You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Z-Transform Lecture NotesDocument24 pagesZ-Transform Lecture NotesGnanaraj100% (1)
- Aggregate Demand I: Building The IS-LM Model: Questions For ReviewDocument10 pagesAggregate Demand I: Building The IS-LM Model: Questions For ReviewErjon SkordhaNo ratings yet
- Embrace Your Issues: Compassing The Software Engineering Landscape Using Bug ReportsDocument4 pagesEmbrace Your Issues: Compassing The Software Engineering Landscape Using Bug ReportsMarkus BorgNo ratings yet
- Automated Bug Assignment: Ensemble-Based Machine Learning in Large Scale Industrial ContextsDocument52 pagesAutomated Bug Assignment: Ensemble-Based Machine Learning in Large Scale Industrial ContextsMarkus BorgNo ratings yet
- The More The Merrier: Leveraging On The Bug Inflow To Guide Software MaintenanceDocument1 pageThe More The Merrier: Leveraging On The Bug Inflow To Guide Software MaintenanceMarkus BorgNo ratings yet
- From Bugs To Decision Support - Leveraging Historical Issue Reports in Software EvolutionDocument350 pagesFrom Bugs To Decision Support - Leveraging Historical Issue Reports in Software EvolutionMarkus BorgNo ratings yet
- Navigating Information Overload Caused by Automated Testing - A Clustering Approach in Multi-Branch DevelopmentDocument9 pagesNavigating Information Overload Caused by Automated Testing - A Clustering Approach in Multi-Branch DevelopmentMarkus BorgNo ratings yet
- Comparing Cousins: A Harmonized Analysis of Racket Sport Set Scores Based On Racketlon World Tour ResultsDocument1 pageComparing Cousins: A Harmonized Analysis of Racket Sport Set Scores Based On Racketlon World Tour ResultsMarkus BorgNo ratings yet
- Recovering From A Decade: A Systematic Mapping of Information Retrieval Approaches To Software TraceabilityDocument54 pagesRecovering From A Decade: A Systematic Mapping of Information Retrieval Approaches To Software TraceabilityMarkus BorgNo ratings yet
- Development of Safety-Critical Software Systems Using Open Source Software - A Systematic MapDocument8 pagesDevelopment of Safety-Critical Software Systems Using Open Source Software - A Systematic MapMarkus BorgNo ratings yet
- Revisiting The Challenges in Aligning RE and V&V: Experiences From The Public SectorDocument8 pagesRevisiting The Challenges in Aligning RE and V&V: Experiences From The Public SectorMarkus BorgNo ratings yet
- IR in Software Traceability: From A Bird's Eye ViewDocument4 pagesIR in Software Traceability: From A Bird's Eye ViewMarkus BorgNo ratings yet
- Supporting Regression Test Scoping With Visual AnalyticsDocument10 pagesSupporting Regression Test Scoping With Visual AnalyticsMarkus BorgNo ratings yet
- Presentation: Research Direction, Traceability and Findability in Software EngineeringDocument28 pagesPresentation: Research Direction, Traceability and Findability in Software EngineeringMarkus BorgNo ratings yet
- A Replicated Study On Duplicate Detection: Using Apache Lucene To Search Among Android DefectsDocument4 pagesA Replicated Study On Duplicate Detection: Using Apache Lucene To Search Among Android DefectsMarkus BorgNo ratings yet
- Challenges and Practices in Aligning Requirements With Verification and Validation: A Case Study of Six CompaniesDocument49 pagesChallenges and Practices in Aligning Requirements With Verification and Validation: A Case Study of Six CompaniesMarkus BorgNo ratings yet
- Conflict Management in Student Groups - A Teacher's Perspective in Higher EducationDocument14 pagesConflict Management in Student Groups - A Teacher's Perspective in Higher EducationMarkus BorgNo ratings yet
- Analyzing Networks of Issue ReportsDocument10 pagesAnalyzing Networks of Issue ReportsMarkus BorgNo ratings yet
- Advancing Trace Recovery Evaluation - Applied Information Retrieval in A Software Engineering ContextDocument185 pagesAdvancing Trace Recovery Evaluation - Applied Information Retrieval in A Software Engineering ContextMarkus BorgNo ratings yet
- Evaluation of Traceability Recovery in Context: A Taxonomy For Information Retrieval ToolsDocument10 pagesEvaluation of Traceability Recovery in Context: A Taxonomy For Information Retrieval ToolsMarkus BorgNo ratings yet
- Findability Through Traceability - A Realistic Application of Candidate Trace Links?Document10 pagesFindability Through Traceability - A Realistic Application of Candidate Trace Links?Markus BorgNo ratings yet
- Towards Scalable Information Modeling of Requirements ArchitecturesDocument10 pagesTowards Scalable Information Modeling of Requirements ArchitecturesMarkus BorgNo ratings yet
- Presentation: Time-Extraction From Real-Time Generated Football ReportsDocument29 pagesPresentation: Time-Extraction From Real-Time Generated Football ReportsMarkus BorgNo ratings yet
