You might also like
- Artificial Neural Network: 1 BackgroundDocument13 pagesArtificial Neural Network: 1 Backgroundyua_ntNo ratings yet
- Deep LearningDocument45 pagesDeep Learningnigel989No ratings yet
- Deep Learning I. Introduction (: 1. The History and The Development of Deep LearningDocument21 pagesDeep Learning I. Introduction (: 1. The History and The Development of Deep Learningsandy milk minNo ratings yet
- The Fundamental Concepts Behind Deep LearningDocument22 pagesThe Fundamental Concepts Behind Deep LearningAbu RayhanNo ratings yet
- Deep LearningDocument24 pagesDeep Learningadrian sanchezNo ratings yet
- Artificial Neural NetworkDocument14 pagesArtificial Neural NetworkAzureNo ratings yet
- Convolutional Neural Networks in Python: Beginner's Guide to Convolutional Neural Networks in PythonFrom EverandConvolutional Neural Networks in Python: Beginner's Guide to Convolutional Neural Networks in PythonNo ratings yet
- Neural NetworksDocument36 pagesNeural NetworksSivaNo ratings yet
- Neural Networks: Course OverviewDocument12 pagesNeural Networks: Course OverviewProgramming LifeNo ratings yet
- Using Neuroscience To Develop AIDocument2 pagesUsing Neuroscience To Develop AIkammy19941No ratings yet
- Long Short Term Memory: Fundamentals and Applications for Sequence PredictionFrom EverandLong Short Term Memory: Fundamentals and Applications for Sequence PredictionNo ratings yet
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonFrom EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonNo ratings yet
- Soft Computing: Project ReportDocument54 pagesSoft Computing: Project ReportShūbhåm ÑagayaÇhNo ratings yet
- Neural NetworksDocument104 pagesNeural NetworksSingam Giridhar Kumar ReddyNo ratings yet
- UNIT4Document13 pagesUNIT4Ayush NighotNo ratings yet
- Neuroevolution: Fundamentals and Applications for Surpassing Human Intelligence with NeuroevolutionFrom EverandNeuroevolution: Fundamentals and Applications for Surpassing Human Intelligence with NeuroevolutionNo ratings yet
- 9 Cryptical Learning IsDocument5 pages9 Cryptical Learning IsRichard BryanNo ratings yet
- Demystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFDocument27 pagesDemystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFharislyeNo ratings yet
- Artificial Neural NetworksDocument43 pagesArtificial Neural NetworksanqrwpoborewNo ratings yet
- Unit 1 Complete NotesDocument44 pagesUnit 1 Complete Notes20bd1a058tNo ratings yet
- Artificial Neural Networks: Fundamentals and Applications for Decoding the Mysteries of Neural ComputationFrom EverandArtificial Neural Networks: Fundamentals and Applications for Decoding the Mysteries of Neural ComputationNo ratings yet
- ANN - WikiDocument39 pagesANN - Wikirudy_tanagaNo ratings yet
- Neural Networks and Deep Learning: RationaleDocument2 pagesNeural Networks and Deep Learning: RationaleJorge GuerreroNo ratings yet
- PHD Thesis On Artificial Neural NetworksDocument8 pagesPHD Thesis On Artificial Neural Networksprdezlief100% (1)
- Machine Learning Data Mining: ProblemsDocument27 pagesMachine Learning Data Mining: ProblemsnanaoNo ratings yet
- On Neural Networks and Application: Submitted By: Makrand Ballal Reg No. 1025929 Mca 3 SemDocument14 pagesOn Neural Networks and Application: Submitted By: Makrand Ballal Reg No. 1025929 Mca 3 Semmakku_ballalNo ratings yet
- Artificial Neural Network: ISSN:2320-0790Document3 pagesArtificial Neural Network: ISSN:2320-0790Ijact EditorNo ratings yet
- Deep Learning With Spiking NeuronsDocument18 pagesDeep Learning With Spiking NeuronsMohaddeseh MozaffariNo ratings yet
- Hand Written Character Recognition Using Back Propagation NetworkDocument13 pagesHand Written Character Recognition Using Back Propagation NetworkMegan TaylorNo ratings yet
