You might also like
- Chapter 1 Tension, Compression, and ShearDocument27 pagesChapter 1 Tension, Compression, and ShearManolo L LandigNo ratings yet
- Analyze Rigid Frames and Composite StructuresDocument14 pagesAnalyze Rigid Frames and Composite StructuresGinoOcampo100% (1)
- Equilibrium of Deformable Bodies Practice ProblemsDocument2 pagesEquilibrium of Deformable Bodies Practice ProblemsAndre Boco100% (1)
- Mechanics of Deformable BodiesDocument2 pagesMechanics of Deformable BodiesJeff LaycoNo ratings yet
- Transportation Engineering BasicsDocument15 pagesTransportation Engineering BasicsXienlyn BaybayNo ratings yet
- Highway EngineeringDocument10 pagesHighway EngineeringIshaan LaskarNo ratings yet
- Mechanics of Solids Lecture on Stress ConceptsDocument38 pagesMechanics of Solids Lecture on Stress Conceptsjust_friends199No ratings yet
- Module 1.0-SIMPLE STRESS - Axial-NormalDocument20 pagesModule 1.0-SIMPLE STRESS - Axial-NormalJoseph Berlin JuanzonNo ratings yet
- Introduction to Structural AnalysisDocument2 pagesIntroduction to Structural AnalysisMelvin EsguerraNo ratings yet
- Set TheroyDocument22 pagesSet TheroyManojNo ratings yet
- FortranDocument11 pagesFortranwilrocaNo ratings yet
- CHAPTER 1 Introduction To StaticsDocument39 pagesCHAPTER 1 Introduction To StaticsDavid MurphyNo ratings yet
- MTPPT4 - Design of Isolated FootingDocument19 pagesMTPPT4 - Design of Isolated FootingMineski Prince GarmaNo ratings yet
- Od & Parking StudiesDocument154 pagesOd & Parking StudiesMichael KpeglahNo ratings yet
- Analysis and Design NISADocument4 pagesAnalysis and Design NISARavi Pratap SinghNo ratings yet
- ToolsDocument10 pagesToolsapi-272754098No ratings yet
- Indetermine StructureDocument8 pagesIndetermine Structuremaloy100% (1)
- INTRODUCTION (Cont..) : TIN 205-TIN31 Engineering MechanicsDocument47 pagesINTRODUCTION (Cont..) : TIN 205-TIN31 Engineering Mechanicsgundul paculNo ratings yet
- Chapter 2 Part 1 - Deflection MacaulayDocument51 pagesChapter 2 Part 1 - Deflection MacaulayHuraiz KaleemNo ratings yet
- Engineering-Mechanics Notes PDFDocument100 pagesEngineering-Mechanics Notes PDFMahesh RamtekeNo ratings yet
- Ohms Law VD CD KVL and KCLDocument50 pagesOhms Law VD CD KVL and KCLParinay SethNo ratings yet
- Stresses and DeformationsDocument3 pagesStresses and DeformationsWency LagumbayNo ratings yet
- Prestressed IntroductionDocument39 pagesPrestressed IntroductionAndri Azhari WicaksonoNo ratings yet
- 00.syllabus in Construction Materials and TestingDocument10 pages00.syllabus in Construction Materials and TestingCarjez LoveNo ratings yet
- VTU Mechanical Strain GagesDocument14 pagesVTU Mechanical Strain GagesarjunNo ratings yet
- L1Document7 pagesL1Francisco Roberto Trujillo LeonNo ratings yet
- Problem Set No.1-MidtermDocument31 pagesProblem Set No.1-MidtermROYCE1983No ratings yet
- Statics Mechanics GuideDocument210 pagesStatics Mechanics Guideabdul khader100% (1)
- Gate 2001Document10 pagesGate 2001tonykalladaNo ratings yet
- Cad NotesDocument44 pagesCad NotesChandan M R GowdaNo ratings yet
- The Boundary Value Problem For Second Order Ordinary Linear Differential Equation With Variable CoefficientDocument44 pagesThe Boundary Value Problem For Second Order Ordinary Linear Differential Equation With Variable CoefficientGMAILNo ratings yet
