You might also like
- SadDocument1 pageSadQQC_DiaryNo ratings yet
- SadfDocument2 pagesSadfQQC_DiaryNo ratings yet
- Read MeDocument1 pageRead MeQQC_DiaryNo ratings yet
- Sports Quiz FinalsDocument87 pagesSports Quiz FinalsQQC_DiaryNo ratings yet
- Sports Quiz PrelimsDocument21 pagesSports Quiz PrelimsQQC_DiaryNo ratings yet
- The General Quiz: CommanderDocument106 pagesThe General Quiz: CommanderQQC_DiaryNo ratings yet
- Prelims - Questions OnlyDocument24 pagesPrelims - Questions OnlyQQC_DiaryNo ratings yet
- QQC Sci Tech PrilimsDocument23 pagesQQC Sci Tech PrilimsQQC_DiaryNo ratings yet
- QQC Sci Tech FinalsDocument49 pagesQQC Sci Tech FinalsQQC_DiaryNo ratings yet
- General Quiz - Preliminary Round (Presented by Quotient Quiz Club)Document3 pagesGeneral Quiz - Preliminary Round (Presented by Quotient Quiz Club)QQC_DiaryNo ratings yet
- General Quiz-Finals: Abhilash B R Sriram GDocument73 pagesGeneral Quiz-Finals: Abhilash B R Sriram GQQC_DiaryNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Very High Frequency Omni-Directional Range: Alejandro Patt CarrionDocument21 pagesVery High Frequency Omni-Directional Range: Alejandro Patt CarrionAlejandro PattNo ratings yet
- Action Research MethodDocument27 pagesAction Research MethodNiño Czar RaroNo ratings yet
- Reaction PaperDocument2 pagesReaction PaperMisna Blasco Zurbano50% (2)
- Indian Standard: Methods of Test For Aggregates For ConcreteDocument22 pagesIndian Standard: Methods of Test For Aggregates For ConcreteAnuradhaPatraNo ratings yet
- 82 - Engineering Mechanics Refresher SetDocument6 pages82 - Engineering Mechanics Refresher Setdevilene nayazakoNo ratings yet
- Art & Science: Meeting The Needs of Patients' Families in Intensive Care UnitsDocument8 pagesArt & Science: Meeting The Needs of Patients' Families in Intensive Care UnitsRiaNo ratings yet
- Best IIT JEE NEET and ICSE, CBSE, SSC Classes in Hadapsar PuneDocument18 pagesBest IIT JEE NEET and ICSE, CBSE, SSC Classes in Hadapsar PuneTrinity AcademyNo ratings yet
- Interweave Fiber Catalog Fall 2009Document56 pagesInterweave Fiber Catalog Fall 2009Interweave100% (1)
- 2.talent Management New ChallengesDocument17 pages2.talent Management New ChallengesAlejandra AGNo ratings yet
- Frequency Spectrum On XXX OperatorsDocument4 pagesFrequency Spectrum On XXX OperatorsPeng Yuan FengNo ratings yet
- List of ItemsDocument5 pagesList of ItemsMoiNo ratings yet
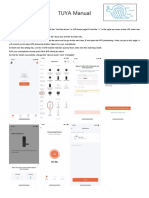
- TUYA ManualDocument2 pagesTUYA ManualMagandang MallNo ratings yet
- Supg NS 2DDocument15 pagesSupg NS 2DruNo ratings yet
- An Example of A Rating Scale To Q4Document4 pagesAn Example of A Rating Scale To Q4Zeeshan ch 'Hadi'No ratings yet
- Week 1 - Intrduction To Nursing Research - StudentDocument24 pagesWeek 1 - Intrduction To Nursing Research - StudentWani GhootenNo ratings yet
- Title DefenseDocument3 pagesTitle DefenseLiezl Sabado100% (1)
- BONENT Candidate Handbook PDFDocument28 pagesBONENT Candidate Handbook PDFParshanwa Johnson100% (1)
- Report On Mango Cultivation ProjectDocument40 pagesReport On Mango Cultivation Projectkmilind007100% (1)
- 2 Mathematics For Social Science-1-1Document58 pages2 Mathematics For Social Science-1-1ሀበሻ EntertainmentNo ratings yet
- Arts NPSH TutorialDocument3 pagesArts NPSH TutorialDidier SanonNo ratings yet
- Segway v1 04 Eng Segway Atv Snarler Manual t3b L7eDocument192 pagesSegway v1 04 Eng Segway Atv Snarler Manual t3b L7eMarouane LASRYNo ratings yet
- Questionaire Abusive Supervision SurveyDocument2 pagesQuestionaire Abusive Supervision SurveyAabee SyedNo ratings yet
- RWB 60-856 Inst - Op. Mantto.Document52 pagesRWB 60-856 Inst - Op. Mantto.Daniel Dennis Escobar Subirana100% (1)
- Excavation and Trenching Implementation PlanDocument29 pagesExcavation and Trenching Implementation Planracing.phreakNo ratings yet
- The Big Table of Quantum AIDocument7 pagesThe Big Table of Quantum AIAbu Mohammad Omar Shehab Uddin AyubNo ratings yet
- PD 0018 Well Intervention Pressure Control Syllabus Level 3 4Document94 pagesPD 0018 Well Intervention Pressure Control Syllabus Level 3 4Salim AlgerianNo ratings yet
- 843-Artificial Intelligence-Xi XiiDocument11 pages843-Artificial Intelligence-Xi XiiPɾαƙԋყαƚ PαɳԃҽყNo ratings yet
- Diagram 1 Shows An AbacusDocument11 pagesDiagram 1 Shows An AbacusHema BalasubramaniamNo ratings yet
- Chapter 4 Calculations ANSWERSDocument2 pagesChapter 4 Calculations ANSWERSmollicksoham2907No ratings yet
- Op Amps and Linear Integrated Circuits 4th Edition by Gayakwad Ramakant A Textbook PDF Download PDFDocument1 pageOp Amps and Linear Integrated Circuits 4th Edition by Gayakwad Ramakant A Textbook PDF Download PDFNiraj KapoleNo ratings yet