You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Dinner Theater Business PlanDocument21 pagesDinner Theater Business PlanBhumika KariaNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Account Statement From 1 Oct 2018 To 15 Mar 2019: TXN Date Value Date Description Ref No./Cheque No. Debit Credit BalanceDocument8 pagesAccount Statement From 1 Oct 2018 To 15 Mar 2019: TXN Date Value Date Description Ref No./Cheque No. Debit Credit BalancerohantNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
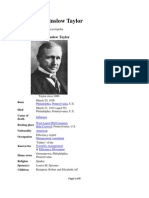
- About FW TaylorDocument9 pagesAbout FW TaylorGayaz SkNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Asia-Pacific/Arab Gulf Marketscan: Volume 39 / Issue 65 / April 2, 2020Document21 pagesAsia-Pacific/Arab Gulf Marketscan: Volume 39 / Issue 65 / April 2, 2020Donnie HavierNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- HACCP Coconuts 2019Document83 pagesHACCP Coconuts 2019Phạm Hồng Ngân100% (4)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Class Assignment 2Document3 pagesClass Assignment 2fathiahNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- DOLE Vacancies As of 01 - 10 - 13Document17 pagesDOLE Vacancies As of 01 - 10 - 13sumaychengNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Lab - Report: Experiment NoDocument6 pagesLab - Report: Experiment NoRedwan AhmedNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Application of 1,2,3-PropanetriolDocument2 pagesThe Application of 1,2,3-PropanetriolAlisameimeiNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- FLIPKART MayankDocument65 pagesFLIPKART MayankNeeraj DwivediNo ratings yet
- Guide To Downloading and Installing The WebMethods Free Trial Version - Wiki - CommunitiesDocument19 pagesGuide To Downloading and Installing The WebMethods Free Trial Version - Wiki - CommunitiesHieu NguyenNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Midterm Quiz 1 March 9.2021 QDocument5 pagesMidterm Quiz 1 March 9.2021 QThalia RodriguezNo ratings yet
- Method Statement For Backfilling WorksDocument3 pagesMethod Statement For Backfilling WorksCrazyBookWorm86% (7)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Electric Baseboard StelproDocument4 pagesElectric Baseboard StelprojrodNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- L-2 Steel SectionsDocument23 pagesL-2 Steel SectionsRukhsar JoueNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- High-Rise Climb V0.6a Smokeydots PDFDocument10 pagesHigh-Rise Climb V0.6a Smokeydots PDFHer Lan ONo ratings yet
- Book Shop InventoryDocument21 pagesBook Shop InventoryAli AnsariNo ratings yet
- Project Management PDFDocument10 pagesProject Management PDFJamalNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Blanko Permohonan VettingDocument1 pageBlanko Permohonan VettingTommyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Method Statement: Vetotop XT539Document4 pagesMethod Statement: Vetotop XT539محمد عزتNo ratings yet
- Resume 202309040934Document5 pagesResume 202309040934dubai eyeNo ratings yet
- Challenges Faced by DMRCDocument2 pagesChallenges Faced by DMRCSourabh Kr67% (3)
- ANSYS 14.0 Fluid Dynamics Update - Dipankar ChoudhuryDocument87 pagesANSYS 14.0 Fluid Dynamics Update - Dipankar Choudhuryj_c_garcia_d100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Astm D2940 D2940M 09Document1 pageAstm D2940 D2940M 09INDIRA DEL CARMEN BERMEJO FERN�NDEZNo ratings yet
- TCO & TCU Series Container Lifting Lugs - Intercon EnterprisesDocument4 pagesTCO & TCU Series Container Lifting Lugs - Intercon EnterprisesReda ElawadyNo ratings yet
- Move It 3. Test U3Document2 pagesMove It 3. Test U3Fabian AmayaNo ratings yet
- NDA For Consultants Template-1Document4 pagesNDA For Consultants Template-1David Jay Mor100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Enhancing LAN Using CryptographyDocument2 pagesEnhancing LAN Using CryptographyMonim Moni100% (1)
- MAC120 PartsDocument23 pagesMAC120 PartspRAMOD g pATOLENo ratings yet
- Application For MigrationDocument8 pagesApplication For Migrationmoments444No ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)