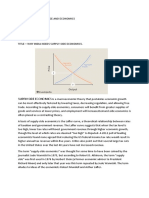
You might also like
- Chapter 2: Development and Classification: International Accounting, 7/eDocument14 pagesChapter 2: Development and Classification: International Accounting, 7/eadhitiyaNo ratings yet
- CH 09Document172 pagesCH 09Lisset Soraya Huamán QuispeNo ratings yet
- 09 Multi-Equations Econometrics ModelDocument26 pages09 Multi-Equations Econometrics ModelSalonica Oktaviani LimbongNo ratings yet
- Chapter 23 - Measuring A Nation's IncomeDocument22 pagesChapter 23 - Measuring A Nation's IncomeDannia PunkyNo ratings yet
- General Equilibrium Tax Incidence AnalysisDocument38 pagesGeneral Equilibrium Tax Incidence AnalysisjayaniNo ratings yet
- Jurnal Marketing 4.0Document9 pagesJurnal Marketing 4.0Benedictus Rosario ArdeliantoNo ratings yet
- Chapter 11-12 QuestionsDocument6 pagesChapter 11-12 QuestionsFreeBooksandMaterialNo ratings yet
- Business CycleDocument13 pagesBusiness CycleAanchal SetiaNo ratings yet
- FSCED6 - Economic MultipliersDocument4 pagesFSCED6 - Economic MultipliersSt_LairNo ratings yet
- Chapt08 Krugman 46657 09 IE C08 FDocument63 pagesChapt08 Krugman 46657 09 IE C08 FMihai StoicaNo ratings yet
- Contemporary Models of DevelopmentDocument46 pagesContemporary Models of DevelopmentMuhammad Waqas100% (1)
- Factors Influencing Loan to Deposit Ratio of Indonesian BanksDocument15 pagesFactors Influencing Loan to Deposit Ratio of Indonesian BanksDevi AlwiaaNo ratings yet
- Switching Models: Introductory Econometrics For Finance' © Chris Brooks 2013 1Document33 pagesSwitching Models: Introductory Econometrics For Finance' © Chris Brooks 2013 1Zohra BelmaghniNo ratings yet
- Industrial clusters and regional innovation: an evaluation and implications for economic cohesion (Eng)/ Clusters industriales e innovación regional (Ing)/ Industri klusterrak eta eskualdeko berrikuntza (Ing)Document18 pagesIndustrial clusters and regional innovation: an evaluation and implications for economic cohesion (Eng)/ Clusters industriales e innovación regional (Ing)/ Industri klusterrak eta eskualdeko berrikuntza (Ing)EKAI CenterNo ratings yet
- Probit AnalysisDocument30 pagesProbit AnalysisixitriflorNo ratings yet
- L2 Efficient Capital Markets CH14Document25 pagesL2 Efficient Capital Markets CH14TenkaNo ratings yet
- C09 +chap+16 +Capital+Structure+-+Basic+ConceptsDocument24 pagesC09 +chap+16 +Capital+Structure+-+Basic+Conceptsstanley tsangNo ratings yet
- The Story of MacroeconomicsDocument32 pagesThe Story of MacroeconomicsMohammadTabbalNo ratings yet
- Chap011.Ppt-Pricing Business Strategy - Ppt-February 2017Document26 pagesChap011.Ppt-Pricing Business Strategy - Ppt-February 2017AgnesNo ratings yet
- Pengantar Ekonometrika TerapanDocument23 pagesPengantar Ekonometrika TerapanAdi LesmanaNo ratings yet
- Analisis Pengaruh Volatilitas Nilai TukarDocument40 pagesAnalisis Pengaruh Volatilitas Nilai TukarjonesjillyNo ratings yet
- Exchange Rate RegimesDocument31 pagesExchange Rate RegimesDrTroy100% (1)
- Chapter 3 Quantitative Demand AnalysisDocument25 pagesChapter 3 Quantitative Demand AnalysisRosa WillisNo ratings yet
- Political Risk: Prof Mahesh Kumar Amity Business SchoolDocument41 pagesPolitical Risk: Prof Mahesh Kumar Amity Business SchoolasifanisNo ratings yet
- YtfvghjfrtgyuhjhiyjDocument55 pagesYtfvghjfrtgyuhjhiyjAlief Nauval100% (1)
- 2-Siklus RegresiDocument27 pages2-Siklus RegresiAryNo ratings yet
- Chapter 24 Measuring The Cost of LivingDocument32 pagesChapter 24 Measuring The Cost of Livingrizal priwardanaNo ratings yet
- Limit Pricing, Entry Deterrence and Predatory PricingDocument16 pagesLimit Pricing, Entry Deterrence and Predatory PricingAnwesha GhoshNo ratings yet
- Time Series Models and ApplicationsDocument70 pagesTime Series Models and Applications1111111111111-859751No ratings yet
- Summary Chap 12, MKL, Findi Kumala DewiDocument5 pagesSummary Chap 12, MKL, Findi Kumala Dewiresty auliaNo ratings yet
- Econometrics ProjectDocument9 pagesEconometrics Projectkalpendu rawatNo ratings yet
- Case Econ08 PPT 21Document38 pagesCase Econ08 PPT 21Chitrakalpa SenNo ratings yet
- Multiple Regression Model ExplainedDocument166 pagesMultiple Regression Model ExplainedRay Vega LugoNo ratings yet
- CHAP19Document35 pagesCHAP19veveng100% (1)
- Chapter 12Document38 pagesChapter 12Shiela MaeaNo ratings yet
- CH 15 - MicroDocument32 pagesCH 15 - MicroRitika NandaNo ratings yet
