You might also like
- Ids Ae 2Document9 pagesIds Ae 2Aliya TabassumNo ratings yet
- Clustering Before ClassificationDocument3 pagesClustering Before Classificationmc awartyNo ratings yet
- 20bce2689 VL2022230103435 DaDocument30 pages20bce2689 VL2022230103435 DaRajvansh SinghNo ratings yet
- DattaDeshmukhecs 2014 6892542Document7 pagesDattaDeshmukhecs 2014 6892542Rohit MajumderNo ratings yet
- Ensemble Based Approach For IntrusionDocument8 pagesEnsemble Based Approach For IntrusionKurniabudi ZaimarNo ratings yet
- Survey of Network Anomaly Detection Using Markov ChainDocument7 pagesSurvey of Network Anomaly Detection Using Markov ChainijcseitNo ratings yet
- Robust Data Model For Enhanced Anomaly Detection: R.Ravinder Reddy, Dr.Y Ramadevi, DR.K.V.N SunithaDocument8 pagesRobust Data Model For Enhanced Anomaly Detection: R.Ravinder Reddy, Dr.Y Ramadevi, DR.K.V.N SunithaRavindra ReddyNo ratings yet
- Impact of Outlier Removal and Normalization ApproaDocument6 pagesImpact of Outlier Removal and Normalization ApproaPoojaNo ratings yet
- NIDF: An Ensemble-Inspired Feature Learning Framework For Network Intrusion DetectionDocument4 pagesNIDF: An Ensemble-Inspired Feature Learning Framework For Network Intrusion DetectionLyublyu TebyaNo ratings yet
- Paper-5 Evaluation of Rule Based Machine Learning Algorithms On NSL-KDD DatasetDocument8 pagesPaper-5 Evaluation of Rule Based Machine Learning Algorithms On NSL-KDD DatasetRachel Wheeler100% (1)
- Attribute Normalization in Network Intrusion Detection: Wei Wang Svein J. Knapskog Sylvain GombaultDocument7 pagesAttribute Normalization in Network Intrusion Detection: Wei Wang Svein J. Knapskog Sylvain GombaultGuntur TifNo ratings yet
- An Ensemble Feature Selection Algorithm For Machine Learning Based Intrusion Detection SystemDocument5 pagesAn Ensemble Feature Selection Algorithm For Machine Learning Based Intrusion Detection SystemVo Nguyen Quoc BaoNo ratings yet
- Ijcse V2i3p4Document6 pagesIjcse V2i3p4ISAR-PublicationsNo ratings yet
- A Hybrid System For Reducing The False Alarm Rate of Anomaly Intrusion Detection SystemDocument6 pagesA Hybrid System For Reducing The False Alarm Rate of Anomaly Intrusion Detection Systemashish88bhardwaj_314No ratings yet
- A Survey On Features Election For Intrusion DetectionDocument7 pagesA Survey On Features Election For Intrusion DetectionImrana YaqoubNo ratings yet
- Improved Intrusion Detection Applying Feature Selection Using Rank & Score of Attributes in KDD-99 Data SetDocument44 pagesImproved Intrusion Detection Applying Feature Selection Using Rank & Score of Attributes in KDD-99 Data SetDeepak HarbolaNo ratings yet
- 1 s2.0 S2212017312002964 MainDocument10 pages1 s2.0 S2212017312002964 MainGautham Krishna KbNo ratings yet
- A Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningDocument12 pagesA Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningB AnandNo ratings yet
- IJETR031822Document5 pagesIJETR031822erpublicationNo ratings yet
- IEEE Conference TemplaDocument4 pagesIEEE Conference TemplaAshlesha ShettyNo ratings yet
- Les Statistiques Descriptives Est OujdaDocument4 pagesLes Statistiques Descriptives Est OujdaMouhsine EL MOUDIRNo ratings yet
- Identifying Key Variables For Intrusion Detection Using Soft Computing ParadigmsDocument7 pagesIdentifying Key Variables For Intrusion Detection Using Soft Computing ParadigmsHidayah Husnul Khotimah LagiNo ratings yet
- Grid Search Hyper-Parameter Tuning and K-Means Clustering ToImprove The Decision Tree AccuracyDocument3 pagesGrid Search Hyper-Parameter Tuning and K-Means Clustering ToImprove The Decision Tree AccuracyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Methodology: What Does Data Acquisition Mean?Document6 pagesMethodology: What Does Data Acquisition Mean?Nithish K mNo ratings yet
