You might also like
- Research Papers On Wireless Sensor NetworkingDocument5 pagesResearch Papers On Wireless Sensor Networkingfvffv0x7100% (1)
- Machine Learning-Based Network Status Detection and Fault LocalizationDocument10 pagesMachine Learning-Based Network Status Detection and Fault LocalizationJohnNo ratings yet
- Simulation of A Big Number of Microservices in A Highly Distributed Vast NetworkDocument9 pagesSimulation of A Big Number of Microservices in A Highly Distributed Vast NetworkDaniela Beltrán SaavedraNo ratings yet
- 5 Dr. Amit SharmaDocument8 pages5 Dr. Amit SharmaamittechnosoftNo ratings yet
- Wireless Sensor Network Security Thesis PDFDocument9 pagesWireless Sensor Network Security Thesis PDFJennifer Roman100% (2)
- Snossdav 01Document8 pagesSnossdav 01api-3728155No ratings yet
- Effectively Error Detection On Cloud by Using Time Efficient TechniqueDocument3 pagesEffectively Error Detection On Cloud by Using Time Efficient TechniqueKumara SNo ratings yet
- Energy-Aware Distributed Simulation For Mobile Platforms: An Empirical StudyDocument21 pagesEnergy-Aware Distributed Simulation For Mobile Platforms: An Empirical StudyFahad MaqboolNo ratings yet
- VIKASYS Java Proj With Abstract 2011Document12 pagesVIKASYS Java Proj With Abstract 2011vijayabaskar1No ratings yet
- Network Data Management in 5G Network For User Data Privacy - A SurveyDocument6 pagesNetwork Data Management in 5G Network For User Data Privacy - A SurveyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Java/J2Ee Project Abstracts: (Big Data,)Document2 pagesJava/J2Ee Project Abstracts: (Big Data,)infinity InfinityNo ratings yet
- AuditingDocument8 pagesAuditingIamchyNo ratings yet
- Seed Block Algorithm A Remote Smart Data Back-Up Technique For Cloud ComputingDocument5 pagesSeed Block Algorithm A Remote Smart Data Back-Up Technique For Cloud ComputingKarthik BGNo ratings yet
- Grid Computing: 1. AbstractDocument10 pagesGrid Computing: 1. AbstractBhavya DeepthiNo ratings yet
- Synopsis of ML ProjectDocument6 pagesSynopsis of ML Projectsudhakar kethanaNo ratings yet
- Research Thesis On Wireless Sensor NetworksDocument4 pagesResearch Thesis On Wireless Sensor Networkscaitlinwilsonsavannah100% (2)
- Research Paper On Wireless Sensor Network 2013Document4 pagesResearch Paper On Wireless Sensor Network 2013gw131ads100% (1)
- Failover In-DepthDocument4 pagesFailover In-DepthddavarNo ratings yet
- Wireless Sensor Networks Research Papers PDFDocument5 pagesWireless Sensor Networks Research Papers PDFpimywinihyj3100% (1)
- A Survey of Ad Hoc Network Simulators: Mahua DasguptaDocument4 pagesA Survey of Ad Hoc Network Simulators: Mahua DasguptaMahua DasguptaNo ratings yet
- 5G QosDocument6 pages5G QosGERAUDNo ratings yet
- Grid Computing: 1. AbstractDocument10 pagesGrid Computing: 1. AbstractARVINDNo ratings yet
- A Cross-Layer Architecture For Autonomic CommunicationsDocument12 pagesA Cross-Layer Architecture For Autonomic CommunicationsVishabh GoelNo ratings yet
- (IJCST-V10I5P53) :MR D Purushothaman, M NaveenDocument8 pages(IJCST-V10I5P53) :MR D Purushothaman, M NaveenEighthSenseGroupNo ratings yet
- Abdullah 2018Document45 pagesAbdullah 2018mohammed meladNo ratings yet
- Abstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aDocument6 pagesAbstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aVidvek InfoTechNo ratings yet
