS. To Create The Dialog FormDocument2 pagesOS. To Create The Dialog FormFrancis CayananNo ratings yet
- OS. Using Macros in STAAD - ProDocument1 pageOS. Using Macros in STAAD - ProFrancis CayananNo ratings yet
- OS. To Run A Linked MacroDocument1 pageOS. To Run A Linked MacroFrancis CayananNo ratings yet
- OS. To Run The Frame MacroDocument1 pageOS. To Run The Frame MacroFrancis CayananNo ratings yet
- OS. To Generate The Frame MembersDocument1 pageOS. To Generate The Frame MembersFrancis CayananNo ratings yet
- OS. To Start A New Macro Project1Document1 pageOS. To Start A New Macro Project1Francis CayananNo ratings yet
- OS. To Dimension The Variables and Add Initial Values in The DialogDocument2 pagesOS. To Dimension The Variables and Add Initial Values in The DialogFrancis CayananNo ratings yet
- OS. To Create The Text Fields and LabelsDocument3 pagesOS. To Create The Text Fields and LabelsFrancis CayananNo ratings yet
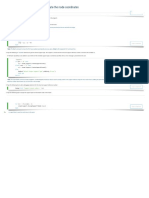
- OS. To Get The User ValuesDocument1 pageOS. To Get The User ValuesFrancis CayananNo ratings yet
- OS. To Add The Dialog ButtonsDocument2 pagesOS. To Add The Dialog ButtonsFrancis CayananNo ratings yet
- OS. To Create The Text Fields and LabelsDocument3 pagesOS. To Create The Text Fields and LabelsFrancis CayananNo ratings yet
- OS. STAAD NomenclatureDocument1 pageOS. STAAD NomenclatureFrancis CayananNo ratings yet
- OS. To Initialize OpenSTAAD and Calculate The Node CoordinatesDocument2 pagesOS. To Initialize OpenSTAAD and Calculate The Node CoordinatesFrancis CayananNo ratings yet
- OS. To Import An Existing MacroDocument1 pageOS. To Import An Existing MacroFrancis CayananNo ratings yet
- OS. To Add The Macro To The List of User ToolsDocument1 pageOS. To Add The Macro To The List of User ToolsFrancis CayananNo ratings yet
- OS. STAAD - Pro Script Editor WindowDocument1 pageOS. STAAD - Pro Script Editor WindowFrancis CayananNo ratings yet
- OS. Simple STAAD - Pro MacroDocument3 pagesOS. Simple STAAD - Pro MacroFrancis CayananNo ratings yet
- OS. Retrieve Dynamic OutputDocument1 pageOS. Retrieve Dynamic OutputFrancis CayananNo ratings yet
- OS. To Create Support OptionsDocument2 pagesOS. To Create Support OptionsFrancis CayananNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Wk1 - The Scientific Method LabDocument9 pagesWk1 - The Scientific Method LabOmar MorenoNo ratings yet
- HydraulicsDocument5 pagesHydraulicsbakrichodNo ratings yet
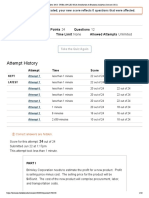
- Problem Set D: Attempt HistoryDocument10 pagesProblem Set D: Attempt HistoryHenryNo ratings yet
- SX004a-En-EU-Example - Pinned Column Using Non Slender H-Section or RHSDocument5 pagesSX004a-En-EU-Example - Pinned Column Using Non Slender H-Section or RHSKen OkoyeNo ratings yet
- Adding and Subtraction Fractions With Unlike DenominatorsDocument2 pagesAdding and Subtraction Fractions With Unlike Denominatorsapi-291376922No ratings yet
- Lesson 2 Variables in ResearchDocument19 pagesLesson 2 Variables in ResearchJake ManzanoNo ratings yet
- 4.ResM Non Stat CodingDocument9 pages4.ResM Non Stat CodingSwati RathiNo ratings yet
- An Investigation On Gas Lift Performance Curve in An Oil Producing Well (Deni Saepudin)Document16 pagesAn Investigation On Gas Lift Performance Curve in An Oil Producing Well (Deni Saepudin)Atrian RahadiNo ratings yet
- Calculus Abstract 1 PDFDocument3 pagesCalculus Abstract 1 PDFChristian Oliver RonquilloNo ratings yet
- A Neural Network Approach For Early Cost Estimation of Structural Systems of BuildingsDocument8 pagesA Neural Network Approach For Early Cost Estimation of Structural Systems of BuildingsHai Dai GiaNo ratings yet
- S&T HEX Design Kern ModelDocument4 pagesS&T HEX Design Kern ModelWasim RazaNo ratings yet
- Common ConnectorsDocument2 pagesCommon Connectors2183063696No ratings yet
- Gaussian & Gaussview: Shubin Liu, Ph.D. Research Computing Center, Its University of North Carolina at Chapel HillDocument86 pagesGaussian & Gaussview: Shubin Liu, Ph.D. Research Computing Center, Its University of North Carolina at Chapel HillRAMKUMARNo ratings yet
- Robert Talbert Statement of Teaching Philosophy DRAFTDocument2 pagesRobert Talbert Statement of Teaching Philosophy DRAFTRobert TalbertNo ratings yet
- Dataforth Elit PDFDocument310 pagesDataforth Elit PDFDougie ChanNo ratings yet
- Mathematics 11 Guide (2014)Document231 pagesMathematics 11 Guide (2014)HumairaNo ratings yet
- The Latest Research Progress On Spectral ClusteringDocument10 pagesThe Latest Research Progress On Spectral ClusteringAnwar ShahNo ratings yet
- Lesson Plan Percent NoncalcDocument1 pageLesson Plan Percent NoncalcJonathan RobinsonNo ratings yet
- MIT 521 Data Structures and AlgorithmDocument27 pagesMIT 521 Data Structures and AlgorithmAshraf Uzzaman SalehNo ratings yet
- Stability of Tapered and Stepped Steel Columns With Initial ImperfectionsDocument10 pagesStability of Tapered and Stepped Steel Columns With Initial ImperfectionskarpagajothimuruganNo ratings yet
- Business Math: Quarter 1 - Module 4: Identifying The Different Kinds of ProportionDocument24 pagesBusiness Math: Quarter 1 - Module 4: Identifying The Different Kinds of ProportionYan Fajota67% (3)
- 2012-01-02 203611 Answers2Document9 pages2012-01-02 203611 Answers2medeepikaNo ratings yet
- Javacc FaqDocument66 pagesJavacc FaqFrederick Bejarano SanchezNo ratings yet
- Theta Geometry TestDocument6 pagesTheta Geometry TestJun Arro Estrella JoestarNo ratings yet
- E04-Ship Geometry & Hydrostatic CalculationsDocument2 pagesE04-Ship Geometry & Hydrostatic Calculationsarise tettehNo ratings yet
- Combine ResultDocument12 pagesCombine Resultpreeti.2405No ratings yet
- 3 Circuit Analysis Using SubcircuitsDocument21 pages3 Circuit Analysis Using SubcircuitsAlejandro Salas VásquezNo ratings yet
- Rural Poverty and Inequality in EthiopiaDocument20 pagesRural Poverty and Inequality in EthiopiaSemalignNo ratings yet
- Example of Perspective TransformationDocument2 pagesExample of Perspective TransformationNitin Suyan PanchalNo ratings yet
- Flanagan Industrial TestsDocument1 pageFlanagan Industrial TestsIsrael Alvarez100% (2)