You might also like
- Long-Term Prediction of Time Series Using State-Space ModelsDocument11 pagesLong-Term Prediction of Time Series Using State-Space ModelsMurilo CamargosNo ratings yet
- Analyzing algorithms and their role in computer scienceDocument5 pagesAnalyzing algorithms and their role in computer scienceusmanaltafNo ratings yet
- An Improvement of Evolutionary ProgrammingDocument6 pagesAn Improvement of Evolutionary ProgrammingborlandspamNo ratings yet
- Planar Graph Isomorphism Is in Log SpaceDocument33 pagesPlanar Graph Isomorphism Is in Log Spacedddmadman001No ratings yet
- Parallel DPDocument35 pagesParallel DPapi-3756602No ratings yet
- Subex Linear ProgrammingDocument19 pagesSubex Linear ProgrammingkokoroNo ratings yet
- A Universal Dynamic Simulation Model of Gas Pipeline NetworksDocument10 pagesA Universal Dynamic Simulation Model of Gas Pipeline NetworksBakhytzhan AssilbekovNo ratings yet
- Computational Geometry Methods and Applications - ChenDocument227 pagesComputational Geometry Methods and Applications - ChenAlejandro JimenezNo ratings yet
- Finite Element MethodDocument37 pagesFinite Element Methodaditya2053No ratings yet
- AA0103C0102Document97 pagesAA0103C0102Jose Daniel Amador SalasNo ratings yet
- A Survey of Algorithms For The Single Machine Total Weighted Tardiness Scheduling ProblemDocument19 pagesA Survey of Algorithms For The Single Machine Total Weighted Tardiness Scheduling ProblemCuenta BasuraNo ratings yet
- Solving Difficult Multicommodity Problems With A Specialized Interior-Point AlgorithmDocument14 pagesSolving Difficult Multicommodity Problems With A Specialized Interior-Point AlgorithmnarendraNo ratings yet
- A Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesDocument12 pagesA Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesYaseen HussainNo ratings yet
- Ant System For Job-Shop Scheduling: Alberto Colorni Marco Dorigo Vittorio Maniezzo Marco TrubianDocument8 pagesAnt System For Job-Shop Scheduling: Alberto Colorni Marco Dorigo Vittorio Maniezzo Marco Trubianyuri_altusNo ratings yet
- Dray - Stochastic Methodologies - Adam+West - Michael+Keaton - Val+Kilmer - George+Clooney - Christian+BaleDocument5 pagesDray - Stochastic Methodologies - Adam+West - Michael+Keaton - Val+Kilmer - George+Clooney - Christian+Balefillipi_klosNo ratings yet
- A Methodology For The Emulation of The Turing MachineDocument5 pagesA Methodology For The Emulation of The Turing MachineEduardo CastrillónNo ratings yet
- Distributed Graph Isomorphism Using Quantum WalksDocument5 pagesDistributed Graph Isomorphism Using Quantum WalksEditor IJRITCCNo ratings yet
- Inversion of Noise-Free Laplace Transforms: Towards A Standardized Set of Test ProblemsDocument20 pagesInversion of Noise-Free Laplace Transforms: Towards A Standardized Set of Test ProblemsAhmad PooladiNo ratings yet
- Intelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsDocument19 pagesIntelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsChernet TugeNo ratings yet
- Comparison of Six Different Methods For Calculating TraveltimesDocument29 pagesComparison of Six Different Methods For Calculating TraveltimesNAGENDR_006No ratings yet
