You might also like
- 1 Class Topics: Syllabus of Statistics 6C 2013-14 Prof. M. Romanazzi March 8, 2014Document2 pages1 Class Topics: Syllabus of Statistics 6C 2013-14 Prof. M. Romanazzi March 8, 2014AlessandroVecellioNo ratings yet
- Inference in HIV Dynamics Models Via Hierarchical LikelihoodDocument27 pagesInference in HIV Dynamics Models Via Hierarchical LikelihoodMsb BruceeNo ratings yet
- 1 s2.0 S0378375806002205 MainDocument10 pages1 s2.0 S0378375806002205 Mainjps.mathematicsNo ratings yet
- Logistic regression knockoffsDocument52 pagesLogistic regression knockoffsvivek thoratNo ratings yet
- Specification and Testing of Some Modified Count Data ModelsDocument25 pagesSpecification and Testing of Some Modified Count Data ModelsSuci IsmadyaNo ratings yet
- Fast and Robust Bootstrap for Multivariate Inference: The R Package FRBDocument32 pagesFast and Robust Bootstrap for Multivariate Inference: The R Package FRBD PNo ratings yet
- Sampling With Censored Data: A Practical Guide: A A, B A, B A ADocument24 pagesSampling With Censored Data: A Practical Guide: A A, B A, B A ALiban Ali MohamudNo ratings yet
- Transactions of Society of Actuaries 1 9 9 5 VOL. 47Document26 pagesTransactions of Society of Actuaries 1 9 9 5 VOL. 47Angel Tec LópezNo ratings yet
- Bayesian Multi-Model Linear Regression in JASPDocument30 pagesBayesian Multi-Model Linear Regression in JASPLuis LuengoNo ratings yet
- Unit3 InferentialnewDocument36 pagesUnit3 InferentialnewArul JothiNo ratings yet
- Taylor & Francis, Ltd. American Statistical AssociationDocument10 pagesTaylor & Francis, Ltd. American Statistical AssociationglareprotectorNo ratings yet
- Model ComparisonDocument13 pagesModel ComparisonMiguel Antonio Barretto GarcíaNo ratings yet
- Sample Size FormulaDocument13 pagesSample Size FormulaAbhik DasNo ratings yet
- Probability and Non-Probability Samples LMU Munich 2022Document22 pagesProbability and Non-Probability Samples LMU Munich 2022mehboob aliNo ratings yet
- Journal of Statistical Software: Mice: Multivariate Imputation by Chained Equations in RDocument67 pagesJournal of Statistical Software: Mice: Multivariate Imputation by Chained Equations in RcinculiranjeNo ratings yet
- Statistical Estimation Methods in Hydrological EngineeringDocument41 pagesStatistical Estimation Methods in Hydrological EngineeringshambelNo ratings yet
- Statistical Treatment of Data, Data Interpretation, and ReliabilityDocument6 pagesStatistical Treatment of Data, Data Interpretation, and Reliabilitydraindrop8606No ratings yet
- A Primer in Nonparametric EconometricsDocument88 pagesA Primer in Nonparametric EconometricsFabian GouretNo ratings yet
- A Nonparametric Mixture Approach To Case-Control Studies With Errors in CovariablesDocument21 pagesA Nonparametric Mixture Approach To Case-Control Studies With Errors in CovariablestestinghbNo ratings yet
- A Comparison of Six Methods For Missing Data Imputation 2155 6180 1000224 PDFDocument6 pagesA Comparison of Six Methods For Missing Data Imputation 2155 6180 1000224 PDFYoussef ChtaibiNo ratings yet
- Received 16 November 2016 Accepted 9 May 2017Document14 pagesReceived 16 November 2016 Accepted 9 May 2017Hamza DhakerNo ratings yet
- Approximate Bayesian Computation For Infectious Disease ModellingDocument12 pagesApproximate Bayesian Computation For Infectious Disease ModellingAldera76No ratings yet
- Comparing Areas Under Correlated ROC Curves Using Nonparametric ApproachDocument10 pagesComparing Areas Under Correlated ROC Curves Using Nonparametric Approachajax_telamonioNo ratings yet
- Model Evaluation and SelectionDocument6 pagesModel Evaluation and SelectionKishore DevineniNo ratings yet
- Data Analysis in LifeCourseEpi - ArticleDocument10 pagesData Analysis in LifeCourseEpi - ArticleShayekh M ArifNo ratings yet
- Concordance C Index - 2 PDFDocument8 pagesConcordance C Index - 2 PDFnuriyesanNo ratings yet
- Test of Homogeneity Based On Geometric Mean of VariancesDocument11 pagesTest of Homogeneity Based On Geometric Mean of VariancesGlobal Research and Development ServicesNo ratings yet