- Algorithms For Low-Latency Remote File SynchronizationDocument9 pagesAlgorithms For Low-Latency Remote File Synchronizationnortonpjr8815No ratings yet
- Distributed Computing: Information TechnologyDocument19 pagesDistributed Computing: Information TechnologySanskrit KavuruNo ratings yet
- Power Allocation For Wireless MaheshDocument12 pagesPower Allocation For Wireless Maheshuday kiranNo ratings yet
- Data-Driven Booton-Up Cluster-Tree Formation Based On The IEEE 802.15.4 - ZigBee ProtocolsDocument6 pagesData-Driven Booton-Up Cluster-Tree Formation Based On The IEEE 802.15.4 - ZigBee ProtocolsNatanael RibeiroNo ratings yet
- Traffic Control in 5G Heterogenous NetworkDocument5 pagesTraffic Control in 5G Heterogenous Networkvardhanw1757No ratings yet
- Paper 9Document3 pagesPaper 9mbghNo ratings yet
- A Survey of Machine Learning Techniques Applied To SONDocument40 pagesA Survey of Machine Learning Techniques Applied To SONcerenNo ratings yet
- Sensors 19 02981Document47 pagesSensors 19 02981tresaNo ratings yet
- Fair and Comprehensive Benchmarking of Machine Learning Processing ChipsDocument10 pagesFair and Comprehensive Benchmarking of Machine Learning Processing ChipsMubashir AliNo ratings yet
- SDN-Based Load Balancing Scheme For Multi-Controller DeploymentDocument11 pagesSDN-Based Load Balancing Scheme For Multi-Controller Deploymentbhavana.sd86No ratings yet
- Enhancing Cloud Security by Using Hybrid Encryption Scheme: Research PaperDocument7 pagesEnhancing Cloud Security by Using Hybrid Encryption Scheme: Research PaperAli BNo ratings yet
- (IJCST-V6I4P7) :sumanpreet Kaur, Malkit SinghDocument5 pages(IJCST-V6I4P7) :sumanpreet Kaur, Malkit SinghEighthSenseGroupNo ratings yet
- High-Performance Linux Cluster Monitoring Using Java: Curtis Smith and David Henry Linux Networx, IncDocument14 pagesHigh-Performance Linux Cluster Monitoring Using Java: Curtis Smith and David Henry Linux Networx, IncFabryziani Ibrahim Asy Sya'baniNo ratings yet
- Computational: Optimal Fault TolerantDocument6 pagesComputational: Optimal Fault TolerantbhargeshpatelNo ratings yet
- The IX Operating System: Combining Low Latency, High Throughput, and Efficiency in A Protected DataplaneDocument39 pagesThe IX Operating System: Combining Low Latency, High Throughput, and Efficiency in A Protected Dataplanerose jackNo ratings yet
- Sdnizing The Wireless Lan - A Practical Approach: Manzoor A. Khan Patrick Engelhard Tobias DörschDocument6 pagesSdnizing The Wireless Lan - A Practical Approach: Manzoor A. Khan Patrick Engelhard Tobias DörschsiddharthaNo ratings yet
- Expert Systems With Applications: Raquel Barco, Pedro Lázaro, Volker Wille, L. Díez, Sagar PatelDocument8 pagesExpert Systems With Applications: Raquel Barco, Pedro Lázaro, Volker Wille, L. Díez, Sagar PatelNora Alaa El-dinNo ratings yet
- IET Communications - 2022 - Liu - Reliability Modelling and Optimization For Microservice Based Cloud Application UsingDocument18 pagesIET Communications - 2022 - Liu - Reliability Modelling and Optimization For Microservice Based Cloud Application UsingFatima ZohraNo ratings yet
- Cluster Computing: DATE: 28 November 2013Document32 pagesCluster Computing: DATE: 28 November 2013Hasan BadirNo ratings yet
- A.V.C.Colege of Engineering Department of Computer ApplicationsDocument35 pagesA.V.C.Colege of Engineering Department of Computer Applicationsapi-19780718No ratings yet
