You might also like
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonFrom EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonNo ratings yet
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- NowakowskiG NeuralnetworkDocument10 pagesNowakowskiG NeuralnetworkElena MiceliNo ratings yet
- 2002 AnnDocument16 pages2002 AnnmohamedNo ratings yet
- Coop Mwscas2012Document4 pagesCoop Mwscas2012Robert CoopNo ratings yet
- OpTorch Optimized Deep Learning Architectures ForDocument7 pagesOpTorch Optimized Deep Learning Architectures ForFree SyncNo ratings yet
- Image Classification With Feed-Forward Neural Networks: Meller, Matula and ChłądDocument7 pagesImage Classification With Feed-Forward Neural Networks: Meller, Matula and ChłądSoumini PortfolioNo ratings yet
- Fault TolerantDocument10 pagesFault TolerantKmp SathishkumarNo ratings yet
- Neural Network EnsemblesDocument9 pagesNeural Network EnsembleskronalizedNo ratings yet
- ReqDocument62 pagesReqAnurag KhannaNo ratings yet
- Throughput-Optimal Broadcast in WirelessDocument15 pagesThroughput-Optimal Broadcast in WirelessCIRI CORPORATENo ratings yet
- Gacnn - Training Deep Convolutional Neural Networks With Genetic AlgorithmDocument4 pagesGacnn - Training Deep Convolutional Neural Networks With Genetic Algorithmeuler saxenaNo ratings yet
- Article NNOptimizationDocument8 pagesArticle NNOptimizationAmrou AkroutiNo ratings yet
- Capability Based RoutingDocument25 pagesCapability Based RoutingVeershettyNo ratings yet
- Causal Model Based On ANNDocument6 pagesCausal Model Based On ANNdeesingNo ratings yet
- Training Feed Forward NN With Genetic AlgoDocument6 pagesTraining Feed Forward NN With Genetic Algosriram_vikrantNo ratings yet
- Hidden Neurons PDFDocument12 pagesHidden Neurons PDFmanojaNo ratings yet
- Neural Networks Learning Improvement Using The K-Means Clustering Algorithm To Detect Network IntrusionsDocument8 pagesNeural Networks Learning Improvement Using The K-Means Clustering Algorithm To Detect Network IntrusionsGowtham GowthamNo ratings yet
- End-to-End Deep Learning-Based Compressive Spectrum Sensing in Cognitive Radio NetworksDocument6 pagesEnd-to-End Deep Learning-Based Compressive Spectrum Sensing in Cognitive Radio NetworksRock Feller Singh RussellsNo ratings yet
- Super NodesDocument6 pagesSuper Nodesmanojice2010No ratings yet
- P C N N R E I: Runing Onvolutional Eural Etworks FOR Esource Fficient NferenceDocument17 pagesP C N N R E I: Runing Onvolutional Eural Etworks FOR Esource Fficient NferenceAnshul VijayNo ratings yet
- Secured RobustnessDocument5 pagesSecured RobustnessSrijaNo ratings yet
- Continual Learning of Context-Dependent Processing in Neural NetworksDocument18 pagesContinual Learning of Context-Dependent Processing in Neural Networks008 BHAVY SHUKLANo ratings yet
- Multilayer Perceptron PDFDocument5 pagesMultilayer Perceptron PDFAquacypressNo ratings yet
- Data Mining Techniques in Coginitive Radio Network For Smart Home EnvironmentDocument7 pagesData Mining Techniques in Coginitive Radio Network For Smart Home Environmentdr mbaluNo ratings yet
- Multilayer Perceptron: Architecture Optimization and TrainingDocument5 pagesMultilayer Perceptron: Architecture Optimization and TrainingaliceNo ratings yet
- Resiliency of Deep Neural Networks Under QuantizationsDocument11 pagesResiliency of Deep Neural Networks Under QuantizationsGod GamingNo ratings yet
- 1710 11573 PDFDocument14 pages1710 11573 PDFAshish SharmaNo ratings yet
- Beyond Signal Propagation: Is Feature Diversity Necessary in Deep Neural Network Initialization?Document10 pagesBeyond Signal Propagation: Is Feature Diversity Necessary in Deep Neural Network Initialization?Bladimir AponteNo ratings yet
