You might also like
- Ladder Logic Examples and PLC Programming ExamplesDocument6 pagesLadder Logic Examples and PLC Programming ExamplesKimberly CarreonNo ratings yet
- Introduction To Stochastic ElectrodynamicsDocument518 pagesIntroduction To Stochastic ElectrodynamicsEdvaart100% (2)
- Pcu BackupDocument88 pagesPcu BackupD37667No ratings yet
- XNA Isometric Games by Martin ActorDocument13 pagesXNA Isometric Games by Martin ActorGilberto Vecchi MacedoNo ratings yet
- Accessing Files and DirectoriesDocument27 pagesAccessing Files and Directoriesraymart_omampoNo ratings yet
- Coleman WeinbergDocument23 pagesColeman WeinbergKostas Roubedakis100% (1)
- Higgs BundlesDocument125 pagesHiggs BundlesIsmail KhanNo ratings yet
- Emilio Elizalde - Cosmological Casimir Effect and BeyondDocument139 pagesEmilio Elizalde - Cosmological Casimir Effect and BeyondJuazmantNo ratings yet
- The Casimir Effect: Joseph CugnonDocument18 pagesThe Casimir Effect: Joseph CugnonMuhammad Salah100% (1)
- New Relativistic Paradoxes and Open QuestionsDocument128 pagesNew Relativistic Paradoxes and Open QuestionsFlorentin SmarandacheNo ratings yet
- Noether's TheoremDocument12 pagesNoether's TheoremFernando Vidal OlmosNo ratings yet
- On The History of Geometrization From Minkowski To Finsler Geometry H Goenner - PsDocument24 pagesOn The History of Geometrization From Minkowski To Finsler Geometry H Goenner - PsEstácio NetoNo ratings yet
- Penrose 1967Document23 pagesPenrose 1967Jack Ignacio Nahmías100% (1)
- Jacobian Elliptic Functions and Theta FunctionsDocument15 pagesJacobian Elliptic Functions and Theta FunctionsAlexandra Nicoleta Teisi100% (1)
- Introduction To The AdSCFT CorrespondenceDocument64 pagesIntroduction To The AdSCFT CorrespondencelunarcausticacNo ratings yet
- Topological Quantum Field Theory - WikipediaDocument49 pagesTopological Quantum Field Theory - WikipediaBxjdduNo ratings yet
- Feynman Path Integral MethodsDocument62 pagesFeynman Path Integral MethodstrevorscheopnerNo ratings yet
- Lecture Notes QFT Temp 3Document77 pagesLecture Notes QFT Temp 3Otter EatsmenNo ratings yet
- Octonionic Gravity, Grand-Unification and Modified Dispersion RelationsDocument23 pagesOctonionic Gravity, Grand-Unification and Modified Dispersion RelationsKathryn Wilson100% (1)
- Problems in Quantum MechanicsDocument18 pagesProblems in Quantum MechanicsShivnag SistaNo ratings yet
- Gregory W. Moore - Physical Mathematics and The FutureDocument69 pagesGregory W. Moore - Physical Mathematics and The FuturePedro Figueroa100% (1)
- Hamiltonian Mechanics: 4.1 Hamilton's EquationsDocument9 pagesHamiltonian Mechanics: 4.1 Hamilton's EquationsRyan TraversNo ratings yet
- Itzhak Bars and Bora Orcal - Generalized Twistor Transform and Dualities With A New Description of Particles With Spin Beyond Free and MasslessDocument33 pagesItzhak Bars and Bora Orcal - Generalized Twistor Transform and Dualities With A New Description of Particles With Spin Beyond Free and MasslessGum0000100% (1)
- Random MatricesDocument27 pagesRandom MatricesolenobleNo ratings yet
- A Simple Derivation of The Lorentz TransformationDocument4 pagesA Simple Derivation of The Lorentz TransformationMatthew AustinNo ratings yet
