You might also like
- Java Servlets: Powerful Server-Side ComponentsDocument5 pagesJava Servlets: Powerful Server-Side ComponentsVivek AnanthNo ratings yet
- 1.JAVA MODULE6 ServletDocument59 pages1.JAVA MODULE6 Servletsuyash agarwalNo ratings yet
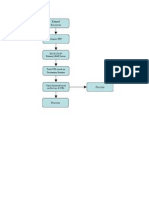
- Life Cycle of Servlet: Loading and Inatantiation: The Servlet Container Loads The Servlet DuringDocument21 pagesLife Cycle of Servlet: Loading and Inatantiation: The Servlet Container Loads The Servlet DuringBharadwaj UpadhyaNo ratings yet
- Advance java notesDocument32 pagesAdvance java notesdevillucifer2411No ratings yet
- What Is A ServletDocument21 pagesWhat Is A Servletrajdeep_chakrobortyNo ratings yet
- Servlet Interface in Java: Servlet Life Cycle StepsDocument23 pagesServlet Interface in Java: Servlet Life Cycle StepsFike FikirNo ratings yet
- Serv LetsDocument11 pagesServ LetsakurathikotaiahNo ratings yet
- Servelet and JSPDocument23 pagesServelet and JSPSatyamNo ratings yet
- Java ServletsDocument16 pagesJava ServletsPrasadaRaoNo ratings yet
- Unit IV - ServletDocument47 pagesUnit IV - ServletHitesh KumarNo ratings yet
- Servlets - Introduction: o o o o oDocument19 pagesServlets - Introduction: o o o o oPreethaNo ratings yet
- 16 ServletsDocument28 pages16 ServletsPrasad SNo ratings yet
- What Is A Servlet?: Advantages of Using ServletsDocument31 pagesWhat Is A Servlet?: Advantages of Using Servletshash hashNo ratings yet
- Servlets NotesDocument35 pagesServlets NotesMohammed Jeelan100% (1)
- Serv Let LifecycleDocument1 pageServ Let Lifecyclepardhu_luckyNo ratings yet
- ServletqbDocument17 pagesServletqbAmol AdhangaleNo ratings yet
- Servlet NotesDocument16 pagesServlet NoteslakshmiNo ratings yet
- Ass 3Document18 pagesAss 3yashthummar003No ratings yet
- Servlet NotesDocument4 pagesServlet NotesKaran ShahNo ratings yet
- SCWCDDocument18 pagesSCWCDbookworm094No ratings yet
- Servlet Interview QuestionsDocument5 pagesServlet Interview QuestionsksgdbaNo ratings yet
- Chapter 3Document48 pagesChapter 3Faizan DangeNo ratings yet
- Servlets: Introduction to Java ServletsDocument94 pagesServlets: Introduction to Java ServletsDipanjan GhoshNo ratings yet
- MaterialsDocument2 pagesMaterialsshazz_shivangNo ratings yet
- Qué son los Servlets? Java Servlets explicadosDocument8 pagesQué son los Servlets? Java Servlets explicadosmamaguevoNo ratings yet
- UNIT-4: School of Computing Science and EngineeringDocument19 pagesUNIT-4: School of Computing Science and EngineeringVella LogNo ratings yet
- Q1. Explain Servlet Life Cycle With Example To Demonstrate Every State (Page 259)Document14 pagesQ1. Explain Servlet Life Cycle With Example To Demonstrate Every State (Page 259)Sannisth SoniNo ratings yet
- Web Applications: Anatomy of A URLDocument3 pagesWeb Applications: Anatomy of A URLFeisal MohamedNo ratings yet
- Servlet Interview Questions and AnswersDocument4 pagesServlet Interview Questions and AnswersrajinishNo ratings yet
- Servlet Basics: Servlet Technology Is Used To Create Web Application (Resides at Server Side and Generates DynamicDocument41 pagesServlet Basics: Servlet Technology Is Used To Create Web Application (Resides at Server Side and Generates DynamicDivya guptaNo ratings yet
- SERVLETS Class NotesDocument20 pagesSERVLETS Class NotesChakri SuhasNo ratings yet
- Introduction to Servlet TechnologyDocument17 pagesIntroduction to Servlet TechnologyShiva Kumar YadavNo ratings yet