- Model For Intrusion Detection System With Data MiningDocument4 pagesModel For Intrusion Detection System With Data MiningIjarcet JournalNo ratings yet
- Ieee - Intrusion Detection System Using NeuralDocument8 pagesIeee - Intrusion Detection System Using NeuralDheresh SoniNo ratings yet
- A Survey On Intrusion Detection System Using Machine Learning TechniquesDocument7 pagesA Survey On Intrusion Detection System Using Machine Learning TechniquesIJRASETPublicationsNo ratings yet
- Analysis and Classification of Intrusion Detection For Synthetic Neural Networks Using Machine Language StrategiesDocument5 pagesAnalysis and Classification of Intrusion Detection For Synthetic Neural Networks Using Machine Language StrategiesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- An Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierDocument9 pagesAn Ensemble Design of Intrusion Detection System For Handling Uncertainty Using Neutrosophic Logic ClassifierMia AmaliaNo ratings yet
- Network Intrusion Detection SystemDocument46 pagesNetwork Intrusion Detection Systemsachin mohanNo ratings yet
- Attack Detection Availing Feature Discretion Using Random Forest ClassifierDocument15 pagesAttack Detection Availing Feature Discretion Using Random Forest ClassifiercseijNo ratings yet
- Network Traffic Intrusion Detection System Using Decision Tree & K-Means Clustering AlgorithmDocument3 pagesNetwork Traffic Intrusion Detection System Using Decision Tree & K-Means Clustering AlgorithmInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Feature Selection Based On Fuzzy EntropyDocument5 pagesFeature Selection Based On Fuzzy EntropyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Feature Selection For Effective Anomaly-Based Intrusion DetectionDocument5 pagesFeature Selection For Effective Anomaly-Based Intrusion DetectionEka NafrilyanNo ratings yet
- Case Study 219302405Document14 pagesCase Study 219302405nishantjain2k03No ratings yet
- (IJCST-V10I4P14) :manish Chava, Aman Agarwal, DR Radha KDocument5 pages(IJCST-V10I4P14) :manish Chava, Aman Agarwal, DR Radha KEighthSenseGroupNo ratings yet
- Packet and Flow Based Network Intrusion DatasetDocument12 pagesPacket and Flow Based Network Intrusion DatasetAnonymous N22tyB6UNNo ratings yet
- Ensemble Models For Intrusion Detection System ClassificationDocument15 pagesEnsemble Models For Intrusion Detection System ClassificationKurniabudi ZaimarNo ratings yet
- A Robust and Efficient Real Time Network Intrusion Detection System Using Artificial Neural Network in Data MiningDocument10 pagesA Robust and Efficient Real Time Network Intrusion Detection System Using Artificial Neural Network in Data MiningijitcsNo ratings yet
- My DatasettttDocument4 pagesMy DatasettttSaranya DhilipkumarNo ratings yet
- IRJET Intrusion Detection System Using SDocument6 pagesIRJET Intrusion Detection System Using Sanand.dhawaleNo ratings yet
- Implementation Paper On Network DataDocument6 pagesImplementation Paper On Network DataIJRASETPublicationsNo ratings yet
- Feature Engineering: Short Study: Indian Institute of Space Science and Technology, Department of MathematicsDocument6 pagesFeature Engineering: Short Study: Indian Institute of Space Science and Technology, Department of MathematicsgociNo ratings yet
- Paper 4 PDFDocument6 pagesPaper 4 PDFindiraNo ratings yet
- An Efficient Intrusion Detection System With Custom Features Using FPA-Gradient Boost Machine Learning AlgorithmDocument17 pagesAn Efficient Intrusion Detection System With Custom Features Using FPA-Gradient Boost Machine Learning AlgorithmAIRCC - IJCNCNo ratings yet
- K Nearest Neighbor Based Model For Intrusion Detection SystemDocument5 pagesK Nearest Neighbor Based Model For Intrusion Detection SystemLovepreet KaurNo ratings yet
- BdaanormalydetectionDocument7 pagesBdaanormalydetectionahasanova627No ratings yet
