You might also like
- Aca NotesDocument148 pagesAca NotesHanisha BavanaNo ratings yet
- Large Computer Systems and Pipelining: HomeworkDocument11 pagesLarge Computer Systems and Pipelining: HomeworkRyan ReyesNo ratings yet
- Serial and Parallel First 3 LectureDocument17 pagesSerial and Parallel First 3 LectureAsif KhanNo ratings yet
- Assignment: Parallel and Distributed Computing Submitted To: Sir Shoaib Date: 25-03-2019Document5 pagesAssignment: Parallel and Distributed Computing Submitted To: Sir Shoaib Date: 25-03-2019UmerNo ratings yet
- A Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)Document8 pagesA Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Cluster ComputingDocument5 pagesCluster Computingshaheen sayyad 463No ratings yet
- Introduction To Parallel Computing: John Von Neumann Institute For ComputingDocument18 pagesIntroduction To Parallel Computing: John Von Neumann Institute For Computingsandeep_nagar29No ratings yet
- HPC NotesDocument24 pagesHPC NotesShadowOPNo ratings yet
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- Types of Parallel ComputingDocument11 pagesTypes of Parallel Computingprakashvivek990No ratings yet
- Parallel Processing: Types of ParallelismDocument7 pagesParallel Processing: Types of ParallelismRupesh MishraNo ratings yet
- Chapter 1Document25 pagesChapter 1chinmayNo ratings yet
- Name:: Abdulhannan KhawajaDocument6 pagesName:: Abdulhannan KhawajaSAMAR BUTTNo ratings yet
- Introduction To Parallel ComputingDocument34 pagesIntroduction To Parallel ComputingJOna Lyne0% (1)
- Unit - IDocument20 pagesUnit - Isas100% (1)
- Rubio Campillo2018Document3 pagesRubio Campillo2018AimanNo ratings yet
- Lecture Week - 1 Introduction 1 - SP-24Document51 pagesLecture Week - 1 Introduction 1 - SP-24imhafeezniaziNo ratings yet
- PDC 1Document41 pagesPDC 1Engr Mir MuhammadNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- High Performance ComputingDocument164 pagesHigh Performance Computingtpabbas100% (2)
- Week 5 - The Impact of Multi-Core Computing On Computational OptimizationDocument11 pagesWeek 5 - The Impact of Multi-Core Computing On Computational OptimizationGame AccountNo ratings yet
- PG Cloud Computing Unit IIDocument52 pagesPG Cloud Computing Unit IIdeepthi sanjeevNo ratings yet
- Lecture1 NotesDocument19 pagesLecture1 Notesl215376No ratings yet
- 3.3-Recent Trends in Parallel ComputingDocument12 pages3.3-Recent Trends in Parallel ComputingChetan SolankiNo ratings yet
- Embedded System ArchitectureDocument10 pagesEmbedded System ArchitectureShruti KadyanNo ratings yet
- Parallel Algorithm and ProgrammingDocument4 pagesParallel Algorithm and ProgrammingMahmud MankoNo ratings yet
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- CA Classes-251-255Document5 pagesCA Classes-251-255SrinivasaRaoNo ratings yet
- CA Document 1Document8 pagesCA Document 1ToobaNo ratings yet
- CS0051 - Module 01Document52 pagesCS0051 - Module 01Ron BayaniNo ratings yet
- Parallel ProcessingDocument4 pagesParallel Processingnikhilesh walde100% (1)
- Cluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKDocument34 pagesCluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKNishshanka CJNo ratings yet
- Watercolor Organic Shapes SlidesManiaDocument23 pagesWatercolor Organic Shapes SlidesManiaAyush kumarNo ratings yet
- CSE 423 Virtualization and Cloud Computinglecture0Document16 pagesCSE 423 Virtualization and Cloud Computinglecture0Shahad ShahulNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- Technical Seminar Report On: "High Performance Computing"Document14 pagesTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2No ratings yet