- Artificial Neural Network DissertationDocument8 pagesArtificial Neural Network DissertationPayToDoMyPaperDurham100% (1)
- Deep LearnongDocument14 pagesDeep LearnongJuniper2015No ratings yet
- Convolutional Neural Network For Image RecognitionDocument8 pagesConvolutional Neural Network For Image RecognitionIJRASETPublicationsNo ratings yet
- A Survey of Deep Neural Network Architectures and Their ApplicationsDocument31 pagesA Survey of Deep Neural Network Architectures and Their ApplicationsAmgad Fayez AzizNo ratings yet
- Neural NetworksDocument11 pagesNeural Networks16Julie KNo ratings yet
- Tutorial Instruction Answer The Following QuestionsDocument3 pagesTutorial Instruction Answer The Following QuestionsKatoon GhodeNo ratings yet
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- Paper 8594Document5 pagesPaper 8594IJARSCT JournalNo ratings yet
- Deep Neural NetworksDocument22 pagesDeep Neural NetworksDon Nipuna PandithasundaraNo ratings yet
- COVID-19 ChatBotDocument8 pagesCOVID-19 ChatBotIJRASETPublicationsNo ratings yet
- DataScience (SABARNA ROY - 05) (CA2)Document18 pagesDataScience (SABARNA ROY - 05) (CA2)132 Arindam DattaNo ratings yet
- Artificial Neural Networks: Seminar Report OnDocument24 pagesArtificial Neural Networks: Seminar Report OnsudhirpratapsinghratNo ratings yet
- Neural Network: From Wikipedia, The Free EncyclopediaDocument9 pagesNeural Network: From Wikipedia, The Free EncyclopediaLeonardo Kusuma PNo ratings yet
- Foundation Design Using ANNDocument57 pagesFoundation Design Using ANNAniRuddhaNo ratings yet
- Final 1st LectureDocument18 pagesFinal 1st LectureshilpaNo ratings yet
- Ai Ga1Document7 pagesAi Ga1Darshnik DeepNo ratings yet
- Nonlinear, and Parallel Computer (Information-Processing System) - It Has The Capability ToDocument6 pagesNonlinear, and Parallel Computer (Information-Processing System) - It Has The Capability Toİsmail KıyıcıNo ratings yet
- Deep Neural NetworkDocument12 pagesDeep Neural NetworkK.P.Revathi Asst prof - IT DeptNo ratings yet
- Machine Learning: Version 2 CSE IIT, KharagpurDocument5 pagesMachine Learning: Version 2 CSE IIT, KharagpurVanu ShaNo ratings yet
- Artificial Neural NetworkDocument21 pagesArtificial Neural Networkannibuit007No ratings yet
- Deep LearningDocument5 pagesDeep LearningNKOEBE KHOELINo ratings yet
- Ontology Concept Extraction Algorithm For Deep Neural NetworksDocument6 pagesOntology Concept Extraction Algorithm For Deep Neural NetworksThiago Raulino Dal PontNo ratings yet
- My DLunit 2 FRM TXTDocument18 pagesMy DLunit 2 FRM TXTVali BhashaNo ratings yet
- Data-Mining and Knowledge Discovery, Neural Networks inDocument15 pagesData-Mining and Knowledge Discovery, Neural Networks inElena Galeote LopezNo ratings yet
- Artificial Neural Network 7151 J5ZwbesDocument27 pagesArtificial Neural Network 7151 J5ZwbesJajula YashwanthdattaNo ratings yet
- Literature Review Neural NetworkDocument5 pagesLiterature Review Neural Networkfvffybz9100% (1)
- Deep LearningDocument243 pagesDeep LearningMani VasamsettyNo ratings yet
- This MIT LectureDocument1 pageThis MIT LecturemahfuzaNo ratings yet
- TensorFlow in 1 Day: Make your own Neural NetworkFrom EverandTensorFlow in 1 Day: Make your own Neural NetworkRating: 4 out of 5 stars4/5 (8)
- Schirrmeister Et Al-2017-Human Brain MappingDocument30 pagesSchirrmeister Et Al-2017-Human Brain MappingMrigankshi KapoorNo ratings yet
- Effects of Team Building and Goal Setting On Productivity: A Field ExperimentDocument26 pagesEffects of Team Building and Goal Setting On Productivity: A Field ExperimentJay DixitNo ratings yet
- Dharma in Vedas and Dharmasastras PDFDocument26 pagesDharma in Vedas and Dharmasastras PDFsagar_lal100% (1)
