You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- CV of Prof. D.C. PanigrahiDocument21 pagesCV of Prof. D.C. PanigrahiAbhishek MauryaNo ratings yet
- G.R. No. L-54171 October 28, 1980 JEWEL VILLACORTA, Assisted by Her Husband, GUERRERO VILLACORTA, COMPANY, Respondents. TEEHANKEE, Acting C.J.Document6 pagesG.R. No. L-54171 October 28, 1980 JEWEL VILLACORTA, Assisted by Her Husband, GUERRERO VILLACORTA, COMPANY, Respondents. TEEHANKEE, Acting C.J.Lyra Cecille Vertudes AllasNo ratings yet
- MockupDocument1 pageMockupJonathan Parra100% (1)
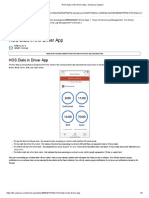
- HOS Dials in The Driver App - Samsara SupportDocument3 pagesHOS Dials in The Driver App - Samsara SupportMaryNo ratings yet
- Offer Letter - Kunal Saxena (Gurgaon)Document5 pagesOffer Letter - Kunal Saxena (Gurgaon)Neelesh PandeyNo ratings yet
- Spec 2 - Activity 08Document6 pagesSpec 2 - Activity 08AlvinTRectoNo ratings yet
- PH Measurement TechniqueDocument5 pagesPH Measurement TechniquevahidNo ratings yet
- Converted File d7206cc0Document15 pagesConverted File d7206cc0warzarwNo ratings yet
- E4PA OmronDocument8 pagesE4PA OmronCong NguyenNo ratings yet
- All India Corporate Photography Contest Promotes Workplace ArtDocument3 pagesAll India Corporate Photography Contest Promotes Workplace Artharish haridasNo ratings yet
- Maximum Yield USA 2013 December PDFDocument190 pagesMaximum Yield USA 2013 December PDFmushroomman88No ratings yet
- Accounts - User Guide: Release R15.000Document207 pagesAccounts - User Guide: Release R15.000lolitaferozNo ratings yet
- Depressurization LED Solar Charge Controller with Constant Current Source SR-DL100/SR-DL50Document4 pagesDepressurization LED Solar Charge Controller with Constant Current Source SR-DL100/SR-DL50Ria IndahNo ratings yet
- Term Paper Mec 208Document20 pagesTerm Paper Mec 208lksingh1987No ratings yet
- ZirakDocument4 pagesZiraktaibzirakchamkani81No ratings yet
- Railway Reservation System Er DiagramDocument4 pagesRailway Reservation System Er DiagramPenki Sarath67% (3)
- Questions For ReviewDocument2 pagesQuestions For ReviewJoemar JavierNo ratings yet
- (Unit) Title of The Chapter Name of FacilitatorDocument35 pages(Unit) Title of The Chapter Name of FacilitatorDipesh BasnetNo ratings yet
- Porsche Scheduled Maintenance Plan BrochureDocument2 pagesPorsche Scheduled Maintenance Plan BrochureDavid LusignanNo ratings yet
- Ubaf 1Document6 pagesUbaf 1ivecita27No ratings yet
- Comparing environmental impacts of clay and asbestos roof tilesDocument17 pagesComparing environmental impacts of clay and asbestos roof tilesGraham LongNo ratings yet
- Mercedes B-Class Accessories ListDocument34 pagesMercedes B-Class Accessories ListmuskystoatNo ratings yet
- InfosysDocument22 pagesInfosysTarun Singhal50% (2)
- Payment Solutions For Travel Platform: SabreDocument2 pagesPayment Solutions For Travel Platform: Sabrehell nahNo ratings yet
- CRM Chapter 3 Builds Customer RelationshipsDocument45 pagesCRM Chapter 3 Builds Customer RelationshipsPriya Datta100% (1)
- FTC470XETDocument2 pagesFTC470XETDecebal ScorilloNo ratings yet
- Ganbare Douki Chan MALDocument5 pagesGanbare Douki Chan MALShivam AgnihotriNo ratings yet
- FINAL Session 3 Specific GuidelinesDocument54 pagesFINAL Session 3 Specific GuidelinesBovelyn Autida-masingNo ratings yet
- Kj1010-6804-Man604-Man205 - Chapter 7Document16 pagesKj1010-6804-Man604-Man205 - Chapter 7ghalibNo ratings yet
- Real Estate Developer Resume SampleDocument1 pageReal Estate Developer Resume Sampleresume7.com100% (2)