You might also like
- Does National Culture Influence Consumers' Evaluation of Travel Services? A Test of Hofstede's Model of Cross-Cultural DifferencesDocument10 pagesDoes National Culture Influence Consumers' Evaluation of Travel Services? A Test of Hofstede's Model of Cross-Cultural DifferencesEsther Charlotte WilliamsNo ratings yet
- Gender DifferencesDocument11 pagesGender DifferencesEsther Charlotte WilliamsNo ratings yet
- A Cross-Cultural Comparison of Travel Push and Pull FactorsDocument28 pagesA Cross-Cultural Comparison of Travel Push and Pull FactorsEsther Charlotte WilliamsNo ratings yet
- Culture GoldDocument12 pagesCulture GoldEsther Charlotte WilliamsNo ratings yet
- Cultural Differences in Travel Risk PerceptionDocument20 pagesCultural Differences in Travel Risk PerceptionEsther Charlotte Williams100% (2)
- A Longitudinal Field Investigation of Gender DifDocument28 pagesA Longitudinal Field Investigation of Gender DifEsther Charlotte WilliamsNo ratings yet
- Travel Making - From The Vantage Point of Perceived Risk and Information PreferencesDocument17 pagesTravel Making - From The Vantage Point of Perceived Risk and Information PreferencesEsther Charlotte WilliamsNo ratings yet
- Exploring Word-Of-mouth Influences On Travel Decisions Friends and Relatives vs. Other TravellersDocument11 pagesExploring Word-Of-mouth Influences On Travel Decisions Friends and Relatives vs. Other TravellersEsther Charlotte WilliamsNo ratings yet
- GJHGJDocument70 pagesGJHGJRaveen Prashanth SivanandamNo ratings yet
- Multi-Faceted Tourist Travel Decisions - A Constraint-Based Conceptual Framework To Describe Tourists' Sequential Choices of Travel ComponentsDocument8 pagesMulti-Faceted Tourist Travel Decisions - A Constraint-Based Conceptual Framework To Describe Tourists' Sequential Choices of Travel ComponentsEsther Charlotte WilliamsNo ratings yet
- Ganging Up of Info OverloadDocument3 pagesGanging Up of Info OverloadEsther Charlotte WilliamsNo ratings yet
- We Have The Information You Want But Getting It Will Cost YouDocument11 pagesWe Have The Information You Want But Getting It Will Cost YouEsther Charlotte WilliamsNo ratings yet
- Building and Testing Theories of Decision Making by TravellersDocument18 pagesBuilding and Testing Theories of Decision Making by TravellersEsther Charlotte WilliamsNo ratings yet
- User-Generated Content and Travel A Case Study On Trip AdvisorDocument12 pagesUser-Generated Content and Travel A Case Study On Trip AdvisorEsther Charlotte Williams100% (1)
- Travel Tweets Trends WhitepaperDocument42 pagesTravel Tweets Trends WhitepaperEsther Charlotte WilliamsNo ratings yet
- BbuttleDocument14 pagesBbuttleChayma BouaoiinaNo ratings yet
- Collecting Social Network Data To Study Social Activity-Travel Behavior An Egocentric ApproachDocument21 pagesCollecting Social Network Data To Study Social Activity-Travel Behavior An Egocentric ApproachEsther Charlotte WilliamsNo ratings yet
- Psycology of BloggingDocument10 pagesPsycology of BloggingEsther Charlotte WilliamsNo ratings yet
- Managing e-WOMDocument32 pagesManaging e-WOMkuripNo ratings yet
- The Psychology of Blogging Communities Social Identities and Knowledge Transfer Across Work GroupsDocument2 pagesThe Psychology of Blogging Communities Social Identities and Knowledge Transfer Across Work GroupsEsther Charlotte WilliamsNo ratings yet
- Communities of Blogging Extensions of Our IdentitiesDocument10 pagesCommunities of Blogging Extensions of Our IdentitiesEsther Charlotte WilliamsNo ratings yet
- Online Peer and Editorial Recommendations, Trust, and Choice in Virtual MarketsDocument23 pagesOnline Peer and Editorial Recommendations, Trust, and Choice in Virtual MarketsEsther Charlotte WilliamsNo ratings yet
- Effects of WOM and Product - Attribute Information On Persuasion An Accessibility Diagnosticity PerspectiveDocument10 pagesEffects of WOM and Product - Attribute Information On Persuasion An Accessibility Diagnosticity PerspectiveEsther Charlotte WilliamsNo ratings yet
