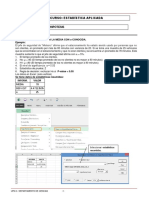
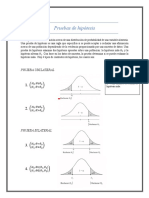
You might also like
- TYCPPS - Sesión 16-17. Sensibilidad y Especificidad. Regresión LogísticaDocument29 pagesTYCPPS - Sesión 16-17. Sensibilidad y Especificidad. Regresión Logísticaantonio muñozNo ratings yet
- Refuerzo Examen ParcialDocument8 pagesRefuerzo Examen Parcialcarlos vilcaNo ratings yet
- Sesión 21 Regresión Bivariada Los Supuestos 27.10.20 XDocument37 pagesSesión 21 Regresión Bivariada Los Supuestos 27.10.20 XCristóbal Karle SaavedraNo ratings yet
- Pasos para El Analisis Estadistico en Investigaciones CorrelativasDocument5 pagesPasos para El Analisis Estadistico en Investigaciones CorrelativasEmmanuel LópezNo ratings yet
- Semana 13 - Análisis de Regresión y Correlación Lineal Simple (PDF - Io)Document45 pagesSemana 13 - Análisis de Regresión y Correlación Lineal Simple (PDF - Io)SEBAS romsNo ratings yet
- Pasos para El Analisis Estadistico en Investigacion CorrelacionalDocument5 pagesPasos para El Analisis Estadistico en Investigacion CorrelacionalEmmanuel LópezNo ratings yet
- Estimación. ICDocument21 pagesEstimación. ICJosepht MuñozNo ratings yet
- Semana 2 - PDF - Intervalos de Confianza para La ProporciónDocument3 pagesSemana 2 - PDF - Intervalos de Confianza para La ProporciónCarlos Jheremy SerpaNo ratings yet
- Tarea 04 - BayronSanchezDocument8 pagesTarea 04 - BayronSanchezBayron AndresNo ratings yet
- Yrv FctyDocument63 pagesYrv FctyLuis FernandoNo ratings yet
- Analisis de Regresion LinealDocument13 pagesAnalisis de Regresion Linealanon_516027180No ratings yet
- Inferencia A Partir de Datos Apareados: Prueba (T) - ParamétricaDocument6 pagesInferencia A Partir de Datos Apareados: Prueba (T) - ParamétricayunniorNo ratings yet
- Regresión Lineal SimpleDocument47 pagesRegresión Lineal SimpleNixonloloNo ratings yet
- Capitulo 8 - MODELOS BINARIOS DE SCORINGDocument18 pagesCapitulo 8 - MODELOS BINARIOS DE SCORINGLeonardo Torres LudeñaNo ratings yet
- Regresión y CorrelaciónDocument39 pagesRegresión y CorrelaciónEl ZucaritasNo ratings yet
- U08-Intervalos de ConfianzaDocument65 pagesU08-Intervalos de ConfianzafrancojahNo ratings yet
- Pasos para El Analisis Estadistico en Investigacion DescriptivaDocument5 pagesPasos para El Analisis Estadistico en Investigacion DescriptivaEmmanuel LópezNo ratings yet
- Trabajo Encargado N°02Document10 pagesTrabajo Encargado N°02Ros Anna qgNo ratings yet
- Pasosdela RegresionlinealsimpleDocument6 pagesPasosdela RegresionlinealsimpleMedaliz MendezNo ratings yet
- Intervalos de ConfianzaDocument52 pagesIntervalos de ConfianzaLeón Calle Dieter SebastiánNo ratings yet
- Calificación Wais Iv 2023 RevDocument31 pagesCalificación Wais Iv 2023 Revotro gatoNo ratings yet
- Clase Inferencia Estadistica UniversidadDocument25 pagesClase Inferencia Estadistica UniversidadCarlos Vargas RodríguezNo ratings yet
- 10-09-2019 230959 PM ANEXOCORRELACIONDocument4 pages10-09-2019 230959 PM ANEXOCORRELACIONLuis Antonio Rojas CastrejonNo ratings yet