- Data Center Network Design: Chayan SarkarDocument9 pagesData Center Network Design: Chayan SarkarmamNo ratings yet
- Junior Et Al. - 2019 - A Context-Sensitive Offloading System Using Machine-Learning Classification Algorithms For Mobile Cloud Environme-AnnotatedDocument18 pagesJunior Et Al. - 2019 - A Context-Sensitive Offloading System Using Machine-Learning Classification Algorithms For Mobile Cloud Environme-AnnotatedWARLEY JUNIORNo ratings yet
- Distributed Large-Scale Co-Simulation For Iot-Aided Smart Grid ControlDocument10 pagesDistributed Large-Scale Co-Simulation For Iot-Aided Smart Grid ControldikyNo ratings yet
- Wireless Sensor Networks Research Papers 2014Document8 pagesWireless Sensor Networks Research Papers 2014afedetbma100% (1)
- CSE 423 Virtualization and Cloud Computinglecture0Document16 pagesCSE 423 Virtualization and Cloud Computinglecture0Shahad ShahulNo ratings yet
- Joint Channel Allocation and User Association For Heterogeneous Wireless Cellular NetworksDocument7 pagesJoint Channel Allocation and User Association For Heterogeneous Wireless Cellular NetworkssayondeepNo ratings yet
- Guddanti 2020Document5 pagesGuddanti 2020Anag SystemsNo ratings yet
- A Low-Cost Cloud-Extended Sensor Network For Supervisory ControlDocument6 pagesA Low-Cost Cloud-Extended Sensor Network For Supervisory Controlatlasdz055No ratings yet
- Towards Optimal Network Planning For Software-Defined NetworksDocument15 pagesTowards Optimal Network Planning For Software-Defined Networksjainam lathiyaNo ratings yet
- An OpenFlow Extension For The OMNeT INETDocument8 pagesAn OpenFlow Extension For The OMNeT INETNajib NajibNo ratings yet
- Coacs: A Cooperative and Adaptive Caching System For ManetsDocument17 pagesCoacs: A Cooperative and Adaptive Caching System For ManetsramasamyNo ratings yet
- Architecting A Machine Learning Pipeline For Online Traffic Classification in Software Defined Networking Using SparkDocument13 pagesArchitecting A Machine Learning Pipeline For Online Traffic Classification in Software Defined Networking Using SparkIAES IJAINo ratings yet
- 1 s2.0 S0167739X19312130 MainDocument15 pages1 s2.0 S0167739X19312130 Mainshahbazi.amir1377No ratings yet
- Design and Test Strategies for 2D/3D Integration for NoC-based Multicore ArchitecturesFrom EverandDesign and Test Strategies for 2D/3D Integration for NoC-based Multicore ArchitecturesNo ratings yet
- Buyer Lunch 4 PersonDocument1 pageBuyer Lunch 4 PersonKinjalkumar M. GarasiyaNo ratings yet
- Stick Comperision#Document1 pageStick Comperision#Kinjalkumar M. GarasiyaNo ratings yet
- Multi MeterDocument6 pagesMulti MeterKinjalkumar M. GarasiyaNo ratings yet
- Towards Global Mobile Broadband 1. Introduction: What Is LTE?Document8 pagesTowards Global Mobile Broadband 1. Introduction: What Is LTE?Kinjalkumar M. GarasiyaNo ratings yet
- Project Synopses Water Level ControllerDocument1 pageProject Synopses Water Level ControllerKinjalkumar M. GarasiyaNo ratings yet
- Cobol Array Processing and TablesDocument56 pagesCobol Array Processing and TablesDamnstraightNo ratings yet
- How To Cluster Odoo 12 With PostgreSQL Streaming Replication For High Availability - SeveralninesDocument13 pagesHow To Cluster Odoo 12 With PostgreSQL Streaming Replication For High Availability - SeveralninesIdris IdrisNo ratings yet