- Introduction To Research: Research Methodology Dr. Nimit ChowdharyDocument29 pagesIntroduction To Research: Research Methodology Dr. Nimit ChowdharyDr. Nimit ChowdharyNo ratings yet
- !!!the Bipolar Workbook For Teens - DBT Skills To Help You Control Mood Swings - Sheri Van DijkDocument162 pages!!!the Bipolar Workbook For Teens - DBT Skills To Help You Control Mood Swings - Sheri Van DijkAnonymous aK4BTcdcVm100% (2)
- Lecture-103 (Dangling and Misplaced Modifiers)Document20 pagesLecture-103 (Dangling and Misplaced Modifiers)Md Samiul Islam 2211909030No ratings yet
- Swain vs. Krashen Second Language AcquisitionDocument8 pagesSwain vs. Krashen Second Language AcquisitionBlossomsky9650% (2)
- Why Study PhilosophyDocument3 pagesWhy Study PhilosophyAnonymous ORqO5yNo ratings yet
- Ethanography PPT SusilaDocument77 pagesEthanography PPT SusilasusilachandranNo ratings yet
- Articol 2Document14 pagesArticol 2ionasanu cristinaNo ratings yet
- Kindly Reply With Following Details:: TH THDocument2 pagesKindly Reply With Following Details:: TH THIlyas SafiNo ratings yet
- DLL Quarter 2 Week 8 AP 3Document5 pagesDLL Quarter 2 Week 8 AP 3Arvin TocinoNo ratings yet
- Autoencoders - Bits and Bytes of Deep Learning - Towards Data ScienceDocument10 pagesAutoencoders - Bits and Bytes of Deep Learning - Towards Data ScienceMohit SinghNo ratings yet
- The Use of Arabic and Moghrebi in Paul Bowles' The Spider's HouseDocument9 pagesThe Use of Arabic and Moghrebi in Paul Bowles' The Spider's Houseایماندار ٹڈڈاNo ratings yet
- Acme and Omega Electronics: 1. Why Did Omega Discover The Design Problem, But Not Acme?Document2 pagesAcme and Omega Electronics: 1. Why Did Omega Discover The Design Problem, But Not Acme?rohitNo ratings yet
- Multimodal Discourse AnalysisDocument7 pagesMultimodal Discourse AnalysisHanifah zain0% (1)
- Case Studies in Organizational Communication Prepared by Steve May, University of North Carolina, Chapel Hill 2003Document11 pagesCase Studies in Organizational Communication Prepared by Steve May, University of North Carolina, Chapel Hill 2003rahulgaurav123No ratings yet
- Experiment 2: AIM: Implementation of Classification Technique On ARFF Files Using WEKA Data SetDocument3 pagesExperiment 2: AIM: Implementation of Classification Technique On ARFF Files Using WEKA Data SetShivam DharNo ratings yet
- Esaay EnglishDocument3 pagesEsaay EnglishNita DwihapsariNo ratings yet
- Chemistry Internal AssessmentDocument12 pagesChemistry Internal AssessmentRavindra Narayan Aher100% (1)
- Debating Tips and StrategiesDocument13 pagesDebating Tips and StrategiesDacien NguyeenNo ratings yet
- ملخص دروس اللغة الإنجليزيةDocument11 pagesملخص دروس اللغة الإنجليزيةBac Yes We CanNo ratings yet
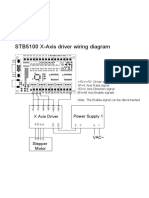
- STB5100 Electric Wiring Diagram 1 - 5Document5 pagesSTB5100 Electric Wiring Diagram 1 - 5PauloTexaNo ratings yet
- Prosodic Feature PPT Demo TeachingDocument16 pagesProsodic Feature PPT Demo TeachingEJ Deanne Logarta100% (3)
- Biggs Constructive AlignmentDocument12 pagesBiggs Constructive AlignmentWellington MendesNo ratings yet
- Material 5Document3 pagesMaterial 5LauraNo ratings yet
- HW5e UpperInterm TG Unit4 PDFDocument13 pagesHW5e UpperInterm TG Unit4 PDFBegüm KömeçNo ratings yet
- The Chatbot Revolution and The Indian HR Professionals: March 2019Document12 pagesThe Chatbot Revolution and The Indian HR Professionals: March 2019Mohamad KharboutlyNo ratings yet
- 12 Chapter 4Document133 pages12 Chapter 4Phongshak PhomNo ratings yet
- Chapter 8Document49 pagesChapter 8RosmarinusNo ratings yet
- Recognized by The Government I Founded 1928 I Candelaria, QuezonDocument2 pagesRecognized by The Government I Founded 1928 I Candelaria, QuezonOccasus DeirdreNo ratings yet