- ECS226 - Chapter 4 Buckling of ColumnDocument34 pagesECS226 - Chapter 4 Buckling of ColumnYasmin QashrinaNo ratings yet
- Principles of Reinforced ConcreteDocument18 pagesPrinciples of Reinforced Concreteiking_balonNo ratings yet
- Numerical Methods Lecture 0Document6 pagesNumerical Methods Lecture 0Prem KumarNo ratings yet
- Ethics 3Document34 pagesEthics 3Zuhair NadeemNo ratings yet
- IEEE Student BranchDocument8 pagesIEEE Student BranchPrajakta PatilNo ratings yet
- Isometric ProjectionsDocument62 pagesIsometric ProjectionsRoni EnjelaniNo ratings yet
- Engineering Data AnalysisDocument7 pagesEngineering Data AnalysisJulie Ann ZafraNo ratings yet
- Engineering ManagementDocument26 pagesEngineering ManagementPam Sy100% (1)
- 7) C3 Further Trigonometric Identities and Their ApplicationsDocument45 pages7) C3 Further Trigonometric Identities and Their ApplicationszzaanNo ratings yet
- Structural Steel Design Course Plan - 2015 PDFDocument7 pagesStructural Steel Design Course Plan - 2015 PDFMohamed EsamNo ratings yet
- Chapter 4 Distributed ForcesDocument39 pagesChapter 4 Distributed ForcesRenu SekaranNo ratings yet
- Module #1 – Simple StressDocument38 pagesModule #1 – Simple StressJeffrey ManansalaNo ratings yet
- MAE 384 Numerical MethodsDocument21 pagesMAE 384 Numerical MethodssharunnizamNo ratings yet
- Introduction To Simple StressDocument13 pagesIntroduction To Simple StressRie LiNo ratings yet
- Amos 1Document134 pagesAmos 1Krishna Kumar AlagarNo ratings yet
- ME 16 - Introduction + Fundamentals + Forces (Up To Scalar Rectangular Components) 2 PDFDocument25 pagesME 16 - Introduction + Fundamentals + Forces (Up To Scalar Rectangular Components) 2 PDFAshley Young100% (2)
- Numerical Calculation of J-Integral Using Finite Element MethodDocument4 pagesNumerical Calculation of J-Integral Using Finite Element Methodbaja2011100% (1)
- Chapter 4 PDFDocument48 pagesChapter 4 PDFmidju dugassaNo ratings yet
- Course Documents Advanced Foundation EngineeringDocument5 pagesCourse Documents Advanced Foundation EngineeringjbjuanzonNo ratings yet
- Chapter ObjectivesDocument73 pagesChapter Objectivesmazin jaderNo ratings yet
- Advanced Level Pure Mathematics Chapter 4 DerivativesDocument28 pagesAdvanced Level Pure Mathematics Chapter 4 DerivativesIan ChanNo ratings yet
- Optimization Methods (Lecture India)Document267 pagesOptimization Methods (Lecture India)daselknam50% (2)
- Structural Analysis NotesDocument166 pagesStructural Analysis NotesdunyNo ratings yet
- CH 12Document118 pagesCH 12Priyanka CholletiNo ratings yet
- Managing production and service operationsDocument39 pagesManaging production and service operationsjulito paquitNo ratings yet
- Finite Element Method Solver for Poisson's EquationDocument4 pagesFinite Element Method Solver for Poisson's EquationRizwan SamorNo ratings yet
- Differential GeometryDocument125 pagesDifferential Geometrynimbigli7943100% (1)
- Risk Sharing in JVsDocument162 pagesRisk Sharing in JVsAbraham JyothimonNo ratings yet
- Computer Organization and Design SolutionsDocument228 pagesComputer Organization and Design SolutionsJonathan Cui58% (12)
- GDL Louvre CalculatorDocument1 pageGDL Louvre CalculatorAbraham JyothimonNo ratings yet