- Vectors, Spinors, and Complex Numbers in Classical and Quantum Physics David HestenesDocument23 pagesVectors, Spinors, and Complex Numbers in Classical and Quantum Physics David Hestenesosegeno654321100% (1)
- S191129u PDFDocument9 pagesS191129u PDFASHINI MODINo ratings yet
- 300 Problems in Special and General RelativityDocument10 pages300 Problems in Special and General RelativityGilberto JarvioNo ratings yet
- On The Emergence of Spacetime and Matter From Model SetsDocument21 pagesOn The Emergence of Spacetime and Matter From Model SetsQuantum Gravity Research100% (1)
- An Introduction To Geometric Algebra With Some PreDocument16 pagesAn Introduction To Geometric Algebra With Some PreYoussef YousryNo ratings yet
- Dana C. Ernst-Visual Group Theory (Class Notes) (2009)Document214 pagesDana C. Ernst-Visual Group Theory (Class Notes) (2009)acphyNo ratings yet
- Rigid Bodies: 2.1 Many-Body SystemsDocument17 pagesRigid Bodies: 2.1 Many-Body SystemsRyan TraversNo ratings yet
- New Lectures GRDocument938 pagesNew Lectures GR한상현No ratings yet
- Algebra of Complex Vectors and Applicati PDFDocument62 pagesAlgebra of Complex Vectors and Applicati PDFGabor PeterNo ratings yet
- From Apollonius To Zaremba: Local-Global Phenomena in Thin OrbitsDocument42 pagesFrom Apollonius To Zaremba: Local-Global Phenomena in Thin OrbitsLuis Alberto FuentesNo ratings yet
- Supersymmetry: Herbi K. Dreiner Howard E. Haber Stephen P. Martin September 22, 2004Document272 pagesSupersymmetry: Herbi K. Dreiner Howard E. Haber Stephen P. Martin September 22, 2004Sushant Goel100% (1)
- Atiyah Bott Shapiro Clifford ModulesDocument36 pagesAtiyah Bott Shapiro Clifford Modulespurple_vase100% (1)
- Dynamical Systems: 5.1 Phase PortraitsDocument36 pagesDynamical Systems: 5.1 Phase PortraitsRyan TraversNo ratings yet
- Relativistic Electromagnetism: 6.1 Four-VectorsDocument15 pagesRelativistic Electromagnetism: 6.1 Four-VectorsRyan TraversNo ratings yet
- Scale Relativity and Fractal Space-Time: Applications To Quantum Physics, Cosmology and Chaotic SystemsDocument62 pagesScale Relativity and Fractal Space-Time: Applications To Quantum Physics, Cosmology and Chaotic Systemsxxx_man_1974No ratings yet
- Feyn CalcDocument6 pagesFeyn CalcJonatan Vignatti MuñozNo ratings yet
- E The Master of AllDocument12 pagesE The Master of AllchungNo ratings yet
- An Introduction To Twistors - Paul BairdDocument15 pagesAn Introduction To Twistors - Paul BairdStanislas Petit100% (2)
- Schwarzschild and Kerr Solutions of Einsteins Field Equation PDFDocument96 pagesSchwarzschild and Kerr Solutions of Einsteins Field Equation PDFJairo E Márquez DNo ratings yet
- Quantum Theory of Light DiffractionDocument11 pagesQuantum Theory of Light DiffractionDevvvNo ratings yet
- Helgason - Sophus Lie, The MathematicianDocument19 pagesHelgason - Sophus Lie, The MathematicianZow Niak100% (1)
- Tight BindingDocument5 pagesTight BindingalkeroneNo ratings yet
- Ergodic Theory Number TheoryDocument104 pagesErgodic Theory Number TheoryRenato CastilhoNo ratings yet
- Physical MathematicsDocument2 pagesPhysical MathematicsPatricioNo ratings yet
- Statistical Physics Part IIDocument39 pagesStatistical Physics Part IIfrankythebroNo ratings yet
