You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Marathon Electric Generators 744RSL4054T60Document2 pagesMarathon Electric Generators 744RSL4054T60Carlos MartinezNo ratings yet
- vdr100g3 PDFDocument434 pagesvdr100g3 PDFredzwan100% (1)
- Manual Sensor A B Sense GuardDocument5 pagesManual Sensor A B Sense GuardMateus Rodolfo DiasNo ratings yet
- BiotrendDocument50 pagesBiotrendrobertNo ratings yet
- PowerMaxPlus Install Guide English DE5467IP3Document32 pagesPowerMaxPlus Install Guide English DE5467IP3Armando AriasNo ratings yet
- PW-1993-12 (Setting Up Your Workshop)Document96 pagesPW-1993-12 (Setting Up Your Workshop)KhalidNo ratings yet
- Ficha Técnica - Monitor de Signos Vitales - ePM Compact - ePM 10-12-15Document4 pagesFicha Técnica - Monitor de Signos Vitales - ePM Compact - ePM 10-12-15Angie Urrea VasquezNo ratings yet
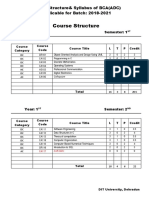
- BCA-Course Structure and Syllabus - Batch 2018 - ADCDocument91 pagesBCA-Course Structure and Syllabus - Batch 2018 - ADCNarendra KumarNo ratings yet
- L&T PresentationDocument124 pagesL&T Presentationrajib ranjan panda100% (1)
- ColorimetryDocument6 pagesColorimetryRaazia MirNo ratings yet
- NEPCO Visit Full ReportDocument17 pagesNEPCO Visit Full Reportsan20190158No ratings yet
- Laney Lg-35-r 30w Guitar Amplifier SchematicDocument3 pagesLaney Lg-35-r 30w Guitar Amplifier SchematicFrank Boz100% (1)
- CapacitorsDocument21 pagesCapacitorsNathan BerhanuNo ratings yet
- 00-GSCW-MASTER INDEX-Version 4.0Document6 pages00-GSCW-MASTER INDEX-Version 4.0MOHAMMED RAZINo ratings yet
- Demultiplexor 74HCT154Document8 pagesDemultiplexor 74HCT154castellano_1983No ratings yet
- What SF6 Gas TestingDocument4 pagesWhat SF6 Gas TestingAnonymous V1oLCBNo ratings yet
- Cicuit BreakerDocument2 pagesCicuit BreakerPankaj DhimanNo ratings yet
- How To Use This Competency-Based Learning MaterialDocument12 pagesHow To Use This Competency-Based Learning Materiallourdes estopaciaNo ratings yet
- Schneider-Relee de Timp PDFDocument28 pagesSchneider-Relee de Timp PDFChioibasNicolaeNo ratings yet
- As 60068.2.38-2003 Environmental Testing Tests - Test Z AD - Composite Temperature Humidity Cyclic TestDocument6 pagesAs 60068.2.38-2003 Environmental Testing Tests - Test Z AD - Composite Temperature Humidity Cyclic TestSAI Global - APAC0% (1)
- OckeybDocument72 pagesOckeybAnonymous 1Rb4QLr100% (1)
- Arduino Resource Guide PDFDocument110 pagesArduino Resource Guide PDFh_romeu_rs100% (2)
- Are Detonator Qualification and Lot Acceptance Test Requirements Rational?Document17 pagesAre Detonator Qualification and Lot Acceptance Test Requirements Rational?מוטי טננבוםNo ratings yet
- ITU-T K.70, Series K, Protection Against Interference, Human Exposure To EMF, 2007Document56 pagesITU-T K.70, Series K, Protection Against Interference, Human Exposure To EMF, 2007locusstandi84No ratings yet
- Architecture: Digital Signal Controller TMS320F2812Document16 pagesArchitecture: Digital Signal Controller TMS320F2812hiangcuongNo ratings yet
- Data Sheet 6EP4133-0GB00-0AY0: Charging Current Charging VoltageDocument3 pagesData Sheet 6EP4133-0GB00-0AY0: Charging Current Charging VoltageAndes PutraNo ratings yet
- India Vs China 2030Document11 pagesIndia Vs China 2030stifler joeNo ratings yet
- TermisthorDocument3 pagesTermisthorHadi Khajouee NejadNo ratings yet
- Toshiba 17mb22 Chassis 20w300p LD TV SMDocument137 pagesToshiba 17mb22 Chassis 20w300p LD TV SMCalin Adrian IepureNo ratings yet
- Nikon Picture Control System: Create Images Exactly As You Imagine ThemDocument13 pagesNikon Picture Control System: Create Images Exactly As You Imagine Themezlove14No ratings yet