- How Einstein Formed RelativityDocument2 pagesHow Einstein Formed RelativityAbraham JyothimonNo ratings yet
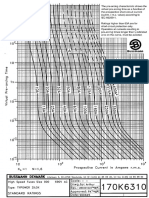
- Bussman CurvesDocument2 pagesBussman CurvesAbraham JyothimonNo ratings yet
- E-Dilation (Prohorov Metric)Document19 pagesE-Dilation (Prohorov Metric)Abraham JyothimonNo ratings yet
- Work System Concepts ExplainedDocument12 pagesWork System Concepts ExplainedAbraham JyothimonNo ratings yet
- (Dewa-98%) Anova-Safety and Secuirty ScoreDocument6 pages(Dewa-98%) Anova-Safety and Secuirty ScoreAbraham JyothimonNo ratings yet
- Consept Mind Mapping PDFDocument23 pagesConsept Mind Mapping PDFDian FithriaNo ratings yet
- Inequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007Document348 pagesInequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007mago622100% (2)
- Corrosion PDFDocument5 pagesCorrosion PDFAntonio MartinNo ratings yet
- Resource Allocation Mechanism-Detailed ProgtammingDocument27 pagesResource Allocation Mechanism-Detailed ProgtammingAbraham JyothimonNo ratings yet
- Permit Process FOR PV sYSTEMS PDFDocument82 pagesPermit Process FOR PV sYSTEMS PDFAbraham Jyothimon100% (1)
- Iso 12944 PDFDocument4 pagesIso 12944 PDFAdana100% (1)
- Complex Measure &positive MeasureDocument1 pageComplex Measure &positive MeasureAbraham JyothimonNo ratings yet
- Game Theory Equilibrium Selection Bayesian Approach ThreatsDocument3 pagesGame Theory Equilibrium Selection Bayesian Approach ThreatsAbraham JyothimonNo ratings yet
- Importance of Loop Impedance TesterDocument4 pagesImportance of Loop Impedance TesterAbraham JyothimonNo ratings yet
- Damage Survey and Risk AssessmentDocument12 pagesDamage Survey and Risk AssessmentAbraham JyothimonNo ratings yet
- Lecture Notes On Differential GamesDocument77 pagesLecture Notes On Differential GamesOctavio MartinezNo ratings yet
- Arc Flash - Enclosure-Reducing FactorDocument7 pagesArc Flash - Enclosure-Reducing FactorAbraham JyothimonNo ratings yet
- Planning by Minkowiski MetricDocument22 pagesPlanning by Minkowiski MetricAbraham JyothimonNo ratings yet
- BEST Sperners Lemma PPADDocument23 pagesBEST Sperners Lemma PPADAbraham JyothimonNo ratings yet
- UAE Labor Law Guide - Employment Contracts, Probation, Leave & TerminationDocument5 pagesUAE Labor Law Guide - Employment Contracts, Probation, Leave & TerminationPc SubramaniNo ratings yet
- Economicsproofseparating WeitzmanDocument6 pagesEconomicsproofseparating WeitzmanAbraham JyothimonNo ratings yet
- Bosch PaDocument498 pagesBosch PaAbraham JyothimonNo ratings yet
- 6handle Rule NecDocument95 pages6handle Rule NecAbraham Jyothimon100% (1)
- Riemann SurfaceDocument71 pagesRiemann SurfaceAbir DeyNo ratings yet
- Upper & Lower Contour SetsDocument12 pagesUpper & Lower Contour SetsAbraham JyothimonNo ratings yet
- Flood DetectorDocument20 pagesFlood DetectorAbraham JyothimonNo ratings yet
- Linear Algebra and Linear TransformationDocument6 pagesLinear Algebra and Linear Transformationsample surveyNo ratings yet
- Embedded System Lab Question PaperDocument4 pagesEmbedded System Lab Question PapervickyskarthikNo ratings yet
- Review of Arrays, Vectors and MatricesDocument6 pagesReview of Arrays, Vectors and MatricesTauseefNo ratings yet