- H-Name: A Hidden-Node Avoidance Mechanism For Wireless Sensor NetworksDocument10 pagesH-Name: A Hidden-Node Avoidance Mechanism For Wireless Sensor NetworksMahesh MiriyalaNo ratings yet
- Neural Networks Thesis Final ChristofferMagnusDocument36 pagesNeural Networks Thesis Final ChristofferMagnusSyahrul SazaNo ratings yet
- Fast Algorithms For Convolutional Neural Networks: Andrew Lavin Scott Gray Nervana SystemsDocument9 pagesFast Algorithms For Convolutional Neural Networks: Andrew Lavin Scott Gray Nervana SystemssharkieNo ratings yet
- Tnnls Coop 2013Document12 pagesTnnls Coop 2013Robert CoopNo ratings yet
- Feng Liang Et Al - 2021 - Efficient Neural Network Using Pointwise Convolution Kernels With Linear PhaseDocument8 pagesFeng Liang Et Al - 2021 - Efficient Neural Network Using Pointwise Convolution Kernels With Linear Phasebigliang98No ratings yet
- Decoupled Greedy Learning of CNNsDocument14 pagesDecoupled Greedy Learning of CNNszentropiaNo ratings yet
- Ai ML Important QuestionsDocument21 pagesAi ML Important Questionsneha praveenNo ratings yet
- Simple Is Good Investigation of History State Ensemble Deep Neu - 2023 - NeurocDocument15 pagesSimple Is Good Investigation of History State Ensemble Deep Neu - 2023 - NeurocSumeet MitraNo ratings yet
- Image Based ClassificationDocument8 pagesImage Based ClassificationMuhammad Sami UllahNo ratings yet
- Artificial Intelligence and Prediction of RockDocument5 pagesArtificial Intelligence and Prediction of RockManuel AragonNo ratings yet
- Learning To DetectDocument11 pagesLearning To DetectSeckinNo ratings yet
- Artificial Neural Networks Hidden Unit and Weight Connection Optimization by Quasi-Refection-Based Learning Artificial Bee Colony AlgorithmDocument21 pagesArtificial Neural Networks Hidden Unit and Weight Connection Optimization by Quasi-Refection-Based Learning Artificial Bee Colony AlgorithmGichuru MuthomiNo ratings yet
- A Pneumonia Detection Method Based On ImprovedDocument6 pagesA Pneumonia Detection Method Based On ImprovedAmílcar CáceresNo ratings yet
- CNN Interspeech2013 PubDocument5 pagesCNN Interspeech2013 Pubjmanuel.cidpNo ratings yet
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyNo ratings yet
- Scaling Up Exact Neural Network Compression by Relu StabilityDocument30 pagesScaling Up Exact Neural Network Compression by Relu StabilityAbhinavNo ratings yet
- Gaoningning 2010Document4 pagesGaoningning 2010smritii bansalNo ratings yet
- KD-Lib - A PyTorch Library For Knowledge Distillation, Pruning and QuantizationDocument4 pagesKD-Lib - A PyTorch Library For Knowledge Distillation, Pruning and Quantizationdaniel.syahputraNo ratings yet
- 2001 11542 PDFDocument5 pages2001 11542 PDFshivam khandelwalNo ratings yet
- Master Thesis Neural NetworkDocument4 pagesMaster Thesis Neural Networktonichristensenaurora100% (1)
- Genetic CNNDocument10 pagesGenetic CNNserpsaipong navanuraksaNo ratings yet
- Optimum Architecture of Neural Networks Lane Following SystemDocument6 pagesOptimum Architecture of Neural Networks Lane Following SystemJ.No ratings yet
- Environmental Sound Classificationwith Convolutional Neural NetworksDocument6 pagesEnvironmental Sound Classificationwith Convolutional Neural Networksamine hamdiNo ratings yet
- Ontology Concept Extraction Algorithm For Deep Neural NetworksDocument6 pagesOntology Concept Extraction Algorithm For Deep Neural NetworksThiago Raulino Dal PontNo ratings yet
- 3.WSN Research PaperDocument6 pages3.WSN Research Paperjagroop kaurNo ratings yet
- Improving Network Training On Resource-ConstrainedDocument16 pagesImproving Network Training On Resource-ConstrainedPiyush KushwahNo ratings yet