- Rational Approximation of The Absolute Value Function From Measurements: A Numerical Study of Recent MethodsDocument28 pagesRational Approximation of The Absolute Value Function From Measurements: A Numerical Study of Recent MethodsFlorinNo ratings yet
- Neural Network Learning For Analog VLSI Implementations of Support Vector Machines: A SurveyDocument19 pagesNeural Network Learning For Analog VLSI Implementations of Support Vector Machines: A SurveyPurohit Manish RNo ratings yet
- Temporal EvolutionDocument18 pagesTemporal EvolutionarchsarkNo ratings yet
- A Novel Numerical Algorithm Based On Galerkin-Petrov Time-Discretization Method For Solving Chaotic Nonlinear Dynamical SystemsDocument15 pagesA Novel Numerical Algorithm Based On Galerkin-Petrov Time-Discretization Method For Solving Chaotic Nonlinear Dynamical SystemsMuhammad Sabeel KhanNo ratings yet
- A Dynamic Topological Sort Algorithm For Directed Acyclic GraphsDocument24 pagesA Dynamic Topological Sort Algorithm For Directed Acyclic Graphsgallium.09.gleeNo ratings yet
- Linear-Time Dynamics Using Lagrange Multipliers: Robotics Institute Carnegie Mellon UniversityDocument10 pagesLinear-Time Dynamics Using Lagrange Multipliers: Robotics Institute Carnegie Mellon UniversityEMellaNo ratings yet
- Quantum Monte CarloDocument6 pagesQuantum Monte Carlomar.sedanoortNo ratings yet
- Hughes 1988 Space-Time FEM For Elastodynamics Formulations and Error EstimatesDocument25 pagesHughes 1988 Space-Time FEM For Elastodynamics Formulations and Error EstimatesKaustavChatterjeeNo ratings yet
- A Parallel DNA Algorithm Using A Micro Uidic Device To Build Scheduling GridsDocument10 pagesA Parallel DNA Algorithm Using A Micro Uidic Device To Build Scheduling GridsJames TerryNo ratings yet
- TR (Zak) : Xo+z,' Z + ZDocument5 pagesTR (Zak) : Xo+z,' Z + ZSara WigginsNo ratings yet
- METHODOLOGY FOR TREND ESTIMATION AND FILTERING NONSTATIONARY SEQUENCESDocument25 pagesMETHODOLOGY FOR TREND ESTIMATION AND FILTERING NONSTATIONARY SEQUENCESajax_telamonioNo ratings yet
- Multi-Swarm Pso Algorithm For The Quadratic Assignment Problem: A Massive Parallel Implementation On The Opencl PlatformDocument21 pagesMulti-Swarm Pso Algorithm For The Quadratic Assignment Problem: A Massive Parallel Implementation On The Opencl PlatformJustin WalkerNo ratings yet
- bf01589112 PDFDocument34 pagesbf01589112 PDFMichael ZhaoNo ratings yet
- Jordan18 Dynamical SymplecticDocument28 pagesJordan18 Dynamical Symplecticzhugc.univNo ratings yet
- An Exploration of ListsDocument8 pagesAn Exploration of Listsc_neagoeNo ratings yet
- Overview of Some Solved NP-complete Problems in Graph TheoryDocument11 pagesOverview of Some Solved NP-complete Problems in Graph TheoryAndika Dwi NugrahaNo ratings yet
- Inverse Optimal Control With Linearly-Solvable MDPsDocument8 pagesInverse Optimal Control With Linearly-Solvable MDPsAkustika HorozNo ratings yet
- Decoupling Suffix Trees-ProjectDocument4 pagesDecoupling Suffix Trees-ProjectScott Urueta SánchezNo ratings yet
- A Computational Model For Suspended Large Rigid Bodies in 3D Unsteady Viscous Flows XiaoDocument32 pagesA Computational Model For Suspended Large Rigid Bodies in 3D Unsteady Viscous Flows XiaowatersakanaNo ratings yet