- Unary and BinaryDocument11 pagesUnary and Binarysavithunarayana0001No ratings yet
- JPR Java Programming 22412 Msbte Microproject - Msbte Micro Projects - I SchemeDocument12 pagesJPR Java Programming 22412 Msbte Microproject - Msbte Micro Projects - I SchemeAtul GaikwadNo ratings yet
- Build OS2Document216 pagesBuild OS2Tahar AboualaaNo ratings yet
- LAS - GenPhysics2 - Q3 - MELC 48 51 Week 7Document9 pagesLAS - GenPhysics2 - Q3 - MELC 48 51 Week 7nxzomiNo ratings yet
- Kodak DirectView CR 500 - Diagnostics PDFDocument211 pagesKodak DirectView CR 500 - Diagnostics PDFFélix Enríquez100% (1)
- A-Z Placement Guide For Software Dev'S: Land Your Dream Job!Document64 pagesA-Z Placement Guide For Software Dev'S: Land Your Dream Job!Dhruv KhannaNo ratings yet
- Adc 128 S 022Document29 pagesAdc 128 S 022Subhrajit MitraNo ratings yet
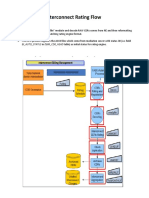
- Interconnect Rating FlowDocument5 pagesInterconnect Rating FlowShahzad AlviNo ratings yet
- Exp 5 Intro To AC Phase ControlDocument8 pagesExp 5 Intro To AC Phase Controlusmpowerlab67% (3)
- Shenzhen Noridc - BLE Sensor AppDocument54 pagesShenzhen Noridc - BLE Sensor AppAlina AnaNo ratings yet
- PM6750 Patient Monitor Module Manual PDFDocument8 pagesPM6750 Patient Monitor Module Manual PDFJuan DuasoNo ratings yet
- PROJECT MANAGER / SYSTEMS ANALYST / PROJECT LEAD or SAP BusinessDocument5 pagesPROJECT MANAGER / SYSTEMS ANALYST / PROJECT LEAD or SAP Businessapi-77565311No ratings yet
- Veyon Admin Manual en - 4.2.4Document67 pagesVeyon Admin Manual en - 4.2.4prototipadoNo ratings yet
- Critical System ValidationDocument13 pagesCritical System ValidationDheeraj SrinathNo ratings yet
- Fortigate Cookbook 504Document220 pagesFortigate Cookbook 504regabriNo ratings yet
- 1.26 File Input-Output in JAVADocument10 pages1.26 File Input-Output in JAVAAjinkyaNo ratings yet
- System Physical ArchitectureDocument5 pagesSystem Physical ArchitectureSanjay SharmaNo ratings yet
- RLU Report Layout UtilityDocument8 pagesRLU Report Layout UtilityVISHNU400100% (1)
- Samsung Ua32eh50x0r 40eh50x0r Ua42eh5000r Ua46eh50x0r-50eh50x0r Ua22es500xr Chassis U73a 74pagesDocument74 pagesSamsung Ua32eh50x0r 40eh50x0r Ua42eh5000r Ua46eh50x0r-50eh50x0r Ua22es500xr Chassis U73a 74pagesWilinton PissoNo ratings yet
- Obiee 11g - Performance Tuning Real Success StoriesDocument60 pagesObiee 11g - Performance Tuning Real Success Storiesyugandhar_chNo ratings yet
- CST307Document12 pagesCST307Ajnamol N RNo ratings yet
- 华南X99 F8D主板说明书 9Document1 page华南X99 F8D主板说明书 9messiahsNo ratings yet
- ServiceManual 731Q ENGDocument19 pagesServiceManual 731Q ENGRodrigo MendozaNo ratings yet
- Chapter - 5 - v8.0 Network Layer - Control PlaneDocument107 pagesChapter - 5 - v8.0 Network Layer - Control PlaneTrần HoàngNo ratings yet
- Pulse Oximeter Design Using Microchip's dsPICDocument14 pagesPulse Oximeter Design Using Microchip's dsPICpeter26194No ratings yet
- JBL MRX612M Specsheet Eng 20140724Document2 pagesJBL MRX612M Specsheet Eng 20140724casefaNo ratings yet
- Support Note #34 - Update NOAHlink Driver - Ver. 6Document15 pagesSupport Note #34 - Update NOAHlink Driver - Ver. 6overNo ratings yet
- Computer Fundamentals MODULE 1 LESSON 1Document7 pagesComputer Fundamentals MODULE 1 LESSON 1Delia PenoringanNo ratings yet