- Optimizing Coverage and Capacity in Cellular Networks Using Machine LearningDocument5 pagesOptimizing Coverage and Capacity in Cellular Networks Using Machine LearningmarceloantoniokazamaNo ratings yet
- Capability Based Routing With Security Using Mobile Agents and Threat Locator Mechanism in Wireless Mesh NetworksDocument24 pagesCapability Based Routing With Security Using Mobile Agents and Threat Locator Mechanism in Wireless Mesh NetworksVeershettyNo ratings yet
- Evolutionary Neural Networks For Product Design TasksDocument11 pagesEvolutionary Neural Networks For Product Design TasksjlolazaNo ratings yet
- Deep Leraning Al VacioDocument5 pagesDeep Leraning Al VacioJuan Carlos RojasNo ratings yet
- Learning in Memristive Neural Network Architectures Using Analog Backpropagation CircuitsDocument14 pagesLearning in Memristive Neural Network Architectures Using Analog Backpropagation CircuitsHussain Bin AliNo ratings yet
- Interaction of EM Radiation and MatterDocument3 pagesInteraction of EM Radiation and MattercoolhemakumarNo ratings yet
- V / F ConverterDocument8 pagesV / F ConvertercoolhemakumarNo ratings yet
- Instrumental Analysis Lecture Notes IIIDocument62 pagesInstrumental Analysis Lecture Notes IIIcoolhemakumar100% (1)
- Instrumental Analysis Lecture Notes IIDocument56 pagesInstrumental Analysis Lecture Notes IIcoolhemakumar100% (3)
- Interfacing To Microprocessor ControllerDocument14 pagesInterfacing To Microprocessor ControllercoolhemakumarNo ratings yet
- Instrument Control Uning LABVIEWDocument69 pagesInstrument Control Uning LABVIEWcoolhemakumarNo ratings yet
- IR Spectroscopy BasicsDocument16 pagesIR Spectroscopy BasicscoolhemakumarNo ratings yet
- Virtual Instrumentation ArchitectureDocument25 pagesVirtual Instrumentation Architecturecoolhemakumar100% (8)
- Electromagnetic RadiationDocument2 pagesElectromagnetic RadiationcoolhemakumarNo ratings yet
- LabVIEW IntroductionDocument89 pagesLabVIEW Introductioncoolhemakumar100% (1)
- Mass SpectrometryDocument19 pagesMass SpectrometrycoolhemakumarNo ratings yet
- Electron Spin ResonanceDocument29 pagesElectron Spin Resonancecoolhemakumar100% (2)
- Basics of V/F and F/V ConvertersDocument11 pagesBasics of V/F and F/V ConverterscoolhemakumarNo ratings yet
- Unit 7 Flame PhotometryDocument32 pagesUnit 7 Flame PhotometryRia Agnez100% (8)
- Mass SpecDocument38 pagesMass SpecRashi VermaNo ratings yet
- Displacement and PositionDocument6 pagesDisplacement and PositioncoolhemakumarNo ratings yet
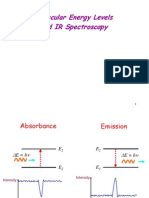
- Molecular Energy Levels and IR SpectrosDocument27 pagesMolecular Energy Levels and IR SpectroscoolhemakumarNo ratings yet
- Automation in DVMsDocument7 pagesAutomation in DVMscoolhemakumarNo ratings yet
- Energy Levels and Transitions in AtomsDocument7 pagesEnergy Levels and Transitions in AtomscoolhemakumarNo ratings yet
- Instrumental Methods of Analysis Lesson NotesDocument80 pagesInstrumental Methods of Analysis Lesson NotescoolhemakumarNo ratings yet
- NMR Spectroscopy - Short NoteDocument6 pagesNMR Spectroscopy - Short Notecoolhemakumar100% (4)
- NMRDocument142 pagesNMRMaulana Senjaya SusiloNo ratings yet
- Mass Spectrometry - Short NoteDocument2 pagesMass Spectrometry - Short NotecoolhemakumarNo ratings yet
- Digital and Pulse-Train Conditioning: Digital I/O InterfacingDocument6 pagesDigital and Pulse-Train Conditioning: Digital I/O InterfacingcoolhemakumarNo ratings yet
- NMR SpectrometerDocument13 pagesNMR SpectrometercoolhemakumarNo ratings yet
- Virtual Instrumentation SystemsDocument7 pagesVirtual Instrumentation SystemscoolhemakumarNo ratings yet
- What Is Modular InstrumentationDocument7 pagesWhat Is Modular InstrumentationcoolhemakumarNo ratings yet
