You might also like
- CocoonDocument37 pagesCocoonairjajaNo ratings yet
- Alkacon OpenCms 7 TechnicalDocument27 pagesAlkacon OpenCms 7 Technicalshekhar majumdarNo ratings yet
- DOM PresentationDocument23 pagesDOM Presentationraviteja595No ratings yet
- What Is AJAX ?Document24 pagesWhat Is AJAX ?anon-783654No ratings yet
- WebSphere DataPower SOA Appliances and XSLT Part 1Document23 pagesWebSphere DataPower SOA Appliances and XSLT Part 1Gema Alcolado AyusoNo ratings yet
- Representing Web Data: Unit IvDocument15 pagesRepresenting Web Data: Unit IvAkash Rudra PaulNo ratings yet
- 5 Java ParserDocument33 pages5 Java Parsersuresh1130No ratings yet
- Artificial IntelligenceDocument34 pagesArtificial IntelligenceAbuzer ZulkiflyNo ratings yet
- AJAXDocument6 pagesAJAXKarthick SundaramNo ratings yet
- Ajax PresentationDocument20 pagesAjax Presentationsree_rockzzNo ratings yet
- AJAXDocument20 pagesAJAXbinzbinzNo ratings yet
- XML Processing Performance: The Promise of XMLDocument6 pagesXML Processing Performance: The Promise of XMLSumeetha PonnamNo ratings yet
- Web ServicesDocument49 pagesWeb ServicesKishore Kumar0% (1)
- Jakarta Struts: TwinclingDocument68 pagesJakarta Struts: Twinclingtushar886No ratings yet
- LASICT Programming Q4 w304.15 19.24Document11 pagesLASICT Programming Q4 w304.15 19.24Godfrye Blando WenceslaoNo ratings yet
- What Is Struts?Document55 pagesWhat Is Struts?sjkarthis2011No ratings yet
- PresentationDocument156 pagesPresentationRaj SNo ratings yet
- Chapter 33 - Active Server Pages (ASP) : 2004 Prentice Hall, Inc. All Rights ReservedDocument102 pagesChapter 33 - Active Server Pages (ASP) : 2004 Prentice Hall, Inc. All Rights Reservedapi-3760405100% (2)
- Basic Objects Necessary - Setting Up The Xmlhttprequest Object - Making The Call - How The Server Responds - Using The Reply - XML BasicsDocument35 pagesBasic Objects Necessary - Setting Up The Xmlhttprequest Object - Making The Call - How The Server Responds - Using The Reply - XML BasicschyonNo ratings yet
- WebxDocument8 pagesWebxQuick SilverNo ratings yet
- XML Usage in DB2Document50 pagesXML Usage in DB2sp40694No ratings yet
- Essbase 11-1-2 MetaData Export To XML v3Document9 pagesEssbase 11-1-2 MetaData Export To XML v3ankhareNo ratings yet
- MyFaces TutorialDocument192 pagesMyFaces Tutorialmadan100% (7)
- Jasper Reports SessionDocument20 pagesJasper Reports SessionkatrinakwanNo ratings yet
- JAXBDocument39 pagesJAXBHayrol ReyesNo ratings yet
- Introduction To AJAX: Chapter 10 (Text Book)Document49 pagesIntroduction To AJAX: Chapter 10 (Text Book)Afnan Al-SubaihinNo ratings yet
- Chapter 33 - Active Server Pages (ASP) : 2004 Prentice Hall, Inc. All Rights ReservedDocument102 pagesChapter 33 - Active Server Pages (ASP) : 2004 Prentice Hall, Inc. All Rights ReservedSelva GaneshNo ratings yet
- Xapp Writer S Guide v2Document33 pagesXapp Writer S Guide v2Diego BezerraNo ratings yet
- JSP (Java Server Pages)Document47 pagesJSP (Java Server Pages)Yash BhiseNo ratings yet
- ADF View and ControllerDocument130 pagesADF View and ControllerdaJanaLaNaNo ratings yet
- Ajax 101Document59 pagesAjax 101Suraj RajendraNo ratings yet