- Click Here For Download: (PDF) Mercury's Perihelion From Le Verrier To Einstein (Oxford Science Publications)Document2 pagesClick Here For Download: (PDF) Mercury's Perihelion From Le Verrier To Einstein (Oxford Science Publications)Yanh VissuetNo ratings yet
- History of Quantum MechanicsDocument112 pagesHistory of Quantum MechanicsGeorgeHerrera100% (1)
- Chapter2 PDFDocument159 pagesChapter2 PDFShishir DasikaNo ratings yet
- Boris Khesin - Topological Fluid DynamicsDocument11 pagesBoris Khesin - Topological Fluid DynamicsPlamcfeNo ratings yet
- Lagrangian Mechanics: 3.1 Action PrincipleDocument15 pagesLagrangian Mechanics: 3.1 Action PrincipleRyan TraversNo ratings yet
- Quantum Mechanics - Taylor PDFDocument7 pagesQuantum Mechanics - Taylor PDFmladenNo ratings yet
- Types of Integral EquationsDocument5 pagesTypes of Integral EquationsIL Kook SongNo ratings yet
- Winitzki - Solutions To Mukhanov's Course of General Relativity 2006 With Problem SettingsDocument48 pagesWinitzki - Solutions To Mukhanov's Course of General Relativity 2006 With Problem SettingswinitzkiNo ratings yet
- JMathPhys 31 725 (Lee and Wald)Document19 pagesJMathPhys 31 725 (Lee and Wald)Juan PerezNo ratings yet
- Lorentz TransformationDocument27 pagesLorentz TransformationBrenda Michelle ReyesNo ratings yet
- 40 - The Quantized Electromagnetic Field PDFDocument21 pages40 - The Quantized Electromagnetic Field PDFUltrazordNo ratings yet
- Group Theoretical Methods in PhysicsFrom EverandGroup Theoretical Methods in PhysicsRobert SharNo ratings yet
- Yves Lafont - From Proof-Nets To Interaction NetsDocument21 pagesYves Lafont - From Proof-Nets To Interaction Netsdcsi3No ratings yet
- Andre Hirschowitz and Michel Hirschowitz - Towards A Notion of Truth For Linear LogicDocument13 pagesAndre Hirschowitz and Michel Hirschowitz - Towards A Notion of Truth For Linear Logicdcsi3No ratings yet
- Jacob D. Biamonte, Stephen R. Clark and Dieter Jaksch-Categorical Tensor Network StatesDocument31 pagesJacob D. Biamonte, Stephen R. Clark and Dieter Jaksch-Categorical Tensor Network Statesdcsi3No ratings yet
- Samson Abramsky and Bob Coecke - A Categorical Semantics of Quantum ProtocolsDocument21 pagesSamson Abramsky and Bob Coecke - A Categorical Semantics of Quantum Protocolsdcsi3No ratings yet
- William Edwards - Non-Locality in Categorical Quantum MechanicsDocument139 pagesWilliam Edwards - Non-Locality in Categorical Quantum Mechanicsdcsi3100% (1)
- Samson Abramsky and Nikos Tzevelekos - Introduction To Categories and Categorical LogicDocument101 pagesSamson Abramsky and Nikos Tzevelekos - Introduction To Categories and Categorical Logicdcsi3No ratings yet
- Bob Coecke - Quantum Information-Flow, Concretely, and AxiomaticallyDocument15 pagesBob Coecke - Quantum Information-Flow, Concretely, and Axiomaticallydcsi3No ratings yet
- Ingo Runkel - Algebra in Braided Tensor Categories and Conformal Field TheoryDocument69 pagesIngo Runkel - Algebra in Braided Tensor Categories and Conformal Field Theorydcsi3No ratings yet
- Samuel J. Lomonaco and Louis H. Kauffman - Quantum Knots and MosaicsDocument32 pagesSamuel J. Lomonaco and Louis H. Kauffman - Quantum Knots and Mosaicsdcsi3No ratings yet
- The Definition of A Planar AlgebraDocument58 pagesThe Definition of A Planar Algebradcsi3No ratings yet