- Compilacion Ejercicios y Preguntas Diseños - Todo en Uno. Ejercicios Resueltos de Maria FontDocument126 pagesCompilacion Ejercicios y Preguntas Diseños - Todo en Uno. Ejercicios Resueltos de Maria FontCokeNo ratings yet
- Regresion Lineal SimpleDocument25 pagesRegresion Lineal SimpleLucila Meza CarrealNo ratings yet
- Ma470 202102 Cuaderno de Trabajo Unidad VDocument17 pagesMa470 202102 Cuaderno de Trabajo Unidad VJessica CardenasNo ratings yet
- Encuentro 3 - Técnicas de TestingDocument35 pagesEncuentro 3 - Técnicas de TestingGaBy TrymeNo ratings yet
- Guia. Análisis Con SPSS y R.Document6 pagesGuia. Análisis Con SPSS y R.Pierre KebudiNo ratings yet
- Prueba T StudentsDocument6 pagesPrueba T StudentsjhonatanNo ratings yet
- Intervalos de Confianza para MediasDocument24 pagesIntervalos de Confianza para MediasJenifer GarcesNo ratings yet
- Clase6 Stata ANOVADocument13 pagesClase6 Stata ANOVAMaria BotasNo ratings yet
- Tarea 6 - Inferencia Estadística. Intervalos de Confianza - Anhelina Spizhavka ShcherbakDocument12 pagesTarea 6 - Inferencia Estadística. Intervalos de Confianza - Anhelina Spizhavka ShcherbakMantente Fuerte (xBieberbelieve)No ratings yet
- Estimacion Estadistica MM241 IIIPAC2020Document19 pagesEstimacion Estadistica MM241 IIIPAC2020sus galireNo ratings yet
- Problemas Resueltos de Intervalo de Confianza para Una Media y Una ProporciónDocument10 pagesProblemas Resueltos de Intervalo de Confianza para Una Media y Una ProporciónJEAN PAUL JOSE ORMEÑO PUMANo ratings yet
- Sesion 3Document16 pagesSesion 3Wilkins AlbujarNo ratings yet
- PDF 11 Perbandingan Perhitungani Reaktor Isotermal Dan Non Isotermal Contoh Soal CompressDocument17 pagesPDF 11 Perbandingan Perhitungani Reaktor Isotermal Dan Non Isotermal Contoh Soal CompressMus D TaqimNo ratings yet
- Trabajo de EstadisticaDocument5 pagesTrabajo de EstadisticaPablo Mayuri QuispeNo ratings yet
- 2-Segunda Clase Estadistica IiDocument42 pages2-Segunda Clase Estadistica IiJhoany Medina50% (2)
- Practica de Laboratorio 1 ProgramacionDocument16 pagesPractica de Laboratorio 1 ProgramacionCARLOS SALVADOR DAHBURA OSORIONo ratings yet
- Cuantizacion Y CodificacionDocument6 pagesCuantizacion Y CodificacionVictor IsraelNo ratings yet
- Sesion 3-4 - 24Document110 pagesSesion 3-4 - 24LidaraABNo ratings yet
- MA470 - Regresion Lineal Final - 2022 - 02Document7 pagesMA470 - Regresion Lineal Final - 2022 - 02Diego BerlangaNo ratings yet
- T7.1 Análisis de Correlación y Regresión Lineal SimpleDocument23 pagesT7.1 Análisis de Correlación y Regresión Lineal SimpleAndiko Villacis NavasNo ratings yet
- Asesoria de Tesis y Trabajos de GradoDocument10 pagesAsesoria de Tesis y Trabajos de Gradojuly lopezNo ratings yet
- Sesión 11 Pruebas Intervalos de Confianza 15.9.20 PDFDocument35 pagesSesión 11 Pruebas Intervalos de Confianza 15.9.20 PDFCristóbal Karle SaavedraNo ratings yet