- Review of Data Mining Classification Techniques: Shraddha Sharma & Ankita SaxenaDocument8 pagesReview of Data Mining Classification Techniques: Shraddha Sharma & Ankita SaxenaTJPRC PublicationsNo ratings yet
- IDS in Telecommunication Network Using PCADocument11 pagesIDS in Telecommunication Network Using PCAAIRCC - IJCNCNo ratings yet
- Ids IN FUZZY LOGICDocument11 pagesIds IN FUZZY LOGICArunNo ratings yet
- V5i2 1541 PDFDocument3 pagesV5i2 1541 PDF315126510032 CHATLA VISISHTANo ratings yet
- Human Resource Management by Machine Learning AlgorithmsDocument6 pagesHuman Resource Management by Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Paper 3 PDFDocument5 pagesPaper 3 PDFindiraNo ratings yet
- 5 CS 03 IjsrcseDocument4 pages5 CS 03 IjsrcseEdwardNo ratings yet
- Effective and Efficient Approach in IoT Botnet DetectionDocument12 pagesEffective and Efficient Approach in IoT Botnet DetectionMohammad SayelNo ratings yet
- WS42017proceedings - Split and MergedDocument12 pagesWS42017proceedings - Split and MergedManan HudeNo ratings yet
- Wang Et AlDocument10 pagesWang Et Alkiruthick prasathNo ratings yet
- Anomaly Detection by Using CFS Subset and Neural Network With WEKA ToolsDocument8 pagesAnomaly Detection by Using CFS Subset and Neural Network With WEKA ToolsShahid AzeemNo ratings yet
- Network Intrusion Detection Based On Fuzzy LogicDocument7 pagesNetwork Intrusion Detection Based On Fuzzy LogicArnav GudduNo ratings yet
- DATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABNo ratings yet
- Web Engineering: With Effect From The Academic Year 2020-21Document2 pagesWeb Engineering: With Effect From The Academic Year 2020-21Ravindra ReddyNo ratings yet
- Mamatha ChinthareddyDocument11 pagesMamatha ChinthareddyRavindra ReddyNo ratings yet
- Association and Correlation Analysis For Predicting The Anomaly in The Stock MarketDocument7 pagesAssociation and Correlation Analysis For Predicting The Anomaly in The Stock MarketRavindra ReddyNo ratings yet
- Faculty Individual - 2021-22 - Odd Semester - 21.12.2021 - First Year 31.1.2021Document1 pageFaculty Individual - 2021-22 - Odd Semester - 21.12.2021 - First Year 31.1.2021Ravindra ReddyNo ratings yet
- G.O.Ms - No. 1, Dated 01.01.2022 - COVID-19Document2 pagesG.O.Ms - No. 1, Dated 01.01.2022 - COVID-19Ravindra ReddyNo ratings yet
- INDIA - 2022 Paper 159Document1 pageINDIA - 2022 Paper 159Ravindra ReddyNo ratings yet
- 1.implement FIND-S Algorithm: DesriptionDocument19 pages1.implement FIND-S Algorithm: DesriptionRavindra ReddyNo ratings yet
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyNo ratings yet
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyNo ratings yet
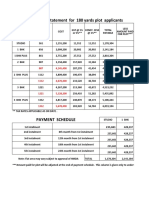
- COST STATEMENT FOR 180 SyDocument3 pagesCOST STATEMENT FOR 180 SyRavindra ReddyNo ratings yet
- Pre Annual Grammar Revision Worksheet 2021-22 Answer KeyDocument3 pagesPre Annual Grammar Revision Worksheet 2021-22 Answer KeyRavindra ReddyNo ratings yet
- Grade 3 - Math Pre Annual Assessment Revision WorksheetDocument6 pagesGrade 3 - Math Pre Annual Assessment Revision WorksheetRavindra ReddyNo ratings yet
- Annex - II (Revised-4)Document1 pageAnnex - II (Revised-4)Ravindra ReddyNo ratings yet
- Chapter 19: Distributed DatabasesDocument125 pagesChapter 19: Distributed DatabasesNhb SohelNo ratings yet
- C and DS ContentDocument380 pagesC and DS ContentRavindra Reddy50% (2)
- Robust Data Model For Enhanced Anomaly Detection: R.Ravinder Reddy, Dr.Y Ramadevi, DR.K.V.N SunithaDocument8 pagesRobust Data Model For Enhanced Anomaly Detection: R.Ravinder Reddy, Dr.Y Ramadevi, DR.K.V.N SunithaRavindra ReddyNo ratings yet
- 8 WeekDocument5 pages8 WeekRavindra ReddyNo ratings yet
- Annex - II (Revised-4)Document1 pageAnnex - II (Revised-4)Ravindra ReddyNo ratings yet
- C and DS ContentDocument380 pagesC and DS ContentRavindra Reddy50% (2)
- Ch01 NetSec5eDocument31 pagesCh01 NetSec5eSukthanaPongmaNo ratings yet