- Richard Han - A Construction of The "2221" Planar AlgebraDocument190 pagesRichard Han - A Construction of The "2221" Planar Algebradcsi3No ratings yet
- Emily Peters - Constructing The Extended Haagerup Planar AlgebraDocument26 pagesEmily Peters - Constructing The Extended Haagerup Planar Algebradcsi3No ratings yet
- Jurgen Fuchs - The Graphical Calculus For Ribbon Categories: Algebras, Modules, Nakayama AutomorphismsDocument11 pagesJurgen Fuchs - The Graphical Calculus For Ribbon Categories: Algebras, Modules, Nakayama Automorphismsdcsi3No ratings yet
- V. F. R. Jones - Planar Algebras, IDocument122 pagesV. F. R. Jones - Planar Algebras, Idcsi3No ratings yet
- Vijay Kodiyalam and V.S. Sunder - On Jones' Planar AlgebrasDocument30 pagesVijay Kodiyalam and V.S. Sunder - On Jones' Planar Algebrasdcsi3No ratings yet
- Bob Coecke and Eric Oliver Paquette - Categories For The Practising PhysicistDocument105 pagesBob Coecke and Eric Oliver Paquette - Categories For The Practising Physicistdcsi3No ratings yet
- Jurg Frohlich, Jurgen Fuchs, Ingo Runkel and Christoph Schweigert - Correspondance of Ribbon CategoriesDocument129 pagesJurg Frohlich, Jurgen Fuchs, Ingo Runkel and Christoph Schweigert - Correspondance of Ribbon Categoriesdcsi3No ratings yet
- John C. Baez - Quantum Quandaries: A Category-Theoretic PerspectiveDocument21 pagesJohn C. Baez - Quantum Quandaries: A Category-Theoretic Perspectivedcsi3No ratings yet
- Bob Coecke and Ross Duncan - Interacting Quantum ObservablesDocument13 pagesBob Coecke and Ross Duncan - Interacting Quantum Observablesdcsi3No ratings yet
- Louis H. Kauffman - Spin Networks and The Bracket PolynomialDocument18 pagesLouis H. Kauffman - Spin Networks and The Bracket Polynomialdcsi3No ratings yet
- John C. Baez and Aaeon Lauda - A Prehistory of N-Categorical PhysicsDocument58 pagesJohn C. Baez and Aaeon Lauda - A Prehistory of N-Categorical Physicsdcsi3No ratings yet
- Spencer D. Stirling and Yong-Shi Wu - Braided Categorical Quantum Mechanics IDocument78 pagesSpencer D. Stirling and Yong-Shi Wu - Braided Categorical Quantum Mechanics Idcsi3No ratings yet
- Jeffrey C. Morton - Groupoidification in PhysicsDocument23 pagesJeffrey C. Morton - Groupoidification in Physicsdcsi3No ratings yet
- Jacob Biamonte - Quantum Versus Classical Network Structure and FunctionDocument65 pagesJacob Biamonte - Quantum Versus Classical Network Structure and Functiondcsi3No ratings yet
- Roger Penrose - Applications of Negative Dimensional TensorsDocument24 pagesRoger Penrose - Applications of Negative Dimensional Tensorsdcsi3No ratings yet
- Jacob Biamonte - Categorical Models of Quantum CircuitsDocument9 pagesJacob Biamonte - Categorical Models of Quantum Circuitsdcsi3No ratings yet
- Bob Coecke - Kindergarten Quantum MechanicsDocument69 pagesBob Coecke - Kindergarten Quantum Mechanicsdcsi3No ratings yet
- Ville Bergholm and Jacob D. Biamonte - Categorical Quantum CircuitsDocument1 pageVille Bergholm and Jacob D. Biamonte - Categorical Quantum Circuitsdcsi3No ratings yet
- Ville Bergholm and Jacob D. Biamonte - Categorical Quantum CircuitsDocument23 pagesVille Bergholm and Jacob D. Biamonte - Categorical Quantum Circuitsdcsi3No ratings yet
- Bob Coecke - Quantum PicturalismDocument107 pagesBob Coecke - Quantum Picturalismdcsi3100% (1)