- Introduction To: Parallel DistributedDocument32 pagesIntroduction To: Parallel Distributedaliha ghaffarNo ratings yet
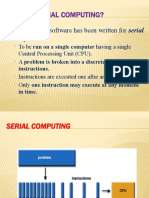
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Parallel Terminology 2Document7 pagesParallel Terminology 2maxsen021No ratings yet
- Multicore ComputersDocument18 pagesMulticore ComputersMikias YimerNo ratings yet
- CSE 423 Lecture 2Document12 pagesCSE 423 Lecture 2Ranjith SKNo ratings yet
- PD Computing Introduction. Why Use PDCDocument31 pagesPD Computing Introduction. Why Use PDCmohsanhussain230No ratings yet
- Parallel Processing Assignment 1Document14 pagesParallel Processing Assignment 1RobelNo ratings yet
- Parallel Processing Assignment 1Document14 pagesParallel Processing Assignment 1RobelNo ratings yet
- Artificial IntelligenceDocument12 pagesArtificial IntelligenceHimanshu MishraNo ratings yet
- (HPC) PratikDocument8 pages(HPC) Pratik60Abhishek KalpavrukshaNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- DistributedcompDocument13 pagesDistributedcompdiplomaincomputerengineeringgrNo ratings yet
- Chapter - 2 - Library - Cloud - Parallel ComputingDocument7 pagesChapter - 2 - Library - Cloud - Parallel ComputingMonika VNo ratings yet
- Parallel Computing Seminar ReportDocument35 pagesParallel Computing Seminar ReportAmeya Waghmare100% (3)
- HPCfirstlectureDocument4 pagesHPCfirstlectureJiju P NairNo ratings yet
- Parallel Computing: Charles KoelbelDocument12 pagesParallel Computing: Charles KoelbelSilvio DresserNo ratings yet
- What Is Parallel ComputingDocument4 pagesWhat Is Parallel ComputingbihanNo ratings yet
- Microcomputer: MainframeDocument5 pagesMicrocomputer: MainframejoelchaleNo ratings yet
- Multicore Software Development Techniques: Applications, Tips, and TricksFrom EverandMulticore Software Development Techniques: Applications, Tips, and TricksRating: 2.5 out of 5 stars2.5/5 (2)
- Fundamentals of Modern Computer Architecture: From Logic Gates to Parallel ProcessingFrom EverandFundamentals of Modern Computer Architecture: From Logic Gates to Parallel ProcessingNo ratings yet
- Introduction To CUDA C 3Document67 pagesIntroduction To CUDA C 3Tarun RamNo ratings yet
- Types of Finite Element MethodDocument2 pagesTypes of Finite Element MethodpatasutoshNo ratings yet
- What Are The Boundary Condition For Electrostatic Potential at An Interface Between Two Different Electric Media?Document6 pagesWhat Are The Boundary Condition For Electrostatic Potential at An Interface Between Two Different Electric Media?patasutoshNo ratings yet
- 1 of 1Document41 pages1 of 1patasutoshNo ratings yet
- ESL01R.C Research MethodologiesDocument9 pagesESL01R.C Research MethodologiespatasutoshNo ratings yet
- Introduction To Parallel Processing: Chapter 1 From Culler & Singh Winter 2007Document44 pagesIntroduction To Parallel Processing: Chapter 1 From Culler & Singh Winter 2007patasutoshNo ratings yet
- A Comparative Study of Five Programming Languages Parallel: Henri E. BalDocument15 pagesA Comparative Study of Five Programming Languages Parallel: Henri E. BalpatasutoshNo ratings yet
- DSM AdvantagesDocument5 pagesDSM AdvantagesMuthuselviNo ratings yet
- Agarwal Et Al. - The MIT Alewife MachineDocument12 pagesAgarwal Et Al. - The MIT Alewife MachineFuzzy KNo ratings yet