- Web Description MATLABDocument32 pagesWeb Description MATLABnadunnnNo ratings yet
- Comparison - Two Biomech Measure SystemsDocument36 pagesComparison - Two Biomech Measure SystemsmtwakadNo ratings yet
- Chi Square Test in Health SciencesDocument16 pagesChi Square Test in Health SciencesCrisPinosNo ratings yet
- LESSON 7: Non-Parametric Statistics: Tests of Association & Test of HomogeneityDocument21 pagesLESSON 7: Non-Parametric Statistics: Tests of Association & Test of HomogeneityJiyahnBayNo ratings yet
- Koo Che Mesh Kian 2020Document26 pagesKoo Che Mesh Kian 2020Mahdi KarimiNo ratings yet
- Classical Method For Medical SurveyDocument29 pagesClassical Method For Medical SurveyFerra YanuarNo ratings yet
- Joint Modelling Package for Multiple Imputation of Multilevel DataDocument24 pagesJoint Modelling Package for Multiple Imputation of Multilevel DataTyan OrizaNo ratings yet
- Combining Models in Longitudinal Data Analysis: Noname Manuscript No. (Will Be Inserted by The Editor)Document32 pagesCombining Models in Longitudinal Data Analysis: Noname Manuscript No. (Will Be Inserted by The Editor)apocalipsis1999No ratings yet
- Robust RegressionDocument7 pagesRobust Regressionharrison9No ratings yet
- Statistics (Disambiguation)Document12 pagesStatistics (Disambiguation)Reynalyn AbadaNo ratings yet
- Bayesian Latent Variable Models For Mixed Discrete OutcomesDocument15 pagesBayesian Latent Variable Models For Mixed Discrete OutcomesAnonymous 4gOYyVfdfNo ratings yet
- Bayesian Meta-Analysis For Longitudinal Models Using Multivariate Mixture PriorsDocument10 pagesBayesian Meta-Analysis For Longitudinal Models Using Multivariate Mixture Priorstem o0pNo ratings yet
- SIMEX R Package for AFT ModelsDocument14 pagesSIMEX R Package for AFT Modelsxavo_27No ratings yet
- Robust Detection of Multiple Outliers in A Multivariate Data SetDocument30 pagesRobust Detection of Multiple Outliers in A Multivariate Data Setchukwu solomonNo ratings yet
- Chi-Squared Test Explained for Goodness of FitDocument19 pagesChi-Squared Test Explained for Goodness of FitJiisbbbduNo ratings yet
- A Bayesian Approach To Targeted Experiment Design 2012 J. VanlierDocument7 pagesA Bayesian Approach To Targeted Experiment Design 2012 J. VanlierCatalina CasanuevaNo ratings yet
- Conditional Likelihood Maximisation: A Unifying Framework For Information Theoretic Feature SelectionDocument40 pagesConditional Likelihood Maximisation: A Unifying Framework For Information Theoretic Feature SelectionSudhit SethiNo ratings yet
- Envelope No RDocument14 pagesEnvelope No RWagner JorgeNo ratings yet
- Data Analysis Recipes: Fitting A Model To DataDocument55 pagesData Analysis Recipes: Fitting A Model To DataAlankarDuttaNo ratings yet
- Baltagi PoissonDocument37 pagesBaltagi PoissonPino BacadaNo ratings yet
- Estimating Factors via Prediction ErrorsDocument21 pagesEstimating Factors via Prediction ErrorsCristian RamosNo ratings yet
- Multi-Dimensional Causal DiscoveryDocument7 pagesMulti-Dimensional Causal DiscoverysahandNo ratings yet
- An Empirical Test of Respondent Driven Sampling. Point Estimates, Variance, Degree Measures and Out of Equilibrium Data (Wejnert C., 2009)Document64 pagesAn Empirical Test of Respondent Driven Sampling. Point Estimates, Variance, Degree Measures and Out of Equilibrium Data (Wejnert C., 2009)dquartulli5006No ratings yet
- Session 01 - Paper 08Document8 pagesSession 01 - Paper 08Nicholas DawsonNo ratings yet
- Maximum Likelihood Estimation of Limited and Discrete Dependent Variable Models With Nested Random EffectsDocument23 pagesMaximum Likelihood Estimation of Limited and Discrete Dependent Variable Models With Nested Random EffectsJaime NavarroNo ratings yet
- Chi Square in Bio ResearchDocument7 pagesChi Square in Bio ResearchparthajiNo ratings yet
- A Comparison of PLS and ML Bootstrapping Techniques in SEM: A Monte Carlo StudyDocument9 pagesA Comparison of PLS and ML Bootstrapping Techniques in SEM: A Monte Carlo StudyanindyaNo ratings yet
- Sizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangDocument27 pagesSizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangjofrajodiNo ratings yet
- 1 PBDocument32 pages1 PBOyebayo Ridwan OlaniranNo ratings yet
- Decision Tree for Zero-Inflated Count DataDocument15 pagesDecision Tree for Zero-Inflated Count DataAlex Miller100% (1)
- Zeger (1988) Models For Longitudinal Data A Generalized Estimating Equation Approach PDFDocument13 pagesZeger (1988) Models For Longitudinal Data A Generalized Estimating Equation Approach PDFLyly MagnanNo ratings yet
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- Linear and Generalized Linear Mixed Models and Their ApplicationsFrom EverandLinear and Generalized Linear Mixed Models and Their ApplicationsNo ratings yet
- Onomasia Odwn 1905Document1 pageOnomasia Odwn 1905Panagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 16/03/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 16/03/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 07/05/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 07/05/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: SectionDocument2 pagesQuick Search: SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 12/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 12/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 22/05/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 22/05/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Maios Zesti SkoniDocument1 pageMaios Zesti SkoniPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 18/01/1905 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 18/01/1905 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 11/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 11/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Minimum Arc of MovementDocument1 pageMinimum Arc of Movementindian democracyNo ratings yet
- Σκριπ 1905 newspaper archiveDocument1 pageΣκριπ 1905 newspaper archivePanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 17/01/1905 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 17/01/1905 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 07/02/1905 Section Section Section SectionDocument2 pagesQuick Search: Σκριπ 07/02/1905 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Quick Search: Σκριπ 31/12/1904 Section Section Section Section Section SectionDocument1 pageQuick Search: Σκριπ 31/12/1904 Section Section Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Breathing Control: Pistol@tenrings - Co.ukDocument1 pageBreathing Control: Pistol@tenrings - Co.ukmanfromgladNo ratings yet
- Quick Search: Σκριπ 02/08/1904 Section Section Section SectionDocument1 pageQuick Search: Σκριπ 02/08/1904 Section Section Section SectionPanagiotis KarathymiosNo ratings yet
- Statistical Science: Volume 33, Number 2 May 2018Document35 pagesStatistical Science: Volume 33, Number 2 May 2018Panagiotis KarathymiosNo ratings yet
- Bayes Slides1Document146 pagesBayes Slides1Panagiotis KarathymiosNo ratings yet
- Follow Through: Pistol: o o o o oDocument1 pageFollow Through: Pistol: o o o o oPanagiotis KarathymiosNo ratings yet
- ExampleDocument14 pagesExampleKai WikeleyNo ratings yet
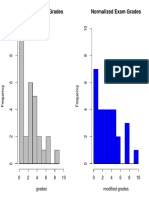
- Original Exam Grades Normalized Exam GradesDocument1 pageOriginal Exam Grades Normalized Exam GradesPanagiotis KarathymiosNo ratings yet
- Applied Artificial Intelligence: GroupDocument7 pagesApplied Artificial Intelligence: GroupPanagiotis KarathymiosNo ratings yet
- Study Reveals Opportunities to Boost Europe's Recreational Boating SectorDocument146 pagesStudy Reveals Opportunities to Boost Europe's Recreational Boating SectorPanagiotis KarathymiosNo ratings yet
- Apagwges 1904Document1 pageApagwges 1904Panagiotis KarathymiosNo ratings yet
- Staff Working Paper No. 865: Making Text Count: Economic Forecasting Using Newspaper TextDocument49 pagesStaff Working Paper No. 865: Making Text Count: Economic Forecasting Using Newspaper TextPanagiotis KarathymiosNo ratings yet
- MartinBarraganLilloRomo JASDocument26 pagesMartinBarraganLilloRomo JASPanagiotis KarathymiosNo ratings yet