- Finding The K Shortest Paths: David Eppstein March 31, 1997Document26 pagesFinding The K Shortest Paths: David Eppstein March 31, 1997Phạm Đức MinhNo ratings yet
- Fem WikipediaDocument11 pagesFem Wikipedialetter_ashish4444No ratings yet
- Scimakelatex 6806 Biblos Pok Vup Wenn GGGGGGDocument6 pagesScimakelatex 6806 Biblos Pok Vup Wenn GGGGGGAnnamaria LancianiNo ratings yet
- Optimal Brain Damage: 598 Le Cun, Denker and SollaDocument8 pagesOptimal Brain Damage: 598 Le Cun, Denker and Sollahugo pNo ratings yet
- Survey of Direct Transcription For Low-Thrust SpacDocument17 pagesSurvey of Direct Transcription For Low-Thrust SpacX YNo ratings yet
- Xpert: Computer Algebra For Metric Perturbation Theory: Pacs Numbers: 02.70.Wz, 02.40.ky, 04.25.NxDocument11 pagesXpert: Computer Algebra For Metric Perturbation Theory: Pacs Numbers: 02.70.Wz, 02.40.ky, 04.25.Nxseppi05No ratings yet
- Nonconvex Optimization For Communication SystemsDocument48 pagesNonconvex Optimization For Communication Systemsayush89No ratings yet
- Merge Sort: Divide and ConquerDocument18 pagesMerge Sort: Divide and ConquervinithNo ratings yet
- Multigrid methods for isogeometric discretizationDocument13 pagesMultigrid methods for isogeometric discretizationtomar_skNo ratings yet
- Vortices of Bat WingsDocument13 pagesVortices of Bat WingsThasarathan RavichandranNo ratings yet
- Matrix Completion From Power-Law Distributed Samples: Raghu Meka, Prateek Jain, and Inderjit S. DhillonDocument9 pagesMatrix Completion From Power-Law Distributed Samples: Raghu Meka, Prateek Jain, and Inderjit S. DhillonmachinelearnerNo ratings yet
- Predictive Control: For Linear and Hybrid SystemsDocument458 pagesPredictive Control: For Linear and Hybrid SystemsSanthosh KumarNo ratings yet
- Quantum Algorithm Design Techniques and ApplicationsDocument79 pagesQuantum Algorithm Design Techniques and ApplicationsAddy EmmanuelNo ratings yet
- 3programación Lineal 1 (2022)Document9 pages3programación Lineal 1 (2022)Daniel DazaNo ratings yet
- Experiments On The Minimum Linear Arrangement Problem: Jordi PetitDocument29 pagesExperiments On The Minimum Linear Arrangement Problem: Jordi PetitPhat LuongNo ratings yet
- Focs 2008 53Document10 pagesFocs 2008 53ErfanNo ratings yet
- Quantum ParallelismDocument7 pagesQuantum ParallelismSameer PujarNo ratings yet
- (Asi) Fausse Étude - scimakelatex.42159.Antoine+BoyetDocument6 pages(Asi) Fausse Étude - scimakelatex.42159.Antoine+BoyetAllen1306No ratings yet
- Texture Classification Using Logical Operators: Vidya Manian, Ramón Vásquez, Senior Member, IEEE, and Praveen KatiyarDocument11 pagesTexture Classification Using Logical Operators: Vidya Manian, Ramón Vásquez, Senior Member, IEEE, and Praveen KatiyarkesavansrNo ratings yet
- Tcs Employment Application Form: Basic DetailsDocument6 pagesTcs Employment Application Form: Basic DetailsRakesh Reddy GeetlaNo ratings yet
- Case Study Biomaterials Selection For A Joint ReplacementDocument8 pagesCase Study Biomaterials Selection For A Joint ReplacementBjarne Van haegenbergNo ratings yet
- How To Model A Square Foundation On PlaxisDocument4 pagesHow To Model A Square Foundation On Plaxisomarrashad84No ratings yet
- Commercial Law Study QuestionsDocument33 pagesCommercial Law Study QuestionsIfeanyi NdigweNo ratings yet