- Sun Solaris OS: Glenn Barney Gb2174@columbia - EduDocument35 pagesSun Solaris OS: Glenn Barney Gb2174@columbia - EduhanhndNo ratings yet
- Senior DBA Interview QuestionsDocument8 pagesSenior DBA Interview QuestionsKadambari RanjanNo ratings yet
- Unit 3 (3.3) Inter Process Communication (IPC)Document18 pagesUnit 3 (3.3) Inter Process Communication (IPC)Tushar HedauNo ratings yet
- Computer Science EngineeringDocument33 pagesComputer Science Engineeringgopi_meruguNo ratings yet
- WR VX Simulator Users Guide 6.1Document114 pagesWR VX Simulator Users Guide 6.1Tito JohnsonNo ratings yet
- ANSYS Mechanical APDL Parallel Processing GuideDocument56 pagesANSYS Mechanical APDL Parallel Processing GuideKevin XuNo ratings yet
- Inter-Process Communication in Linux PDFDocument25 pagesInter-Process Communication in Linux PDFVNo ratings yet
- Barbara Chapman Using OpenMPDocument378 pagesBarbara Chapman Using OpenMPKarpov PeterNo ratings yet
- O'Reilly, Posix 4, Programming For The Real WorldDocument552 pagesO'Reilly, Posix 4, Programming For The Real WorldviethoangNo ratings yet
- Zeal Polytechnic, Pune.: Third Year (Ty) Diploma in Computer Engineering Scheme: I Semester: VDocument34 pagesZeal Polytechnic, Pune.: Third Year (Ty) Diploma in Computer Engineering Scheme: I Semester: V974-Abhijeet MotewarNo ratings yet
- Database Client Installation Guide LinuxDocument75 pagesDatabase Client Installation Guide LinuxHarish NaikNo ratings yet
- 8 SynchronizationDocument112 pages8 SynchronizationNEROB KUMAR MOHONTO XRLNZGkUXm100% (1)
- 1 A.Sathiyaraj/Assoc - Prof/CSE Dept/RISE GroupsDocument16 pages1 A.Sathiyaraj/Assoc - Prof/CSE Dept/RISE GroupsSai Pavitra VangalaNo ratings yet
- The Process: Processes ConceptDocument13 pagesThe Process: Processes ConceptPGNo ratings yet
- 2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFDocument63 pages2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFANTHONY NIKHIL REDDYNo ratings yet
- What Are Resource Sharing and Web Challenge in DSDocument18 pagesWhat Are Resource Sharing and Web Challenge in DSdiplomaincomputerengineeringgrNo ratings yet
- Distributed Computing With Python - Sample ChapterDocument18 pagesDistributed Computing With Python - Sample ChapterPackt PublishingNo ratings yet
- Inter ProcessDocument487 pagesInter Processsj314No ratings yet
- CS 330 Operating Systems - Lab ManualDocument68 pagesCS 330 Operating Systems - Lab ManualMohsin AliNo ratings yet
- Mike Ault ORADebug MonographDocument29 pagesMike Ault ORADebug MonographMichael AultNo ratings yet
- A Survey of Parallel Programming Models and Tools in The Multi and Many-Core EraDocument18 pagesA Survey of Parallel Programming Models and Tools in The Multi and Many-Core Eraramon91No ratings yet
- Vxworks Programmers Guide 5-3-1Document652 pagesVxworks Programmers Guide 5-3-1prajnithNo ratings yet
- Parallel DatabasesDocument23 pagesParallel DatabaseshrishikingNo ratings yet
- DBMS Architecture FeaturesDocument30 pagesDBMS Architecture FeaturesFred BloggsNo ratings yet
- The PIM ModelDocument12 pagesThe PIM Modelw96ppcqyknNo ratings yet
- Introduction To Linux For Real-Time Control: Introductory Guidelines and Reference For Control Engi-Neers and ManagersDocument78 pagesIntroduction To Linux For Real-Time Control: Introductory Guidelines and Reference For Control Engi-Neers and ManagersE Ravi EslavathNo ratings yet
- Chapter 1 (A) - Distribted SystemDocument40 pagesChapter 1 (A) - Distribted Systemsiraj mohammedNo ratings yet
- CH 5Document39 pagesCH 5gcrossnNo ratings yet