- Cse AjaxDocument17 pagesCse AjaxSravaniNo ratings yet
- NotesDocument12 pagesNotesChris HarrisNo ratings yet
- Technologies For Building Grids: 15 October 2004Document48 pagesTechnologies For Building Grids: 15 October 2004BARUTI JUMANo ratings yet
- XML in Oracle9iDocument48 pagesXML in Oracle9ivietmeNo ratings yet
- Web Services: Martin Senger Senger@ebi - Ac.ukDocument36 pagesWeb Services: Martin Senger Senger@ebi - Ac.ukanon_174996872No ratings yet
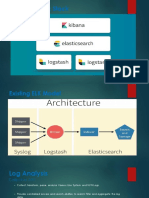
- Elasticsearch, Logstash and KibanaDocument11 pagesElasticsearch, Logstash and KibanaSachin JainNo ratings yet
- Binding Between XML Schema and Java Classes (JAXB)Document79 pagesBinding Between XML Schema and Java Classes (JAXB)Huỳnh Thanh TiếnNo ratings yet
- XML, Web Service and SOADocument10 pagesXML, Web Service and SOAParthaSarathiSamantaNo ratings yet
- BH Eu 13 XML Data Osipov SlidesDocument47 pagesBH Eu 13 XML Data Osipov SlidesMarkNo ratings yet
- AjaxDocument7 pagesAjaxUsman AziZNo ratings yet
- Intro To Apache AxisDocument45 pagesIntro To Apache AxisAnkur B. RoyNo ratings yet
- Integration With Oracle's WMS and MSCA: White PaperDocument7 pagesIntegration With Oracle's WMS and MSCA: White Papergopalkhandelwal1234No ratings yet
- Java Servlets Java Server Pages (JSP)Document41 pagesJava Servlets Java Server Pages (JSP)Jaturong SuwanchehakunNo ratings yet
- SR-286: Portlet Specification 2.0Document6 pagesSR-286: Portlet Specification 2.0kameshwar2004No ratings yet
- Web 2.0 and Ajax With JavaDocument36 pagesWeb 2.0 and Ajax With JavaAdarshNo ratings yet
- TomcatDocument36 pagesTomcatBrahma Botlagunta100% (1)
- Agenda JasperDocument10 pagesAgenda JaspersmartabhiNo ratings yet
- 11 AjaxDocument35 pages11 Ajaxamme_puspitaNo ratings yet
- Rich Internet Application Technology: AJAX Is Based On Open StandardsDocument5 pagesRich Internet Application Technology: AJAX Is Based On Open StandardsAnonymous rcmeSfj5No ratings yet
- Introduction To XML 110130061644 Phpapp02Document56 pagesIntroduction To XML 110130061644 Phpapp02J Mani VannanNo ratings yet
- Using The Javascript Console For Development and AdministrationDocument26 pagesUsing The Javascript Console For Development and AdministrationpmrreddyNo ratings yet
- SCWCD HintsDocument8 pagesSCWCD Hintsapi-3759996No ratings yet
- Tomcat Architecture Training Ver 1.5Document88 pagesTomcat Architecture Training Ver 1.5SNo ratings yet
- Seminar On: Submitted To: Submitted byDocument17 pagesSeminar On: Submitted To: Submitted byAjay PariharNo ratings yet
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessFrom EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo ratings yet
- Parallel Test Technology: The New Paradigm For Parametric TestingDocument66 pagesParallel Test Technology: The New Paradigm For Parametric Testinglusoegyi 1919No ratings yet
- XF Series - 75XF3ES 75XF3C 55XF3E 49XF3E Datasheet (Low) - LG Digital Signage - 200506Document8 pagesXF Series - 75XF3ES 75XF3C 55XF3E 49XF3E Datasheet (Low) - LG Digital Signage - 200506cesarobeso83No ratings yet
- Intr To Problem SolvingDocument26 pagesIntr To Problem SolvingNarendran SNo ratings yet