- Presentación - Intervalos de Confianza para La Media y La ProporciónDocument35 pagesPresentación - Intervalos de Confianza para La Media y La ProporciónLaghis 9No ratings yet
- Resumen Revisión WISC-IV Ejemplo Corto Reporte ResultadosDocument6 pagesResumen Revisión WISC-IV Ejemplo Corto Reporte ResultadosMontse Aguirre100% (1)
- Clase 7-1 - REGRESIÓN LINEAL SIMPLEDocument9 pagesClase 7-1 - REGRESIÓN LINEAL SIMPLEMilthy PCNo ratings yet
- Guía Prueba de HipótesisDocument10 pagesGuía Prueba de HipótesisAlexzy Ramirez BustamanteNo ratings yet
- ProgramacionDocument11 pagesProgramacionFabricio IzaNo ratings yet
- Estimación Puntual: Inferencia EstadísticaDocument20 pagesEstimación Puntual: Inferencia EstadísticadafegoNo ratings yet
- Regresion Lineal SimpleDocument34 pagesRegresion Lineal SimplejimmyNo ratings yet
- Estimacion EstadisticaDocument18 pagesEstimacion EstadisticaAriel Jimenez100% (1)
- 4.-EJEMPLO Prueba de HipótesisDocument22 pages4.-EJEMPLO Prueba de HipótesisRafael Sánchez DuránNo ratings yet
- Fisica Computaciona I-Semana 1Document26 pagesFisica Computaciona I-Semana 1YhonNo ratings yet
- Stat 1203 Ejercicio 12 PDFDocument25 pagesStat 1203 Ejercicio 12 PDFAlexander Utrilla CuriNo ratings yet
- Adi Tema 9Document26 pagesAdi Tema 9Rayane Cherqi AmarNo ratings yet
- Análisis Del ErrorDocument28 pagesAnálisis Del ErrorTephano El TucoNo ratings yet
- 100 Anosde GavionesDocument2 pages100 Anosde GavionesJhans YauriNo ratings yet
- Minerales de CobreDocument4 pagesMinerales de CobreJhans YauriNo ratings yet
- FEPIDocument30 pagesFEPIJhans YauriNo ratings yet
- 100AnosdeGaviones PDFDocument6 pages100AnosdeGaviones PDFHever CondoriNo ratings yet
- HojafabricacionDocument1 pageHojafabricacionJhans YauriNo ratings yet
- TORNOS TIEMPOS DE MAQUINADO Okok PDFDocument6 pagesTORNOS TIEMPOS DE MAQUINADO Okok PDFs_barriosNo ratings yet
- Practica 1 - TecnologiaDocument7 pagesPractica 1 - TecnologiaJhans YauriNo ratings yet
- Equipamiento de LaboratorioDocument3 pagesEquipamiento de LaboratorioJhans YauriNo ratings yet
- Flujo de CajaDocument16 pagesFlujo de CajaJhans YauriNo ratings yet
- 2018 00 Fii Semana 06 Parte 1Document38 pages2018 00 Fii Semana 06 Parte 1Jhans YauriNo ratings yet
- Introduccion A Los Modelos EstocasticosDocument25 pagesIntroduccion A Los Modelos EstocasticosJhans YauriNo ratings yet
- Gestion de Procesos SpanishDocument59 pagesGestion de Procesos SpanishJhans YauriNo ratings yet
- Practica Calificada 2Document17 pagesPractica Calificada 2Jhans YauriNo ratings yet
- Trabajo FinalDocument6 pagesTrabajo FinalJhans YauriNo ratings yet
- Regresion Lineal Unidad 1Document7 pagesRegresion Lineal Unidad 1Montse Hdez HdezNo ratings yet
- Deeminacion de La Poblacion y MuetaDocument11 pagesDeeminacion de La Poblacion y MuetaErika Cruz SanchezNo ratings yet
- Taller 3, Estadistica de La ProbabilidadDocument4 pagesTaller 3, Estadistica de La ProbabilidadSandra Liliana Borrero SilvaNo ratings yet
