You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Checklist For Evaluating Whether A Group Is A Team: Yes NoDocument1 pageChecklist For Evaluating Whether A Group Is A Team: Yes NoMurali MedudulaNo ratings yet
- Aaaaaaaaaaaaaaaaaaaaa AaaaaaaaaaaaaaaaaaaaaaaaaaaaaDocument1 pageAaaaaaaaaaaaaaaaaaaaa AaaaaaaaaaaaaaaaaaaaaaaaaaaaaMurali MedudulaNo ratings yet
- X Phy Ch1 Light ConceptDocument5 pagesX Phy Ch1 Light ConceptMurali MedudulaNo ratings yet
- LiftDocument1 pageLiftMurali MedudulaNo ratings yet
- ANE BooksDocument2 pagesANE BooksMurali Medudula0% (1)
- Sunil Attendance MayDocument2 pagesSunil Attendance MayMurali MedudulaNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- hw1 Sol PDFDocument7 pageshw1 Sol PDFArif WahlaNo ratings yet
- BRM Assignment Group 6Document32 pagesBRM Assignment Group 6Pooja PandeyNo ratings yet
- Detection FundamentalsDocument52 pagesDetection FundamentalsIlya MukhinNo ratings yet
- Battese-Coelli 95Document9 pagesBattese-Coelli 95Aryo Bondan PramesworoNo ratings yet
- Budgeting and Budgetary Control in The Manufacturing Sector of NigeriaDocument14 pagesBudgeting and Budgetary Control in The Manufacturing Sector of NigeriaNeha NMNo ratings yet
- Package SurveyDocument129 pagesPackage SurveyoctavioascheriNo ratings yet
- 3 Ijhrmroct20173Document8 pages3 Ijhrmroct20173TJPRC PublicationsNo ratings yet
- Credit Loss and Systematic LGD Frye Jacobs 100611 PDFDocument31 pagesCredit Loss and Systematic LGD Frye Jacobs 100611 PDFsgjatharNo ratings yet
- Hypothesis Testing Part IDocument3 pagesHypothesis Testing Part Ilucy heartfiliaNo ratings yet
- SPSS ProjectDocument22 pagesSPSS ProjectPradeep Singha100% (2)
- LAMPIRANDocument7 pagesLAMPIRANlusia yasinta oni atawoloNo ratings yet
- Morrison - Distinguishing Between Forensic Science and Forensic PseudoscienceDocument12 pagesMorrison - Distinguishing Between Forensic Science and Forensic PseudoscienceSara Valencia SánchezNo ratings yet
- Alifa Nasyahta Rosiana 22010110110055 Bab8KTIDocument49 pagesAlifa Nasyahta Rosiana 22010110110055 Bab8KTIYudhi SetiabudiNo ratings yet
- Dickey, Fuller - 1981 - Likelihood Ratio Statistics For Autoregressive Time Series With A Unit RootDocument17 pagesDickey, Fuller - 1981 - Likelihood Ratio Statistics For Autoregressive Time Series With A Unit RootMengcheng LiuNo ratings yet
- Impact of Airbnb On Customers' BehaviorDocument15 pagesImpact of Airbnb On Customers' BehaviorGian Soleh HudinNo ratings yet
- 2.+Pragmatic+Analysis+of+the+Bhangra+Sons+of+Abrar Ul Haq+Rev2+Document18 pages2.+Pragmatic+Analysis+of+the+Bhangra+Sons+of+Abrar Ul Haq+Rev2+abudira2009No ratings yet
- Adoption and Intensity of Row-Seeding (Case of Wolaita Zone)Document12 pagesAdoption and Intensity of Row-Seeding (Case of Wolaita Zone)abraha gebruNo ratings yet
- Factors Affecting The Technical Efficiency of Dairy Farms in KosovoDocument18 pagesFactors Affecting The Technical Efficiency of Dairy Farms in KosovoBesnik KryeziuNo ratings yet
- Fin223 DraftDocument25 pagesFin223 DraftJane Susan ThomasNo ratings yet
- The Impact of Social Media On The Academic Development of School StudentsDocument8 pagesThe Impact of Social Media On The Academic Development of School Studentsؤنييه ثهعغي100% (1)
- Research On Consumer Preference For Fruit JuiceDocument31 pagesResearch On Consumer Preference For Fruit Juiceamardeep100% (6)
- Assign20153 SolDocument47 pagesAssign20153 SolMarco Perez HernandezNo ratings yet
- IJMS Vol4 Iss3 Paper4 800 808 PDFDocument9 pagesIJMS Vol4 Iss3 Paper4 800 808 PDFHarshit AgrawalNo ratings yet
- A Study On Recruitment and Selection Process in B & B Construction Private Limited, Vellore, TamilnaduDocument17 pagesA Study On Recruitment and Selection Process in B & B Construction Private Limited, Vellore, TamilnaduIJRASETPublicationsNo ratings yet
- Package SPRT': R Topics DocumentedDocument13 pagesPackage SPRT': R Topics DocumentedKo DuanNo ratings yet
- Work Life BalanceDocument51 pagesWork Life BalanceKrishnnan Sudarsanam80% (15)
- Frequencies: (Dataset1) D:/Spss Wulan/Spss - SavDocument4 pagesFrequencies: (Dataset1) D:/Spss Wulan/Spss - SavHusnul YaqinNo ratings yet
- StatisticsDocument41 pagesStatisticsSiddharth DasNo ratings yet
- Final ReportDocument50 pagesFinal ReportJayShahNo ratings yet
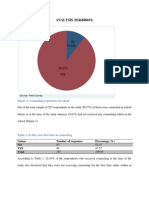
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 pagesANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNo ratings yet