- Bayes Notes1Document75 pagesBayes Notes1Alecia SuarezNo ratings yet
- Bayes Notes1Document148 pagesBayes Notes1Panagiotis Karathymios100% (1)
- Missing ValuesDocument16 pagesMissing ValuesPanagiotis KarathymiosNo ratings yet
- Confidence Intervals For The Odds Ratio in Logistic Regression With Two Binary X's PDFDocument10 pagesConfidence Intervals For The Odds Ratio in Logistic Regression With Two Binary X's PDFscjofyWFawlroa2r06YFVabfbajNo ratings yet
- ASS#1-FINALS DoromalDocument8 pagesASS#1-FINALS DoromalAna DoromalNo ratings yet
- Factor Analysis: Factors Influencing The Academic Performance of StudentsDocument54 pagesFactor Analysis: Factors Influencing The Academic Performance of StudentsMusabbirul Islam100% (1)
- Modern Business Statistics With Microsoft Excel 5th Edition Anderson Solutions Manual DownloadDocument22 pagesModern Business Statistics With Microsoft Excel 5th Edition Anderson Solutions Manual DownloadHassan Mccoy100% (30)
- Full Download Ebook PDF The Practice of Statistics For Business and Economics 4th PDFDocument41 pagesFull Download Ebook PDF The Practice of Statistics For Business and Economics 4th PDFkathryn.reynoldson201100% (27)
- TIB Stat 13.3 Quick RefDocument205 pagesTIB Stat 13.3 Quick RefG_ASantosNo ratings yet
- Statistics and Probability DistributionsDocument5 pagesStatistics and Probability DistributionsJohn ClarenceNo ratings yet
- Multivariate Time Series Classification of Sensor Data From An inDocument101 pagesMultivariate Time Series Classification of Sensor Data From An inSaba SuhailNo ratings yet
- Statistics GlossaryDocument3 pagesStatistics Glossaryapi-3836734No ratings yet
- Applied Business Statistics, 7 Ed. by Ken BlackDocument24 pagesApplied Business Statistics, 7 Ed. by Ken BlackKaustubh SaksenaNo ratings yet
- Measurement ErrorsDocument16 pagesMeasurement ErrorsDavid Adeabah OsafoNo ratings yet
- 13-Inference About A PopulationDocument5 pages13-Inference About A PopulationSharlize Veyen RuizNo ratings yet
- Selected History Course of Exit ExamDocument10 pagesSelected History Course of Exit Examalazarala1992100% (1)
- Logistic RegressionDocument35 pagesLogistic RegressionShishir PalNo ratings yet
- Data Science in Context V.99 Web BetaDocument293 pagesData Science in Context V.99 Web BetasemNo ratings yet
- 4 Measures of Central Tendency, Position, Variability PDFDocument24 pages4 Measures of Central Tendency, Position, Variability PDFJenny Estoconing Sardañas Jr.100% (1)
- M.E (FT) 2021 Regulation-Cse SyllabusDocument88 pagesM.E (FT) 2021 Regulation-Cse SyllabusbsudheertecNo ratings yet
- Tutorial 02 Probabilistic Analysis (Swedge) PDFDocument28 pagesTutorial 02 Probabilistic Analysis (Swedge) PDFMao FonzekNo ratings yet
- Waqf-Based Qardhul HassanDocument21 pagesWaqf-Based Qardhul Hassanwanda novitaNo ratings yet
- Final Exam 1Document4 pagesFinal Exam 1HealthyYOU50% (2)
- COSMINDocument9 pagesCOSMINTamires NunesNo ratings yet
- Anti AliasingDocument6 pagesAnti AliasingParth005No ratings yet
- Atrisk User GuideDocument880 pagesAtrisk User GuidecubanninjaNo ratings yet
- BL RSCH 2122 LEC 1922S Inquiries, Investigations and Immersion (VICTOR)Document11 pagesBL RSCH 2122 LEC 1922S Inquiries, Investigations and Immersion (VICTOR)reynaldNo ratings yet
- OBE Syllabus - BUS 5 - Quantitative Techniques To BusinessDocument7 pagesOBE Syllabus - BUS 5 - Quantitative Techniques To Businessyang_1925100% (1)
- Causal Inference in Statistics: An OverviewDocument51 pagesCausal Inference in Statistics: An Overviewaswilson078000100% (1)
- 39120035-S.gokulnath ReportDocument50 pages39120035-S.gokulnath ReportRahul SrinivasNo ratings yet
- Additional Mathematics Syllabus O LevelDocument32 pagesAdditional Mathematics Syllabus O LevelVuyo NgwenyaNo ratings yet
- New Assessment and Prediction For AF FlickerDocument6 pagesNew Assessment and Prediction For AF FlickerWilver SánchezNo ratings yet
- Motivational Factors Impact on PL Engineering EmployeesDocument50 pagesMotivational Factors Impact on PL Engineering EmployeesRam Prakash MauryaNo ratings yet