- A Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetDocument10 pagesA Genetic Algorithm Based Elucidation For Improving Intrusion Detection Through Condensed Feature Set by KDD 99 Data SetRavindra ReddyNo ratings yet
- Privacy Enhanced Intrusion Detection: 1.1 AbstractDocument14 pagesPrivacy Enhanced Intrusion Detection: 1.1 AbstractRavindra ReddyNo ratings yet
- 1 s2.0 S0267364916300802 MainDocument19 pages1 s2.0 S0267364916300802 MainRavindra ReddyNo ratings yet
- Case Problem 2 Yeager National BankDocument4 pagesCase Problem 2 Yeager National BankSomething ChicNo ratings yet
- SEM 3 - GE3 - Numerical Analysis 1Document16 pagesSEM 3 - GE3 - Numerical Analysis 1Neelarka RoyNo ratings yet
- CS KOM Fin Jan2021-V2Document1 pageCS KOM Fin Jan2021-V2Osman Agâh YILDIRIMNo ratings yet
- Balaji Opt Lecture8 ActDocument72 pagesBalaji Opt Lecture8 ActHalwa KhoiriNo ratings yet
- Assignment-1 - 1 - Che 255Document1 pageAssignment-1 - 1 - Che 255Maame DurowaaNo ratings yet
- Cs502 Collection of Old PapersDocument49 pagesCs502 Collection of Old Paperscs619finalproject.comNo ratings yet
- Pattern Recognitionand Neural NetworksDocument12 pagesPattern Recognitionand Neural NetworksJoberthFirminoGambatiNo ratings yet
- Design of IIR FiltersDocument31 pagesDesign of IIR FiltersJagdeep RahulNo ratings yet
- Ai Project DocumentationDocument28 pagesAi Project DocumentationR -BrotHERsNo ratings yet
- Randomness in AnyLogic ModelsDocument22 pagesRandomness in AnyLogic ModelsSergiy OstapchukNo ratings yet
- Fuzzy Relation & Neural NetsDocument38 pagesFuzzy Relation & Neural NetsvpkvikasNo ratings yet
- 2.2.1 Introduction To QueuesDocument12 pages2.2.1 Introduction To QueuesSomesh RamanNo ratings yet
- Generative Adversarial Networks Seminar ReportDocument11 pagesGenerative Adversarial Networks Seminar ReportJohn Doe33% (3)
- Thermodynamic CyclesDocument13 pagesThermodynamic CyclesAshish KumarNo ratings yet
- Tuan Tran - UTeach CSP-Heuristics HandoutDocument3 pagesTuan Tran - UTeach CSP-Heuristics HandoutTuan TranNo ratings yet
- Syllabus - CS 231N PDFDocument1 pageSyllabus - CS 231N PDFvonacoc49No ratings yet
- IMU 703-Advanced Engineering Mathematics Fall 2021 Department of Civil EngineeringDocument1 pageIMU 703-Advanced Engineering Mathematics Fall 2021 Department of Civil Engineeringvatan tosunNo ratings yet
- Simplex MethodDocument16 pagesSimplex MethodShantanu Dutta100% (1)
- DE Chapter 9Document4 pagesDE Chapter 9Catherine C. MuldongNo ratings yet
- wst02 01 Que 20240113Document28 pageswst02 01 Que 20240113amjadasha11No ratings yet
- The Application of Successive Over Relaxation To The Normalization of Multitemporal Satellite ImagesDocument20 pagesThe Application of Successive Over Relaxation To The Normalization of Multitemporal Satellite ImagesGabriel YedayaNo ratings yet
- Eeezg573 May03 An PDFDocument2 pagesEeezg573 May03 An PDFSaurabh Jaiswal JassiNo ratings yet
- Quantitative Techniques in Management, N. D. Vohra: Operations Research-Dr. Pankaj Dixit, Mr. A.K.PandeyDocument2 pagesQuantitative Techniques in Management, N. D. Vohra: Operations Research-Dr. Pankaj Dixit, Mr. A.K.PandeyA GNo ratings yet
- Lesson 7 - Regression AnalysisDocument57 pagesLesson 7 - Regression AnalysiskxeNo ratings yet
- Demystifying VPNDocument12 pagesDemystifying VPNMarcos Aurélio RodriguesNo ratings yet
- Mit18 06scf11 Ses2.5solDocument3 pagesMit18 06scf11 Ses2.5solSarthi GNo ratings yet
- Project Presentation Template - (Review-I)Document19 pagesProject Presentation Template - (Review-I)Pradhumnya RangdaleNo ratings yet
- Solving A System of Linear Equations: ProblemDocument4 pagesSolving A System of Linear Equations: ProblemAqsa ZafarNo ratings yet
- Nonlinear SystemsDocument14 pagesNonlinear SystemsRasheed KibriaNo ratings yet
- Mathematical Modeling of Chemical ProcessesDocument27 pagesMathematical Modeling of Chemical ProcessesYonas AddamNo ratings yet