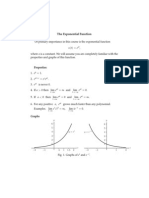
You might also like
- The Black Scholes Model-2Document58 pagesThe Black Scholes Model-2Gladys Gladys MakNo ratings yet
- High Frequency VolatilityDocument14 pagesHigh Frequency VolatilityingaleharshalNo ratings yet
- BKM9e EOC Ch27Document4 pagesBKM9e EOC Ch27Cardoso PenhaNo ratings yet
- Uses of Elementary Calculus Arising in EconomicsDocument21 pagesUses of Elementary Calculus Arising in EconomicsGautu GubbalaNo ratings yet
- Computational Fluid Dynamics Prof. Dr. Suman Chakraborty Department of Mechanical Engineering Indian Institute of Technology, KharagpurDocument13 pagesComputational Fluid Dynamics Prof. Dr. Suman Chakraborty Department of Mechanical Engineering Indian Institute of Technology, KharagpurSubhendu MaityNo ratings yet
- Modeling by First Order Linear ODE'sDocument4 pagesModeling by First Order Linear ODE'skvhprasadNo ratings yet
- Chap 06Document12 pagesChap 06julianli0220No ratings yet
- Lesson 5: Metric For A Gravitational Field: Notes From Prof. Susskind Video Lectures Publicly Available On YoutubeDocument41 pagesLesson 5: Metric For A Gravitational Field: Notes From Prof. Susskind Video Lectures Publicly Available On YoutubeMd Kaiser HamidNo ratings yet
- Lec 32Document38 pagesLec 32Ali RajaNo ratings yet
- Calculus 07 Integration 2upDocument8 pagesCalculus 07 Integration 2upblablah1245No ratings yet
- 12 Lecture 11Document4 pages12 Lecture 11muralimoviesNo ratings yet
- Stochastic Calculus and The Nobel Prize Winning Black-Scholes EquationDocument6 pagesStochastic Calculus and The Nobel Prize Winning Black-Scholes Equationnby949No ratings yet
- Elasticity Theory BasisDocument9 pagesElasticity Theory BasisGiovanni Morais TeixeiraNo ratings yet
- Homework 3 So LsDocument13 pagesHomework 3 So LsBrad StokesNo ratings yet
- Math-Differential EquationsDocument7 pagesMath-Differential EquationsEl Comedor BenedictNo ratings yet
- Thermal Physics Lecture 35Document8 pagesThermal Physics Lecture 35OmegaUserNo ratings yet
- Rms DiffusionDocument5 pagesRms DiffusionZio MaraNo ratings yet
- Velocity Gradients and StressTensorsDocument4 pagesVelocity Gradients and StressTensorskenanoNo ratings yet
- Numerical Solution of Differential EquationsDocument55 pagesNumerical Solution of Differential EquationsBrendon MuriraNo ratings yet
- ThreeDocument8 pagesThreeChandan GuptaNo ratings yet
- Chapter 2Document10 pagesChapter 2Fatima AbaidNo ratings yet
- Application of PdeDocument25 pagesApplication of Pdesanoj kumarNo ratings yet
- Navierstokes - Exercises 3Document6 pagesNavierstokes - Exercises 3sr mxeNo ratings yet
- Mathii at Su and Sse: John Hassler Iies, Stockholm University February 25, 2005Document87 pagesMathii at Su and Sse: John Hassler Iies, Stockholm University February 25, 2005kolman2No ratings yet
- Lecture 18: Scattering: Partial Wave Analysis (11/22/2005) : Classical Scattering: Impact ParameterDocument8 pagesLecture 18: Scattering: Partial Wave Analysis (11/22/2005) : Classical Scattering: Impact Parameterbgiangre8372No ratings yet
- Scribd File 8Document4 pagesScribd File 8Garcia RaphNo ratings yet
- Lec 13Document14 pagesLec 13Jigisha KapadiaNo ratings yet
- Differential Calculus Is A Subfield of CalculusDocument10 pagesDifferential Calculus Is A Subfield of CalculusIzyan Mohd SubriNo ratings yet
- Chaos RandomnessDocument10 pagesChaos RandomnessMax ProctorNo ratings yet
- Math-Differential EquationsDocument7 pagesMath-Differential EquationsEmma TillanoNo ratings yet
- Lesson 7: Falling Into A Black Hole: Notes From Prof. Susskind Video Lectures Publicly Available On YoutubeDocument34 pagesLesson 7: Falling Into A Black Hole: Notes From Prof. Susskind Video Lectures Publicly Available On YoutubeMd Kaiser HamidNo ratings yet
- A Non-Linear Black-Scholes EquationDocument8 pagesA Non-Linear Black-Scholes EquationHadiBiesNo ratings yet
- Brief Review of Quantum Mechanics (QM) : Fig 1. Spherical Coordinate SystemDocument6 pagesBrief Review of Quantum Mechanics (QM) : Fig 1. Spherical Coordinate SystemElvin Mark Muñoz VegaNo ratings yet
