You might also like
- Bases de Datos. Diseno y Gestion PDFDocument201 pagesBases de Datos. Diseno y Gestion PDFLeonardo Guzmán89% (9)
- Logaritmos XavierDocument4 pagesLogaritmos XavierXavier Huamani C.86% (7)
- Introduccion A La Lógica Difusa y Sus Aplicaciones. UADE. Guillermo Gabriel Fernandez AmadoDocument15 pagesIntroduccion A La Lógica Difusa y Sus Aplicaciones. UADE. Guillermo Gabriel Fernandez AmadoGuillermo Gabriel Fernández Amado100% (1)
- Foro de Clase - Tecnologias Emergentes Para...Document2 pagesForo de Clase - Tecnologias Emergentes Para...jose hernandez92% (25)
- Manual de Visual Basic IDocument11 pagesManual de Visual Basic IDavid MolinaNo ratings yet
- 07 Sistema de ColasDocument3 pages07 Sistema de ColasCarlos Eduardo Viera TimanaNo ratings yet
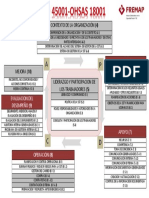
- Esquema Iso 45001 vs. Ohsas 18001Document1 pageEsquema Iso 45001 vs. Ohsas 18001Luis Ysaias Puma YabarNo ratings yet
- Maxicontrolador LCD PowerDocument21 pagesMaxicontrolador LCD PowerantonioNo ratings yet
- Scribd Hellen Sophia Gomez Beltran 704Document8 pagesScribd Hellen Sophia Gomez Beltran 704hellen gomezNo ratings yet
- Aspectos Tecnicos Xo PrimariaDocument4 pagesAspectos Tecnicos Xo PrimariaMaribel Yanque SalinasNo ratings yet
- F-20!00!01 Lista de Verificación e Informe de Validación y o Confirmación de Métodos NormalizadosDocument4 pagesF-20!00!01 Lista de Verificación e Informe de Validación y o Confirmación de Métodos NormalizadosCarlos TrianaNo ratings yet
- Práctica 2-Planteamiento de Problemas Reales en Optimización de Redes - Go For Life PDFDocument41 pagesPráctica 2-Planteamiento de Problemas Reales en Optimización de Redes - Go For Life PDFERICK HERNANDEZ REYESNo ratings yet
- 20180625090622Document104 pages20180625090622Eljaer CastilloNo ratings yet
- Ayuda en Google ChromeDocument27 pagesAyuda en Google ChromegabrielNo ratings yet
- Métodos Numéricos para El Calculo Científico Con Matlab - TOMO 1Document74 pagesMétodos Numéricos para El Calculo Científico Con Matlab - TOMO 1Junior Lino Mera CarrascoNo ratings yet
- Plan de Trabajo Instalacion de ServidorDocument17 pagesPlan de Trabajo Instalacion de ServidorRicardo Escobedo MartosNo ratings yet
- (Laboratorio de Optimizacion) HelpDocument126 pages(Laboratorio de Optimizacion) HelpEmilio GutierrezNo ratings yet
- Informe Levantamiento TopograficoDocument12 pagesInforme Levantamiento TopograficoJUNIOR FIGUEROANo ratings yet
- Curriculum Vitae 2017 PaulaDocument2 pagesCurriculum Vitae 2017 PaulaAndrea MartinezNo ratings yet
- LAB 13 - Planta PilotoDocument10 pagesLAB 13 - Planta PilotoMiguelito LeguiaNo ratings yet
- Hardware Comercial de Un Ordenador. Placas Base. Tarjetas Controladores de Dispositivos y de Entrada-SalidaDocument5 pagesHardware Comercial de Un Ordenador. Placas Base. Tarjetas Controladores de Dispositivos y de Entrada-SalidaEster GFNo ratings yet
- (Lab - 6) GuiaDocument16 pages(Lab - 6) GuiaNestor Daniel Gonzales ArévaloNo ratings yet
- Informe Topografico EaDocument8 pagesInforme Topografico EaJesus German MuguerzaNo ratings yet
- RDocument3 pagesRSolfeo Vsr AlfaNo ratings yet
- Representar Puntos en El Plano CartesianoDocument5 pagesRepresentar Puntos en El Plano CartesianoCeci M Paredes FernándezNo ratings yet
- Aireplay NG - Es AircrackDocument4 pagesAireplay NG - Es Aircrackzombira32No ratings yet
- Capítulo IV Power PointDocument27 pagesCapítulo IV Power PointJohnny Orrala AscencioNo ratings yet
- Metodo de Runge-KuttaDocument8 pagesMetodo de Runge-KuttaGianmarco Omar Guevara RodriguezNo ratings yet
- Sistemas Operativos: AutoejecutableDocument6 pagesSistemas Operativos: AutoejecutablezbernalNo ratings yet
- Almacenamiento en Las NubesDocument5 pagesAlmacenamiento en Las NubesZamara Andrea Linares RadaNo ratings yet