You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- ARCH Sphere of InfluenceDocument1 pageARCH Sphere of InfluenceSebastian Garrett-SinghNo ratings yet
- Animations CssDocument5 pagesAnimations Cssreeder45960No ratings yet
- Code:: 01. Write A Program in C To Draw A Smiley FaceDocument7 pagesCode:: 01. Write A Program in C To Draw A Smiley FaceRaj VermaNo ratings yet
- ArcGis Manual 9.3Document113 pagesArcGis Manual 9.3Elias100% (1)
- CG ModelDocument3 pagesCG Modeldinesh vNo ratings yet
- تحديد الإقليم المدرك لمدينة الموصل باستخدام نظم المعلومات الجغرافية (gis)Document27 pagesتحديد الإقليم المدرك لمدينة الموصل باستخدام نظم المعلومات الجغرافية (gis)mahmoud abdelrahmanNo ratings yet
- The Blender Bros Game Asset Cheat SheetDocument2 pagesThe Blender Bros Game Asset Cheat SheetTommaso De VitoNo ratings yet
- The Interpreter S Resource PDFDocument3,065 pagesThe Interpreter S Resource PDFNazaGaleanoNo ratings yet
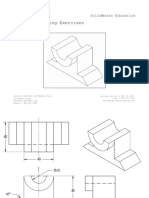
- Detailed Drawing Exercises: Solidworks EducationDocument51 pagesDetailed Drawing Exercises: Solidworks EducationLal Krrish MikeNo ratings yet
- Sub-Module 1.3 - Solid ModelingDocument30 pagesSub-Module 1.3 - Solid ModelingNeeraj GuptaNo ratings yet
- Quiz 4Document6 pagesQuiz 4Ba Thanh DinhNo ratings yet
- Fontana Septic System ParcelsDocument2 pagesFontana Septic System ParcelsSarah BatchaNo ratings yet
- Practical File Computer Graphics & Animation Lab RCA-551: Integrated Academy of Management and TechnologyDocument34 pagesPractical File Computer Graphics & Animation Lab RCA-551: Integrated Academy of Management and TechnologyVinay SharmaNo ratings yet
- StampDocument2 pagesStampbopufouriaNo ratings yet
- Multi-Scale 3D Gaussian Splatting For Anti-Aliased RenderingDocument16 pagesMulti-Scale 3D Gaussian Splatting For Anti-Aliased Renderingmarshe386No ratings yet
- Curves SamplesDocument5 pagesCurves Sampleskhalil alhatabNo ratings yet
- Optimization For UnityDocument20 pagesOptimization For UnityVenkat PoluNo ratings yet
- DIP Notes Unit 5Document30 pagesDIP Notes Unit 5boddumeghana2220No ratings yet
- 08 Clipping Cad CamDocument59 pages08 Clipping Cad CamAmit YadavNo ratings yet
- Nanite For Educators and Students 2 B01ced77f058Document21 pagesNanite For Educators and Students 2 B01ced77f058kunalkapoorawesomeNo ratings yet
- Shader Bits: Octahedral ImpostorsDocument15 pagesShader Bits: Octahedral ImpostorsDee .OdztaNo ratings yet
- ImageProcessing9 Segmentation (PointsLinesEdges)Document24 pagesImageProcessing9 Segmentation (PointsLinesEdges)Venkata Rao Nekkanti100% (1)
- Elefthera Logismika GIS GRASS QGISDocument143 pagesElefthera Logismika GIS GRASS QGISgzapasNo ratings yet
- Neajan 07Document8 pagesNeajan 07tsalapeiteinosNo ratings yet
- Anti-Aliased Line - Xiaolin Wu's Algorithm - GeeksforGeeks PDFDocument9 pagesAnti-Aliased Line - Xiaolin Wu's Algorithm - GeeksforGeeks PDFAhmedAlazzawiNo ratings yet
- PrefrebalDocument55 pagesPrefrebaljnkpatel561No ratings yet
- CG FileDocument41 pagesCG FileRavi RanjanNo ratings yet
- Assignments of CGDocument10 pagesAssignments of CGAshok MallNo ratings yet
- ClippingDocument30 pagesClippinggauravsaxenansitNo ratings yet
- A Study of Region-Based and Contourbased Image Seg PDFDocument8 pagesA Study of Region-Based and Contourbased Image Seg PDFShrikant TirkiNo ratings yet