- Non-Linear Dynamics Homework Solutions Week 7: February 23, 2009Document9 pagesNon-Linear Dynamics Homework Solutions Week 7: February 23, 2009Maqsood AlamNo ratings yet
- Least Quadratic Non ResidueDocument18 pagesLeast Quadratic Non ResidueHuy BeepiniepNo ratings yet
- Dimensional Analysis: A Simple ExampleDocument10 pagesDimensional Analysis: A Simple ExampleMark RileyNo ratings yet
- Asymptotic Analysis and RecurrencesDocument6 pagesAsymptotic Analysis and RecurrencesApoorv SemwalNo ratings yet
- Boltzmann's and Saha's EquationsDocument22 pagesBoltzmann's and Saha's Equationssujayan2005No ratings yet
- Two Proofs of The Central Limit TheoremDocument13 pagesTwo Proofs of The Central Limit Theoremavi_weberNo ratings yet
- Foundation of Computational Fluid Dynamics Dr. S. Vengadesan Department of Applied Mechanics Indian Institute of Technology, Madras Lecture - 12Document14 pagesFoundation of Computational Fluid Dynamics Dr. S. Vengadesan Department of Applied Mechanics Indian Institute of Technology, Madras Lecture - 12mahesh dNo ratings yet
- ADG Vibrations PDFDocument7 pagesADG Vibrations PDFArchit SharmaNo ratings yet
- Computational Fluid and Solid Mechanics Full VersionDocument14 pagesComputational Fluid and Solid Mechanics Full VersionDavid WhiteNo ratings yet
- Differential EquationsDocument44 pagesDifferential EquationsSJAIN12No ratings yet
- Differential Equations: 12.1 What Is A Differential Equation?Document10 pagesDifferential Equations: 12.1 What Is A Differential Equation?imran hameerNo ratings yet
- 18 03sc Fall 2011 Differential EquationsDocument602 pages18 03sc Fall 2011 Differential EquationsAntónio CarneiroNo ratings yet
- Diffusion Equation PDFDocument33 pagesDiffusion Equation PDFDuong Quang DucNo ratings yet
- Linear Algebra and Robot Modeling: 1 Basic Kinematic EquationsDocument9 pagesLinear Algebra and Robot Modeling: 1 Basic Kinematic EquationsAbdur HamzahNo ratings yet
- 1 Estimating Uncertainties and Propagation of Errors: Physics 326, Final ExamDocument4 pages1 Estimating Uncertainties and Propagation of Errors: Physics 326, Final ExamJack BotNo ratings yet
- 01 - 01 Introduction To 1D MotionDocument20 pages01 - 01 Introduction To 1D MotionKerly Aalexander SAMO ATAVARNo ratings yet
- MA1506Document70 pagesMA1506ernie123219405No ratings yet
- Dynamic Programming 3 BellmanDocument8 pagesDynamic Programming 3 BellmanchuchomatNo ratings yet
- MA209Document117 pagesMA209prw1118No ratings yet
- Multi-Asset Options: 4.1 Pricing ModelDocument10 pagesMulti-Asset Options: 4.1 Pricing ModeldownloadfromscribdNo ratings yet
- Propagating Errors: Scalar Products: UCSD-SIO 221c: Error Propagation (Gille)Document5 pagesPropagating Errors: Scalar Products: UCSD-SIO 221c: Error Propagation (Gille)zekyNo ratings yet
- Group 6Document39 pagesGroup 61DT20CS148 Sudarshan SinghNo ratings yet
- Math Differentiation Vector Analysis AssignmentDocument8 pagesMath Differentiation Vector Analysis AssignmentJulfikar asifNo ratings yet
- Lec 04Document9 pagesLec 04JAGDISH SINGH MEHTANo ratings yet
- Mathematical Modelling and Financial Engineering in The Worlds Stock MarketsDocument7 pagesMathematical Modelling and Financial Engineering in The Worlds Stock MarketsVijay ParmarNo ratings yet
- Ito's LemmaDocument7 pagesIto's Lemmasambhu_nNo ratings yet
- Line Integral ExampleDocument7 pagesLine Integral ExampleRomesor ApolNo ratings yet
- Understanding Vector Calculus: Practical Development and Solved ProblemsFrom EverandUnderstanding Vector Calculus: Practical Development and Solved ProblemsNo ratings yet
- I$Felllillh'Tii, Nti: T " Ew ,:: .", L: I ..IDocument2 pagesI$Felllillh'Tii, Nti: T " Ew ,:: .", L: I ..IshrutigarodiaNo ratings yet
- Kimber 7 Do To Revamp Your LifeDocument2 pagesKimber 7 Do To Revamp Your LifeshrutigarodiaNo ratings yet
- Dale Carnegie - The Art of Public SpeakingDocument299 pagesDale Carnegie - The Art of Public Speakingsoba210No ratings yet