- Effects of WOM Vs Traditional MarketingDocument24 pagesEffects of WOM Vs Traditional MarketingEsther Charlotte WilliamsNo ratings yet
- A Multi-Stage Model of Word-Of-mouth Influence Through Viral MarketingDocument14 pagesA Multi-Stage Model of Word-Of-mouth Influence Through Viral MarketingEsther Charlotte WilliamsNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Industrial Flow Measurement: Basics and PracticeDocument0 pagesIndustrial Flow Measurement: Basics and PracticeBijoy AyyagariNo ratings yet
- Chapter 8Document44 pagesChapter 8Elmar CuellarNo ratings yet
- Guide To Better Geotextile Specifying US FABRICSDocument19 pagesGuide To Better Geotextile Specifying US FABRICSOladunni AfolabiNo ratings yet
- GRP-FT Maintenance ManualDocument20 pagesGRP-FT Maintenance ManualSaleh EttehadiNo ratings yet
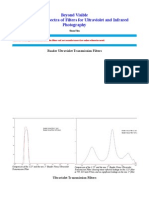
- UV IR Filter SpectraDocument12 pagesUV IR Filter SpectrajacekwikloNo ratings yet
- Homeopathic Materia Medica PDFDocument216 pagesHomeopathic Materia Medica PDFRavi Ranjan Jha100% (1)
- Mobilgrease XHP 222Document2 pagesMobilgrease XHP 222Stefan Cel MareNo ratings yet
- Tulsion A 23SMDocument2 pagesTulsion A 23SMMuhammad FikriansyahNo ratings yet
- Bellasol S16 - Technical Data Sheet - Oil Gas - 8 5x11Document2 pagesBellasol S16 - Technical Data Sheet - Oil Gas - 8 5x11dodofan2000No ratings yet
- GEOTECH 1 Module 8Document12 pagesGEOTECH 1 Module 8Earl averzosaNo ratings yet
- Load and Stress Distribution in Screw Threads With Modified WashersDocument11 pagesLoad and Stress Distribution in Screw Threads With Modified WashersminakirolosNo ratings yet
- Durethan B30S 000000: PA 6, Non-Reinforced, Injection Molding ISO Shortname: ISO 1874-PA 6, GR, 14-030Document3 pagesDurethan B30S 000000: PA 6, Non-Reinforced, Injection Molding ISO Shortname: ISO 1874-PA 6, GR, 14-030zoranNo ratings yet
- Make Up Water.r1Document54 pagesMake Up Water.r1Ranu JanuarNo ratings yet
- Exothermic and Endothermic ReactionsDocument5 pagesExothermic and Endothermic ReactionsSehyun OhNo ratings yet
- Comments Resolution Discharge Filter Coalescer Skid - Foundation - Anchor - CVL ReplyDocument1 pageComments Resolution Discharge Filter Coalescer Skid - Foundation - Anchor - CVL ReplySana UllahNo ratings yet
- Problems Based On AgesDocument2 pagesProblems Based On AgesHarish Chintu100% (1)
- Simulation Analysis of Compression Refrigeration Cycle With Different RefrigerantsDocument5 pagesSimulation Analysis of Compression Refrigeration Cycle With Different RefrigerantsSpicyNo ratings yet
- Presentation For FPGA Image ProcessingDocument14 pagesPresentation For FPGA Image ProcessingSaad KhalilNo ratings yet
- Pump CalculationsDocument20 pagesPump CalculationsPRATIK P. BHOIR50% (2)
- Farrukh Shahzad: For More Chemical Engineering Ebooks and Solution Manuals Visit HereDocument6 pagesFarrukh Shahzad: For More Chemical Engineering Ebooks and Solution Manuals Visit HereFarrukh ShahzadNo ratings yet
- Signals and Systems 1Document30 pagesSignals and Systems 1Rakesh Inani100% (1)
- 8 UV VIS PhenylephrineDocument7 pages8 UV VIS PhenylephrineEdgard Mauricio OlascuagaNo ratings yet
- FS-l6S: Instruction ManualDocument25 pagesFS-l6S: Instruction ManualFazrulNo ratings yet
- DCR Sr50eDocument77 pagesDCR Sr50epromatis0% (1)
- Unlocking The Secrets of Gann PDFDocument11 pagesUnlocking The Secrets of Gann PDFfsolomon100% (1)
- Optical Ground WireDocument14 pagesOptical Ground Wireshubham jaiswalNo ratings yet
- BioisosterismDocument22 pagesBioisosterismpurnima singhNo ratings yet
- Olympus CX - 21 Manual de Usuario PDFDocument28 pagesOlympus CX - 21 Manual de Usuario PDFApocalipsis2072No ratings yet
- Mechanical Engineering Interview Questions and AnswersDocument5 pagesMechanical Engineering Interview Questions and AnswersAlexandru NistorNo ratings yet
- Chapter 1Document11 pagesChapter 1Crist John PastorNo ratings yet