- IR-based Traceability Recovery As A Plugin - An Industrial Case StudyDocument3 pagesIR-based Traceability Recovery As A Plugin - An Industrial Case StudyMarkus BorgNo ratings yet
- In Vivo Evaluation of Large-Scale Traceability RecoveryDocument4 pagesIn Vivo Evaluation of Large-Scale Traceability RecoveryMarkus BorgNo ratings yet
- Industrial Comparability of Student Artifacts in Traceability Recovery Research - An Exploratory SurveyDocument10 pagesIndustrial Comparability of Student Artifacts in Traceability Recovery Research - An Exploratory SurveyMarkus BorgNo ratings yet
- Information Retrieval-Based Traceability Recovery in ContextDocument1 pageInformation Retrieval-Based Traceability Recovery in ContextMarkus BorgNo ratings yet
- Time-Extraction From Real-Time Generated Football ReportsDocument7 pagesTime-Extraction From Real-Time Generated Football ReportsMarkus BorgNo ratings yet
- Poster: Traceability Recovery As A Plugin - An Industrial Case StudyDocument1 pagePoster: Traceability Recovery As A Plugin - An Industrial Case StudyMarkus BorgNo ratings yet
- Safe Programming Languages For ABB Automation System 800xaDocument58 pagesSafe Programming Languages For ABB Automation System 800xaMarkus Borg100% (1)
- Triangulation: StatementDocument3 pagesTriangulation: StatementИлија Хаџи-Пурић V-4No ratings yet
- 18ecc204j - DSP - Week 1Document57 pages18ecc204j - DSP - Week 1Ankur JhaNo ratings yet
- Digital SAT Tests MATH Explanation (Mr. Amr Mustafa)Document196 pagesDigital SAT Tests MATH Explanation (Mr. Amr Mustafa)mr.samirjon.07No ratings yet
- Skip Lists: A Probabilistic Alternative To Balanced TreesDocument9 pagesSkip Lists: A Probabilistic Alternative To Balanced TreeshendersonNo ratings yet
- CED 426 Quiz # 2 SolutionsDocument26 pagesCED 426 Quiz # 2 SolutionsMary Joanne AninonNo ratings yet
- The Backscattering of Gamma Radiation From Plane Concrete WallsDocument22 pagesThe Backscattering of Gamma Radiation From Plane Concrete WallsHatim ElNo ratings yet
- 01 Thermal ExpansionDocument9 pages01 Thermal ExpansionCelphy TrimuchaNo ratings yet
- Retinal Problems and Its Analysis Using Image Processing A ReviewDocument6 pagesRetinal Problems and Its Analysis Using Image Processing A ReviewSandeep MendhuleNo ratings yet
- 09 Energy&Aeronautics&AuronauticsDocument211 pages09 Energy&Aeronautics&AuronauticsDorisman Feriandi SimorangkirNo ratings yet
- NEET-1 PHYSICS - PMD PDFDocument11 pagesNEET-1 PHYSICS - PMD PDFRameshbabu GellepoguNo ratings yet
- B.Tech. (5 Semester Mechanical) TRIBOLOGY (MEPE-17)Document5 pagesB.Tech. (5 Semester Mechanical) TRIBOLOGY (MEPE-17)varunNo ratings yet
- MGT 6203 - Sri - M5 - Treatment Effects v042919Document21 pagesMGT 6203 - Sri - M5 - Treatment Effects v042919lexleong9610No ratings yet
- HypotestDocument14 pagesHypotestMadhukar SamathamNo ratings yet
- Mikroniek 2010 2 1Document7 pagesMikroniek 2010 2 1Vipin YadavNo ratings yet
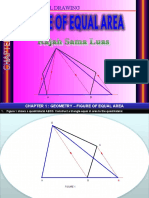
- Engineering Drawing Form 4 - Figure of Equal AreaDocument13 pagesEngineering Drawing Form 4 - Figure of Equal AreaDo The CuongNo ratings yet
- Polynomial Problems From Recent Iranian Mathematical OlympiadsDocument15 pagesPolynomial Problems From Recent Iranian Mathematical OlympiadsaayamNo ratings yet
- 32 2H Nov 2021 QPDocument28 pages32 2H Nov 2021 QPXoticMemes okNo ratings yet
- Written Report ProbabilityDocument8 pagesWritten Report ProbabilitySherl Escandor100% (1)
- Steady State and Generalized State Space Averaging Analysis of TheDocument6 pagesSteady State and Generalized State Space Averaging Analysis of TheTedNo ratings yet
- DBS1012Chapter 2 Linear MotionDocument10 pagesDBS1012Chapter 2 Linear MotionSyarul Rix SyameerNo ratings yet
- Dwnload Full Introduction To Finite Elements in Engineering 4th Edition Chandrupatla Solutions Manual PDFDocument12 pagesDwnload Full Introduction To Finite Elements in Engineering 4th Edition Chandrupatla Solutions Manual PDFgilmadelaurentis100% (13)
- ch-12 Herons FormulaDocument2 pagesch-12 Herons Formulaapi-286106888No ratings yet
- Technical PlacementDocument50 pagesTechnical PlacementSaumya SinghNo ratings yet
- PDE Multivariable FuncDocument16 pagesPDE Multivariable Funcsaipavan iitpNo ratings yet
- Generalized FunctionsDocument56 pagesGeneralized Functionsm-rasheedNo ratings yet
- Essbase MDXDocument23 pagesEssbase MDXapi-26942036No ratings yet
- Math 7 and 8 Performance TaskDocument3 pagesMath 7 and 8 Performance Taskapi-401010000No ratings yet
- Advanced Composite Engineering Using MSC - Patran and FibersimDocument15 pagesAdvanced Composite Engineering Using MSC - Patran and FibersimSandeep BandyopadhyayNo ratings yet