- Transfer Learning in Deep ReinforcementDocument20 pagesTransfer Learning in Deep Reinforcementhan zhouNo ratings yet
- Data Engineering With PythonDocument357 pagesData Engineering With PythonFelipe A. Pérez100% (3)
- Distributed Systems Midterm ReviewDocument12 pagesDistributed Systems Midterm Reviewhussiandavid26No ratings yet
- KPS180SFLSB - Gram Process Kps Blast Chillers and Freezers Operating InstructionsDocument33 pagesKPS180SFLSB - Gram Process Kps Blast Chillers and Freezers Operating InstructionsYutt WattNo ratings yet
- Extended Reality: Seminar Presentation ONDocument15 pagesExtended Reality: Seminar Presentation ONKeerthi MulintiNo ratings yet
- SIS Requirements For Successful Operation and MaintenanceDocument6 pagesSIS Requirements For Successful Operation and MaintenanceQazi AazadNo ratings yet
- OaerrorDocument18 pagesOaerrorraNo ratings yet
- JournalDev - How To Replace Values Using REPLACE in RDocument6 pagesJournalDev - How To Replace Values Using REPLACE in RSílvia AmadoriNo ratings yet
- Portable Computer Group HW Department: First International Computer, IncDocument50 pagesPortable Computer Group HW Department: First International Computer, Incchiquinho77No ratings yet
- Rached Boubaker: Odoo DeveloperDocument4 pagesRached Boubaker: Odoo DeveloperAymenNo ratings yet
- STS Lesson 13Document61 pagesSTS Lesson 13Diana Silva HernandezNo ratings yet
- BrusDocument10 pagesBrusGloriany MiguelNo ratings yet
- Install LogDocument5 pagesInstall Logjohn-alexander-gonzalez-ramirez-673No ratings yet
- SSL Tls and Their AttacksDocument66 pagesSSL Tls and Their AttacksJoseph DialloNo ratings yet
- Basdjo PDFDocument206 pagesBasdjo PDFNikushaNo ratings yet
- A Known Plaintext Attack On The PKZIP Stream CipherDocument10 pagesA Known Plaintext Attack On The PKZIP Stream Cipherrobson2015No ratings yet
- PPL Lab Assignment CodeDocument30 pagesPPL Lab Assignment CodesunNo ratings yet
- Working With Functions Sumita Arora MCQDocument7 pagesWorking With Functions Sumita Arora MCQpokim55438100% (1)
- Case StudyDocument5 pagesCase StudyMohd AfiqNo ratings yet
- Increase The Immunity Satellite TV Channels by Usingmulti-Bouquetshopping TechniquesDocument9 pagesIncrease The Immunity Satellite TV Channels by Usingmulti-Bouquetshopping TechniquesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Sis 2.0 Emcp4.2Document14 pagesSis 2.0 Emcp4.2ALEJANDRO ALVAREZ BALVERONo ratings yet
- 5000H Parts Book: Version 5 For Serial Numbers 2H-282-1455 To 2H-400Document609 pages5000H Parts Book: Version 5 For Serial Numbers 2H-282-1455 To 2H-400Beto José Roberto De Castro SantosNo ratings yet
- SKT200-250TT Series SpecificationDocument8 pagesSKT200-250TT Series SpecificationcoronaqcNo ratings yet
- Chapter 17 - Transient Stability AnalysisDocument45 pagesChapter 17 - Transient Stability AnalysisPradeep_VashistNo ratings yet
- CIS RAM For IG1 Workbook v21.10.25Document144 pagesCIS RAM For IG1 Workbook v21.10.25pikanteNo ratings yet
- AutoCAD 6Document4 pagesAutoCAD 6Radient MushfikNo ratings yet
- OSSSC RI Syllabus 2021 and Exam Pattern 2021Document4 pagesOSSSC RI Syllabus 2021 and Exam Pattern 2021aankit2037No ratings yet