- How servlets work under the hoodDocument4 pagesHow servlets work under the hoodShubham MittalNo ratings yet
- Servlets Advance Java by Biswajit SahaDocument57 pagesServlets Advance Java by Biswajit SahaArgha SenNo ratings yet
- Web Technologies Servlet NotesDocument24 pagesWeb Technologies Servlet NotesKasaragadda MahanthiNo ratings yet
- Introduction To Java Servlets: Vijayan Sugumaran School of Business Administration Oakland UniversityDocument38 pagesIntroduction To Java Servlets: Vijayan Sugumaran School of Business Administration Oakland Universityishaq_execlNo ratings yet
- Unit7 Servlets and Java Server PageDocument20 pagesUnit7 Servlets and Java Server PagePrabesh KarkiNo ratings yet
- What Are Servlets?Document4 pagesWhat Are Servlets?sai krishnaNo ratings yet
- Unit 2Document56 pagesUnit 2085 - Hemangi SabalparaNo ratings yet
- ServletDocument11 pagesServletr40000227No ratings yet
- The Servlets Technology ModelDocument29 pagesThe Servlets Technology Modelapi-3775545No ratings yet
- WT Unit3Document28 pagesWT Unit3Hari MNo ratings yet
- Invoking Servlet From HTML Forms: Ex - No:6a DateDocument6 pagesInvoking Servlet From HTML Forms: Ex - No:6a DatesaleemfawaazNo ratings yet
- Chapter 06 Servletppt 1Document75 pagesChapter 06 Servletppt 1IF 06 Anjali BhamareNo ratings yet
- My Note About Java Servlet 1687330648Document19 pagesMy Note About Java Servlet 1687330648raji98No ratings yet
- Chapter 3Document11 pagesChapter 3swarajpatil180No ratings yet
- Java Servlets Complete Reference GuideDocument35 pagesJava Servlets Complete Reference GuideSudhanshu PrasadNo ratings yet
- Introduction To ServletDocument29 pagesIntroduction To Servletapi-3775545No ratings yet
- Cse-Vii-Java and J2ee U6Document7 pagesCse-Vii-Java and J2ee U6abhijitddas19No ratings yet
- Unit-I ServletsDocument25 pagesUnit-I ServletsSamuelNo ratings yet
- Servlets (Autosaved)Document105 pagesServlets (Autosaved)Huda AlmustafaNo ratings yet
- Ex No: 6A Invoking Servlet From HTML FormsDocument7 pagesEx No: 6A Invoking Servlet From HTML FormspediatechNo ratings yet
- UNIT III - Web Servers and ServletsDocument23 pagesUNIT III - Web Servers and Servletsneed qNo ratings yet
- Ip Unit IiiDocument45 pagesIp Unit Iiiiyyanarappan aNo ratings yet
- Introduction To ServletDocument9 pagesIntroduction To ServletAjay YadavNo ratings yet
- IAT-2 JavaDocument25 pagesIAT-2 JavaMeera SahooNo ratings yet
- Introduction To Servlet Life Cycle-1Document9 pagesIntroduction To Servlet Life Cycle-1vivek_championNo ratings yet
- ServletsDocument25 pagesServletsSherril VincentNo ratings yet
- JSP-Servlet Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandJSP-Servlet Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Spring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudFrom EverandSpring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudNo ratings yet
- Automotive Interface Integration Whitepaper D6Document7 pagesAutomotive Interface Integration Whitepaper D6kishorekumarreddymNo ratings yet
- Short Message Peer To Peer Protocol Specification v3.4Document169 pagesShort Message Peer To Peer Protocol Specification v3.4Sharon Gilmore100% (1)
- Bell Atlantic Supplement Common Channel Signaling (CCS) Network Interface SpecificationDocument83 pagesBell Atlantic Supplement Common Channel Signaling (CCS) Network Interface SpecificationGreg WilliamsNo ratings yet