- User Manual FADALDocument583 pagesUser Manual FADALAntonio GonçalvesNo ratings yet
- Michael Haid Four Key HR Practices That Drive RetentionDocument6 pagesMichael Haid Four Key HR Practices That Drive RetentionBiswajit SikdarNo ratings yet
- Cultural Impacts of Tourism in VietnamDocument4 pagesCultural Impacts of Tourism in VietnamBùi Thanh Ngọc BíchNo ratings yet
- Applies To:: How To Disable Logging To The Sqlnet - Log and The Listener - Log (Doc ID 162675.1)Document2 pagesApplies To:: How To Disable Logging To The Sqlnet - Log and The Listener - Log (Doc ID 162675.1)Thiago Marangoni ZerbinatoNo ratings yet
- The Evolution of B2B Sales: Trends and TransformationsDocument14 pagesThe Evolution of B2B Sales: Trends and TransformationsSayed Faraz Ali ShahNo ratings yet
- GEMS Calender 2019-20Document2 pagesGEMS Calender 2019-20Rushiraj SinhNo ratings yet
- Pixar EssayDocument2 pagesPixar Essayapi-523887638No ratings yet
- Lecture 3 Geological ContactsDocument15 pagesLecture 3 Geological ContactsEhtisham JavedNo ratings yet
- BeamSmokeDetectors AppGuide BMAG240 PDFDocument8 pagesBeamSmokeDetectors AppGuide BMAG240 PDFMattu Saleen100% (1)
- Catalogo Medesy 2011Document133 pagesCatalogo Medesy 2011DentaDentNo ratings yet
- Social Engineering and IslamDocument8 pagesSocial Engineering and Islamaman_siddiqiNo ratings yet
- Financial Statement Analysis of HUL and Dabur India LtdDocument12 pagesFinancial Statement Analysis of HUL and Dabur India LtdEdwin D'SouzaNo ratings yet
- Official Secrets ActDocument3 pagesOfficial Secrets ActPrashant RohitNo ratings yet
- Naukri ANANDKUMARCHANDRAKANTPANDYAMCA (25y 0m)Document5 pagesNaukri ANANDKUMARCHANDRAKANTPANDYAMCA (25y 0m)Kewal DNo ratings yet
- (National Lampoon, April 1970 (Vol. 1 No. 1 - Sexy Cover Issue) ) Doug Kenney, Henry Beard and Robert Hoffman-National Lampoon Inc. (1970) PDFDocument90 pages(National Lampoon, April 1970 (Vol. 1 No. 1 - Sexy Cover Issue) ) Doug Kenney, Henry Beard and Robert Hoffman-National Lampoon Inc. (1970) PDFBruno Ferreira67% (6)
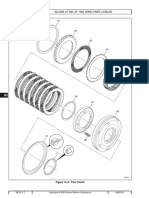
- Allison at 500, at 1500 Series Parts CatalogDocument3 pagesAllison at 500, at 1500 Series Parts Catalogamin chaabenNo ratings yet
- Interview Questions For PBDocument3 pagesInterview Questions For PBskrtripathiNo ratings yet
- NetSDK Programming Manual (Camera)Document93 pagesNetSDK Programming Manual (Camera)Bat-Erdene NasanbatNo ratings yet
- Introduction to ShipbuildingDocument7 pagesIntroduction to Shipbuildingmanoj narayananNo ratings yet
- Afl Fact SheetDocument1 pageAfl Fact Sheetapi-257609033No ratings yet
- Fri Chiks Marketing Mix and Swot AnalysisDocument22 pagesFri Chiks Marketing Mix and Swot Analysisahsanparveen100% (1)
- Tek Radius ManualDocument42 pagesTek Radius ManualjesusvpctNo ratings yet
- Cases On 9 (1) (A)Document2 pagesCases On 9 (1) (A)Dakshita Dubey100% (1)
- Celkon Mobiles - Wikipedia, The Free EncyclopediaDocument1 pageCelkon Mobiles - Wikipedia, The Free EncyclopediaJignesh ChaudharyNo ratings yet
- Increasing The Productivity of SaltDocument8 pagesIncreasing The Productivity of Salthenriel tambioNo ratings yet
- ISO 26262 for Functional Safety Critical ProjectsDocument24 pagesISO 26262 for Functional Safety Critical ProjectsZidane Benmansour100% (1)