You might also like
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- WS 1: Using Dev-Pascal: Basic ConceptsDocument5 pagesWS 1: Using Dev-Pascal: Basic ConceptsUntu RangapNo ratings yet
- Building A Private Cloud Step by StepDocument9 pagesBuilding A Private Cloud Step by StepJohn ManniNo ratings yet
- COMSATS Institute of Information Technology Abbottabad: GoalsDocument2 pagesCOMSATS Institute of Information Technology Abbottabad: GoalsSohail MashwaniNo ratings yet
- Itp 4Document28 pagesItp 4Sushil PantNo ratings yet
- Marlon E. Calolot - ResumeDocument5 pagesMarlon E. Calolot - Resumeronaldrey_007No ratings yet
- Project Domain / Category: Laptop Sales Management System by Using ChabotDocument3 pagesProject Domain / Category: Laptop Sales Management System by Using ChabotjdaudpotoNo ratings yet
- How To Integrate BPC NW To BI7x Technically - Using ABAPDocument19 pagesHow To Integrate BPC NW To BI7x Technically - Using ABAPYong BenedictNo ratings yet
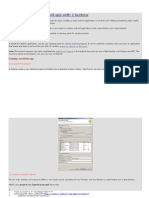
- Creating A Simple Android App With 2 Buttons: Two Button Application Use CaseDocument8 pagesCreating A Simple Android App With 2 Buttons: Two Button Application Use CaseRazzy RazzNo ratings yet
- CL23Document14 pagesCL23ENDLURI DEEPAK KUMARNo ratings yet
- ReumrDocument2 pagesReumrRaja O Romeyo NaveenNo ratings yet
- Database STIG V8R1Document54 pagesDatabase STIG V8R1bajicgoranaNo ratings yet
- Designing A State Machine To Solve A ProblemDocument8 pagesDesigning A State Machine To Solve A Problemmanik_chand_patnaikNo ratings yet
- Lect09 Solver LU SparseDocument60 pagesLect09 Solver LU SparseTeto ScheduleNo ratings yet
- Output AssignmentDocument10 pagesOutput Assignmentchins1289No ratings yet
- How To Implement A Calendar Object in An Oracle FormDocument11 pagesHow To Implement A Calendar Object in An Oracle FormBilal SalimNo ratings yet
- DSP Proakis Solution ManualDocument400 pagesDSP Proakis Solution ManualSachin KulkarniNo ratings yet
- AutoMesh2D GUI ManualDocument6 pagesAutoMesh2D GUI ManuallatecNo ratings yet
- Synopsis Employee Information System in C++Document13 pagesSynopsis Employee Information System in C++manjit100% (3)
- InfoPLC Net ManualFANUCR-J3iBDocument4 pagesInfoPLC Net ManualFANUCR-J3iBJobur MesopharmexNo ratings yet
- Use Twitter To Control Arduino Uno Via Visual BasiDocument6 pagesUse Twitter To Control Arduino Uno Via Visual BasiMu'izz KaharNo ratings yet
- MS SQL Server Interview QuestionsDocument17 pagesMS SQL Server Interview QuestionsAnilkumar000100% (4)
- Job PortalDocument13 pagesJob PortalAkhilSainiNo ratings yet
- Exercises Pythonbasics Exercises v1.0Document22 pagesExercises Pythonbasics Exercises v1.0Anonymous I0bTVBNo ratings yet
- A Security Scheme For Wireless Sensor NetworksDocument5 pagesA Security Scheme For Wireless Sensor NetworksRonaldo MilfontNo ratings yet
- PL/SQL Program UnitsDocument67 pagesPL/SQL Program Unitsdeeps21No ratings yet
- Creating A DG Broker Configuration and Standby DB in Cloud Control 12cDocument3 pagesCreating A DG Broker Configuration and Standby DB in Cloud Control 12cPraveenNo ratings yet
- Introduction To Deep Learning - With Complexe Python and TensorFlow Examples - Jürgen Brauer PDFDocument245 pagesIntroduction To Deep Learning - With Complexe Python and TensorFlow Examples - Jürgen Brauer PDFMecobioNo ratings yet
- Holo MagiskDocument1 pageHolo MagiskSeptarian Dwi CahyoNo ratings yet
- Mass-Storage Systems/ Disc Management System: Sagarika Chowdhury Asst. Professor, NIT, KolkataDocument20 pagesMass-Storage Systems/ Disc Management System: Sagarika Chowdhury Asst. Professor, NIT, KolkataAvilash GhoshNo ratings yet
- ConsenSys Cover Letter - Romeo FlautaDocument1 pageConsenSys Cover Letter - Romeo FlautaRomeo FlautaNo ratings yet