- Informe de Fisica #1Document24 pagesInforme de Fisica #1Bladimir Guevara MinayaNo ratings yet
- ASIGNACION No. 2 - GLOSARIO DIDACTICO INDIVIDUAL 10% PDFDocument3 pagesASIGNACION No. 2 - GLOSARIO DIDACTICO INDIVIDUAL 10% PDFRene RodriguezNo ratings yet
- Alonso e Finn Vol. 3 - Cuántica Fundamental y La Física EstadísticaDocument636 pagesAlonso e Finn Vol. 3 - Cuántica Fundamental y La Física EstadísticaSirKrifyus0% (1)
- Charles Sanders Peirce La Ciencia de La Semiótica 1 PDFDocument40 pagesCharles Sanders Peirce La Ciencia de La Semiótica 1 PDFNeviz ReinaNo ratings yet
- Historia de Las Ciencias SocialesDocument5 pagesHistoria de Las Ciencias SocialesSUSEL MAMANI PINTONo ratings yet
- Ejemplos de Regresión Lineal S y MDocument9 pagesEjemplos de Regresión Lineal S y MQuímica la Ciencia CentralNo ratings yet
- El Concepto de Investigación SocialDocument2 pagesEl Concepto de Investigación SocialEdwin Ajucum100% (1)
- T de StudentDocument5 pagesT de StudentVinicioNo ratings yet
- Marco TeóricoDocument6 pagesMarco TeóricoGisela Gaspar SNo ratings yet
- Generalidades y Conceptos Basicos IDocument6 pagesGeneralidades y Conceptos Basicos IzamirafaNo ratings yet
- Unidad 1. La Economía Una Ciencia SocialDocument20 pagesUnidad 1. La Economía Una Ciencia SocialBerta BayoNo ratings yet
- Metologia de InvestigacionDocument9 pagesMetologia de InvestigacionAriel CorderoNo ratings yet
- Guía Resumida para Exámen de Investigación SampieriDocument9 pagesGuía Resumida para Exámen de Investigación SampieriAna JuárezNo ratings yet
- 7S Indicadores TESIS 1Document28 pages7S Indicadores TESIS 1Xepitho Camposano MezaNo ratings yet
- Regresion y Correlacion Lineal Simple Ejercicios ResueltosDocument16 pagesRegresion y Correlacion Lineal Simple Ejercicios ResueltosJosé Vivanco NúñezNo ratings yet
- EvaluacionDocument3 pagesEvaluacionLorena RomeroNo ratings yet
- M08 S2 Metodología de Investigación Social PDFDocument7 pagesM08 S2 Metodología de Investigación Social PDFLaura OlCaNo ratings yet
- MÉTODO, Metodologia, TecnicaDocument6 pagesMÉTODO, Metodologia, TecnicaAgu HerreraNo ratings yet
- Chasqui Martin Serrano 2011Document216 pagesChasqui Martin Serrano 2011Martín del CastilloNo ratings yet
- Montero (2006) - Cap 1Document22 pagesMontero (2006) - Cap 1Luciano SanguinettiNo ratings yet
- Copia de PLANTILLA EXACTA-3Document16 pagesCopia de PLANTILLA EXACTA-3jeissy0% (1)
- Graficas HemDocument2 pagesGraficas HemKevin Santiago RodríguezNo ratings yet
- Finanzas - Estadistica para FinanzasDocument20 pagesFinanzas - Estadistica para FinanzasFranco CampanuucciNo ratings yet
- Unidad Ii DivisionDocument1 pageUnidad Ii DivisionJORGE LUIS SOTO ALARCoNNo ratings yet
- Clasificación de Las CienciasDocument18 pagesClasificación de Las CienciasAbielMárquezBandalaNo ratings yet
- Evaluacion Final - ESTADISTICA INFERENCIAL - (GRUPO B03)Document7 pagesEvaluacion Final - ESTADISTICA INFERENCIAL - (GRUPO B03)Juancho David CarvajalNo ratings yet