- AN713 - Controller Area Network (CAN) BasicsDocument9 pagesAN713 - Controller Area Network (CAN) BasicsRam Krishan SharmaNo ratings yet
- CASE ToolsDocument5 pagesCASE ToolscoolhemakumarNo ratings yet
- Hart TutorialDocument6 pagesHart TutorialabhiklNo ratings yet
- Business Negotiation - BcomDocument12 pagesBusiness Negotiation - BcomShruti ThakkarNo ratings yet
- Bristol Skills FrameworkDocument3 pagesBristol Skills FrameworkLetitia100% (1)
- Team Management: By:-Akshara Saxena B.A.S.L.P Second YearDocument18 pagesTeam Management: By:-Akshara Saxena B.A.S.L.P Second YearAkshara SaxenaNo ratings yet
- Hallinger Murphy 1985Document33 pagesHallinger Murphy 1985Ivy marie SollerNo ratings yet
- Five Senses Lp2Document2 pagesFive Senses Lp2aputtNo ratings yet
- GMAT Pill E-BookDocument121 pagesGMAT Pill E-BookNeeleshk21No ratings yet
- Pengembangan Produk BaruDocument13 pagesPengembangan Produk BaruMuhammad FauziNo ratings yet
- Mba Project For Business IntelligentDocument9 pagesMba Project For Business Intelligentlarry_macaulay100% (3)
- LSE Study Toolkit Resource Introduction To Essay WritingDocument31 pagesLSE Study Toolkit Resource Introduction To Essay Writingjoseph ThiyagarjanNo ratings yet
- Marked Assignment 2 Cover PageDocument3 pagesMarked Assignment 2 Cover Pageapi-286920768No ratings yet
- Rubric LNG401 Mock InterviewDocument3 pagesRubric LNG401 Mock InterviewSuheiyla Abdul AzizNo ratings yet
- AECS Lab ManualDocument69 pagesAECS Lab ManuallemuelgeorgeNo ratings yet
- 5.1 Tourist MotivationDocument17 pages5.1 Tourist MotivationMakhliyo YurievaNo ratings yet
- Alfie Meiling - Unit 1 2 - Media Methods Skills and Production TechniquDocument5 pagesAlfie Meiling - Unit 1 2 - Media Methods Skills and Production Techniquapi-370719927No ratings yet
- Shoulder Pain and Disability Index (Spadi) PDFDocument2 pagesShoulder Pain and Disability Index (Spadi) PDFOscar NgNo ratings yet
- Long Test in PR 1Document1 pageLong Test in PR 1Beverly Joy BragaisNo ratings yet
- Module 4 Lesson 4.1Document17 pagesModule 4 Lesson 4.1mrasonable1027No ratings yet
- Elephant Ears Lesson PlanDocument5 pagesElephant Ears Lesson Planapi-350986237No ratings yet
- Docslide - Us Fp601-CyberpreneurshipDocument4 pagesDocslide - Us Fp601-CyberpreneurshipKadem AmirudinNo ratings yet
- Guide To Task Specific Clarifications PDFDocument2 pagesGuide To Task Specific Clarifications PDFzarna nirmal rawalNo ratings yet
- Storyboard PorfolioDocument10 pagesStoryboard Porfolioapi-641534972No ratings yet
- The Process of Materials Development (General View of The Cycle)Document12 pagesThe Process of Materials Development (General View of The Cycle)Christian Dale Esquivel AraujoNo ratings yet
- Administrative Behavior in EducationDocument2 pagesAdministrative Behavior in EducationEllah Taguna AraoNo ratings yet
- 04) Reading Vocabulary QuestionDocument3 pages04) Reading Vocabulary Question鄭少綸No ratings yet
- Police Personnel and Records ManagementDocument14 pagesPolice Personnel and Records ManagementJordine Umayam100% (1)
- File Test 4 A Answer Key: Grammar, Vocabulary, and PronunciationDocument3 pagesFile Test 4 A Answer Key: Grammar, Vocabulary, and PronunciationB Mc75% (4)
- The SEN Handbook For Trainee TeachersDocument135 pagesThe SEN Handbook For Trainee TeachersAndrej Hodonj100% (2)
- IIFT - Entrepreneurship-Course - Outline - Rev 2Document8 pagesIIFT - Entrepreneurship-Course - Outline - Rev 2Deepak PanditNo ratings yet
- Enneagram Logo Brief ObjectiveDocument4 pagesEnneagram Logo Brief ObjectivemeykotputraNo ratings yet
- Letter of Rec - Department Chair 1Document1 pageLetter of Rec - Department Chair 1api-285300958No ratings yet