- What Is A GC Buffer Busy WaitDocument2 pagesWhat Is A GC Buffer Busy Waitmrstranger1981No ratings yet
- Exam Questions 2018Document3 pagesExam Questions 2018naveen g cNo ratings yet
- Unit Rates With FractionsDocument4 pagesUnit Rates With FractionsMr. PetersonNo ratings yet
- Figure 1: Dream/Phil-Lidar 1 Logos. Images Courtesy of Dream/Phil-Lidar 1 ProgramDocument15 pagesFigure 1: Dream/Phil-Lidar 1 Logos. Images Courtesy of Dream/Phil-Lidar 1 ProgramMarck RiveraNo ratings yet
- List of Unsolved Problems in Computer ScienceDocument3 pagesList of Unsolved Problems in Computer ScienceRaghav SingalNo ratings yet
- Vmware Diskmount Utility: User'S ManualDocument6 pagesVmware Diskmount Utility: User'S ManualXavier AthimonNo ratings yet
- Algorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptDocument7 pagesAlgorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptMaria ClaraNo ratings yet
- 9788131526361Document1 page9788131526361Rashmi AnandNo ratings yet
- Studocu Is Not Sponsored or Endorsed by Any College or UniversityDocument51 pagesStudocu Is Not Sponsored or Endorsed by Any College or UniversityDK SHARMANo ratings yet
- Project Report On "Online Tour and Travel Agency"Document8 pagesProject Report On "Online Tour and Travel Agency"Hitesh MendirattaNo ratings yet
- Vodafone IntroductionDocument10 pagesVodafone IntroductionVishal JainNo ratings yet
- Pre-Paid Energy Meter PDFDocument84 pagesPre-Paid Energy Meter PDFRobert AlexanderNo ratings yet
- Installation GuideDocument497 pagesInstallation GuidemaheshumbarkarNo ratings yet
- Arduino TCS230 Color Recognition Sensor ModuleDocument6 pagesArduino TCS230 Color Recognition Sensor ModulecuervocrowNo ratings yet
- Water Jug & MissionariesDocument52 pagesWater Jug & MissionariesAdmire ChaniwaNo ratings yet
- Chapter 1 OJTDocument11 pagesChapter 1 OJTVilla LopezNo ratings yet
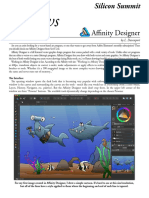
- Affinity DesignerDocument4 pagesAffinity DesignerManu7750% (2)
- Name: Jayson P. Manuales Section: EC 1-2 Subject/Schedule: Object Oriented Programming/ MW 4:00 - 7:00 PM I. Problem With SolutionDocument10 pagesName: Jayson P. Manuales Section: EC 1-2 Subject/Schedule: Object Oriented Programming/ MW 4:00 - 7:00 PM I. Problem With SolutionBrael Christian Rulona SuarezNo ratings yet
- Indian Railways Complaints & Suggestions: Complaint Reference Number: PNR Details: Complaint Reported byDocument1 pageIndian Railways Complaints & Suggestions: Complaint Reference Number: PNR Details: Complaint Reported byIbrahim KhaleelullahNo ratings yet
- MCQDocument38 pagesMCQPrakul PalNo ratings yet
- 37 Tips and Tricks Using HD2Document4 pages37 Tips and Tricks Using HD2Nafisa MeisaNo ratings yet
- DBGDocument64 pagesDBGAnand KNo ratings yet
- Difference Between Quality Assurance and Quality Control (With Comparison Chart) - Key DifferencesDocument5 pagesDifference Between Quality Assurance and Quality Control (With Comparison Chart) - Key Differencescenkj100% (1)
- matNMR 3 9 0Document90 pagesmatNMR 3 9 0theoneandonly1No ratings yet
- reading-and-reflecting-on-texts-file-by-www.pupilstutor.comDocument81 pagesreading-and-reflecting-on-texts-file-by-www.pupilstutor.comAnkit BhanotNo ratings yet
- MCQ Book PDFDocument104 pagesMCQ Book PDFGoldi SinghNo ratings yet