- The Janus Face of Justice: SAURABHSINGH/www - Indiatodayimages.ccDocument1 pageThe Janus Face of Justice: SAURABHSINGH/www - Indiatodayimages.ccshrutigarodiaNo ratings yet
- AESIMDocument1 pageAESIMshrutigarodiaNo ratings yet
- Mario R. Melchiori CPA Universidad Nacional Del Litoral Santa Fe - ArgentinaDocument8 pagesMario R. Melchiori CPA Universidad Nacional Del Litoral Santa Fe - ArgentinashrutigarodiaNo ratings yet
- 1 DighaDocument498 pages1 DighashrutigarodiaNo ratings yet
- Unit4 - ScienceDocument16 pagesUnit4 - ScienceshrutigarodiaNo ratings yet
- Spring 2013: Professor James VernonDocument6 pagesSpring 2013: Professor James VernonshrutigarodiaNo ratings yet
- Life in The Persian City of RayyDocument64 pagesLife in The Persian City of RayyshrutigarodiaNo ratings yet
- Labour in Medieval IslamDocument27 pagesLabour in Medieval Islamshrutigarodia0% (1)
- Maribel SevillaDocument38 pagesMaribel SevillashrutigarodiaNo ratings yet
- 19 Probability Part 2 of 3Document14 pages19 Probability Part 2 of 3MathematicsNo ratings yet
- Chandan Mandal 11.Document14 pagesChandan Mandal 11.jefferson sarmientoNo ratings yet
- Chapter 11-Inferences About Population VariancesDocument14 pagesChapter 11-Inferences About Population VariancesyayayaNo ratings yet
- PsychologyDocument65 pagesPsychologyRomeesa Noor0% (1)
- Solutions To Chapter 7Document12 pagesSolutions To Chapter 7Naa'irah RehmanNo ratings yet
- Application of ANOVADocument18 pagesApplication of ANOVAKunwar Aditya100% (1)
- AD3491 FDSA SyllabusDocument2 pagesAD3491 FDSA SyllabusSASIKUMAR BNo ratings yet
- Hasil Uji Normalitas Nim/Absen Ganjil: Case Processing SummaryDocument2 pagesHasil Uji Normalitas Nim/Absen Ganjil: Case Processing SummaryAnisaNo ratings yet
- Risk and Return Formulae PDFDocument1 pageRisk and Return Formulae PDFsatyaNo ratings yet
- Understanding Variance, Covariance, and Correlation - Count BayesieDocument19 pagesUnderstanding Variance, Covariance, and Correlation - Count BayesieBAHADIRNo ratings yet
- Jeppiaar Institute of Technology: Department OF Computer Science and EngineeringDocument27 pagesJeppiaar Institute of Technology: Department OF Computer Science and EngineeringIT-Aswin.GNo ratings yet
- MI2036 Chap2Document163 pagesMI2036 Chap2Long Trần VănNo ratings yet
- Syllabus Followed at Massey UniversityDocument17 pagesSyllabus Followed at Massey Universityjhon jackNo ratings yet
- Sharpe's ModelDocument58 pagesSharpe's ModelTausif R Maredia100% (1)
- Past Year QuestionsDocument11 pagesPast Year QuestionsHuế ThùyNo ratings yet
- Ch13 SamplingDocument17 pagesCh13 SamplingMohammad Al-arrabi Aldhidi67% (3)
- Topic 10 - Lecturer 2Document10 pagesTopic 10 - Lecturer 2Nuradriana09No ratings yet
- Basic Math SymbolsDocument20 pagesBasic Math SymbolsNoel O CedenoNo ratings yet
- Statistics - Discrete Probability DistributionsDocument36 pagesStatistics - Discrete Probability DistributionsDr Rushen SinghNo ratings yet
- Normal QuestionsDocument2 pagesNormal QuestionsAyesha AlikhanNo ratings yet
- Quiz On Standard Costing and Variance AnalysisDocument3 pagesQuiz On Standard Costing and Variance AnalysisJonah PanopioNo ratings yet
- Analysis For Power System State EstimationDocument9 pagesAnalysis For Power System State EstimationAnonymous TJRX7CNo ratings yet
- G@RCH 6.1 HelpDocument309 pagesG@RCH 6.1 HelpALVARO MIGUEL JESUS RODRIGUEZ SAENZNo ratings yet
- Factor Analysis: Sec B BeforeDocument45 pagesFactor Analysis: Sec B BeforeIzzatul Atiq RosseliNo ratings yet
- Humor in American, British and German AdsDocument12 pagesHumor in American, British and German AdsJavierrNo ratings yet
- Introduction To Probability and Statistics Course ID:MA2203: Course Teacher: Dr. Manas Ranjan TripathyDocument184 pagesIntroduction To Probability and Statistics Course ID:MA2203: Course Teacher: Dr. Manas Ranjan TripathyVihari RahulNo ratings yet
- Statistics and ProbabilityDocument76 pagesStatistics and ProbabilityBrillantes JYNo ratings yet
- MATHEMATIVS IV KAS 302 AktutorDocument10 pagesMATHEMATIVS IV KAS 302 AktutorHarsh JaiswalNo ratings yet