- KannelDocument1 pageKannelkishorekumarreddymNo ratings yet
- 3115l8-1e 3Document7 pages3115l8-1e 3kishorekumarreddymNo ratings yet
- Websocket: Websocket Is A Computer Communications Protocol, ProvidingDocument9 pagesWebsocket: Websocket Is A Computer Communications Protocol, ProvidingCalin SeitanNo ratings yet
- The Basics of CSSDocument40 pagesThe Basics of CSSXelwiin BongonNo ratings yet
- Website Review - SEOptimer PDFDocument21 pagesWebsite Review - SEOptimer PDFPriyansh AgarwalNo ratings yet
- HTML To XML ParserDocument3 pagesHTML To XML ParserAhmadNo ratings yet
- Sites Da Freenet - by Saiba Na WebDocument5 pagesSites Da Freenet - by Saiba Na WebBreno MalinconicoNo ratings yet
- Unit 1 - Understand The Principles of Web DesigningDocument263 pagesUnit 1 - Understand The Principles of Web DesigningAsmatullah KhanNo ratings yet
- Simple Login With CodeIgniter in PHP - Code FactoryDocument12 pagesSimple Login With CodeIgniter in PHP - Code FactoryMulfin SyarifinNo ratings yet
- SAP UI5 - FIORI OData NW Gateway - Syllabus SheetDocument12 pagesSAP UI5 - FIORI OData NW Gateway - Syllabus Sheetorkut verificationNo ratings yet
- Active Server PageDocument10 pagesActive Server Pageponraj_89100% (2)
- Blueprint Css 1 0 Cheatsheet 4 2 GjmsDocument2 pagesBlueprint Css 1 0 Cheatsheet 4 2 GjmsAnes NeziricNo ratings yet
- Python TutorialDocument13 pagesPython TutorialImran HossenNo ratings yet
- WCF REST POST XML Bad Request ErrorDocument3 pagesWCF REST POST XML Bad Request ErrorRajesh SamanthNo ratings yet
- Security Penetration Test Report of VULNWEB PDFDocument12 pagesSecurity Penetration Test Report of VULNWEB PDFBão Đêm29% (7)
- HTML5 Semantic Elements Guide: What They Are and How to Use ThemDocument9 pagesHTML5 Semantic Elements Guide: What They Are and How to Use ThemClaire AsagraNo ratings yet
- HTML 5 and CSS3Document40 pagesHTML 5 and CSS3Aarti karpeNo ratings yet
- Easy Roles and Permissions in Laravel 5 - QCode PDFDocument88 pagesEasy Roles and Permissions in Laravel 5 - QCode PDFmoha nehaNo ratings yet
- Jumboo ListsDocument36 pagesJumboo ListsMuhammad AkramNo ratings yet
- 29-30 Web Services PDFDocument31 pages29-30 Web Services PDFjunaid ahmedNo ratings yet
- CSS IntroductionDocument15 pagesCSS IntroductionHanane EsiNo ratings yet
- Affected ItemsDocument9 pagesAffected ItemsAvosthe Programming & GamingNo ratings yet
- Research and Application of Ajax TechnologyDocument18 pagesResearch and Application of Ajax TechnologySachin Ganesh ShettigarNo ratings yet
- A Intership Report: Visvesvaraya Technological UniversityDocument31 pagesA Intership Report: Visvesvaraya Technological UniversityVidya BachaspatiNo ratings yet
- Js SDK DV PDFDocument268 pagesJs SDK DV PDFRaghvendra YadavNo ratings yet
- Philip Schultz Resume FinalDocument1 pagePhilip Schultz Resume Finalapi-475474136No ratings yet
- HTML Form Technical Test ResultsDocument37 pagesHTML Form Technical Test Results18cp47 Jay PrajapatiNo ratings yet
- HTML - Multiple Web FramesetDocument8 pagesHTML - Multiple Web FramesetSourav NayakNo ratings yet
- Practical-12: & Content PageDocument3 pagesPractical-12: & Content PageyagneshNo ratings yet
- IPlanet XFFDocument3 pagesIPlanet XFFpeterjackson1No ratings yet
- Chapter 8 Sprite Animation Techniques 2Document26 pagesChapter 8 Sprite Animation Techniques 2Mrinaalini SelvarajanNo ratings yet
- JavaFX CSSDocument9 pagesJavaFX CSSramesh0% (1)