- MA122 Introductory Linear Algebra Final ExamDocument8 pagesMA122 Introductory Linear Algebra Final ExamClinton OsaweNo ratings yet
- Fuzzy Eigenvalues and Fuzzy Eigen Vectors For Fuzzy MatrixDocument6 pagesFuzzy Eigenvalues and Fuzzy Eigen Vectors For Fuzzy MatrixarcherselevatorsNo ratings yet
- Unit 4: Linear Transformation: V T U T V U T U CT Cu TDocument28 pagesUnit 4: Linear Transformation: V T U T V U T U CT Cu TFITSUM SEIDNo ratings yet
- 00218Document26 pages00218Vlad LazãrNo ratings yet
- talkCAJH wk4-1Document40 pagestalkCAJH wk4-1Eligius MartinezNo ratings yet
- Fa 19 Ex 7 SolDocument6 pagesFa 19 Ex 7 Solsh zeshan iqbal ZeshanNo ratings yet
- Matrix Models for Business Analysis and Economic PlanningDocument6 pagesMatrix Models for Business Analysis and Economic PlanningAfnan RahmanNo ratings yet
- Week 8: 5.2 Independence & DimensionDocument11 pagesWeek 8: 5.2 Independence & DimensionDPNo ratings yet
- Function of Several Variables Assignment: Mathophilic Education Mob. No.-7239082744Document10 pagesFunction of Several Variables Assignment: Mathophilic Education Mob. No.-7239082744SunnyNo ratings yet
- Matrix Multiplication: Jackie Nicholas Mathematics Learning Centre University of SydneyDocument16 pagesMatrix Multiplication: Jackie Nicholas Mathematics Learning Centre University of SydneyROMMEL DORINNo ratings yet
- Practice for Linear Algebra Final ExamDocument6 pagesPractice for Linear Algebra Final ExamShela RamosNo ratings yet
- Cc201-N-Engineering Mathematics - IiDocument4 pagesCc201-N-Engineering Mathematics - IiDev OzaNo ratings yet
- 5 Year Int Linear Algebra 2022Document4 pages5 Year Int Linear Algebra 2022PrachiNo ratings yet
- 3 OperationsDocument8 pages3 OperationsVinayak DuttaNo ratings yet
- Chapter 5 - The Vector Space RNDocument54 pagesChapter 5 - The Vector Space RNDương Đặng MinhNo ratings yet
- Week 2Document45 pagesWeek 2salim ucarNo ratings yet
- 4 QR Factorization: 4.1 Reduced vs. Full QRDocument12 pages4 QR Factorization: 4.1 Reduced vs. Full QRMohammad Umar RehmanNo ratings yet
- Chapter 1Document92 pagesChapter 1LEE LEE LAUNo ratings yet
- Range of A Linear TransformationDocument35 pagesRange of A Linear TransformationPilar ZárateNo ratings yet
- Key of TEST-NDA-1-2020 PDFDocument4 pagesKey of TEST-NDA-1-2020 PDFChintan lakhnotraNo ratings yet
- Chapter 0 - Miscellaneous Preliminaries: EE 520: Topics - Compressed Sensing Linear Algebra ReviewDocument18 pagesChapter 0 - Miscellaneous Preliminaries: EE 520: Topics - Compressed Sensing Linear Algebra ReviewmohanNo ratings yet
- Linear Algebra - Module 1Document52 pagesLinear Algebra - Module 1TestNo ratings yet
- Concave and Convex Functions ExplainedDocument12 pagesConcave and Convex Functions ExplainedShruti HalderNo ratings yet
- Homework # 02Document2 pagesHomework # 02Mazhar AliNo ratings yet
- 05 OrthogonalizationDocument36 pages05 OrthogonalizationAlexandru Daniel LacraruNo ratings yet
- ACM ASSIGNMENT-2: Doolittle LU Decomposition and Cholesky Method Matlab CodeDocument6 pagesACM ASSIGNMENT-2: Doolittle LU Decomposition and Cholesky Method Matlab CodePritesh KumarNo ratings yet
- Al-Junaid Institute Group Matrix ProblemsDocument30 pagesAl-Junaid Institute Group Matrix ProblemsMoon100% (2)