- Econometric Analysis of Panel Data: William Greene Department of Economics Stern School of BusinessDocument37 pagesEconometric Analysis of Panel Data: William Greene Department of Economics Stern School of BusinessWaleed Said SolimanNo ratings yet
- Analyzing GDP: Components, Measurement, and LimitationsDocument70 pagesAnalyzing GDP: Components, Measurement, and LimitationsMichelleJohnsonNo ratings yet
- CBADocument7 pagesCBAAida Kamila ArzulkhaNo ratings yet
- Jurnal Pengaruh Tingkat Suku Bunga, Inflasi, Nilai Tukar Kurs Dollar Dan Indeks Strait Times Terhadap IhsgDocument10 pagesJurnal Pengaruh Tingkat Suku Bunga, Inflasi, Nilai Tukar Kurs Dollar Dan Indeks Strait Times Terhadap Ihsgtitiktitik101No ratings yet
- Business Economics Why India Needs Supply Side EconomicsDocument7 pagesBusiness Economics Why India Needs Supply Side Economicsrishi jainNo ratings yet
- MH MIEPP 2015 Vers 20 10 2015Document131 pagesMH MIEPP 2015 Vers 20 10 2015sdfNo ratings yet
- Stie Malangkuçeçwara Malang Program Pasca Sarjana Ujian Tengah SemesterDocument13 pagesStie Malangkuçeçwara Malang Program Pasca Sarjana Ujian Tengah SemesterDwi Merry WijayantiNo ratings yet
- Econometrics: Domodar N. GujaratiDocument36 pagesEconometrics: Domodar N. GujaratiHamid UllahNo ratings yet
- Managing in Competitive, Monopolistic and Monopolistically Competitive MarketDocument27 pagesManaging in Competitive, Monopolistic and Monopolistically Competitive MarketPutri AmandhariNo ratings yet
- Applied Econometrics NotesDocument3 pagesApplied Econometrics NotesNga NguyenNo ratings yet
- Lecture 1 Policy AnalysisDocument31 pagesLecture 1 Policy Analysissalman khalidNo ratings yet
- CH 13Document53 pagesCH 13Lisset Soraya Huamán QuispeNo ratings yet
- Ch11 SlidesDocument49 pagesCh11 SlidesFarah AliNo ratings yet
- Managerial Optimism and How it Impacts Corporate Finance DecisionsDocument26 pagesManagerial Optimism and How it Impacts Corporate Finance Decisionsme_sfc100% (1)
- Aggregate Demand and Aggregate Supply EconomicsDocument38 pagesAggregate Demand and Aggregate Supply EconomicsEsha ChaudharyNo ratings yet
- Chapter 11 Walter Nicholson Microcenomic TheoryDocument15 pagesChapter 11 Walter Nicholson Microcenomic TheoryUmair QaziNo ratings yet
- A Contingency Framework For The Design of Accounting Information SystemDocument15 pagesA Contingency Framework For The Design of Accounting Information SystemAdeel RanaNo ratings yet
- Econometrics 1 Topic 1Document38 pagesEconometrics 1 Topic 1Iskandar ZulkarnaenNo ratings yet
- Indonesian Economic OverviewDocument29 pagesIndonesian Economic OverviewMutiara AuditaNo ratings yet
- Advanced Microeconometrics (Lecture 6) : The Economics and Econometrics of Policy Evaluations (1.introduction)Document21 pagesAdvanced Microeconometrics (Lecture 6) : The Economics and Econometrics of Policy Evaluations (1.introduction)Joab Dan Valdivia CoriaNo ratings yet
- Empirical Methods For Microeconomic Applications: William Greene Department of Economics Stern School of BusinessDocument56 pagesEmpirical Methods For Microeconomic Applications: William Greene Department of Economics Stern School of BusinessEduardo UCNo ratings yet
- Ecotrics (PR) Panel Data 2Document16 pagesEcotrics (PR) Panel Data 2Arka DasNo ratings yet
- Chapter 14 Advanced Panel Data Methods: T T Derrorterm Complicate X yDocument13 pagesChapter 14 Advanced Panel Data Methods: T T Derrorterm Complicate X ydsmile1No ratings yet
- Multiple Choice Questions: Practice Problem Set 6 Unions and ArbitrationDocument2 pagesMultiple Choice Questions: Practice Problem Set 6 Unions and ArbitrationAyu Sondang Hasian TobingNo ratings yet
- Econ Practice Problem Set 4 - Pay, Productivity & DiscriminationDocument2 pagesEcon Practice Problem Set 4 - Pay, Productivity & DiscriminationAyu Sondang Hasian TobingNo ratings yet
- Weight Loss Meal PlanDocument9 pagesWeight Loss Meal PlanGeorgiana9067% (3)
- Econ Practice Problem Set 4 - Pay, Productivity & DiscriminationDocument2 pagesEcon Practice Problem Set 4 - Pay, Productivity & DiscriminationAyu Sondang Hasian TobingNo ratings yet
- Jur Nal Poverty 2Document18 pagesJur Nal Poverty 2Ayu Sondang Hasian TobingNo ratings yet
- Kuliah IIIDocument28 pagesKuliah IIIollachanNo ratings yet
- Rura Labor MarketDocument49 pagesRura Labor MarketAyu Sondang Hasian TobingNo ratings yet
- NBER Paper on Statistical Models of Sample Selection, Truncation and Limited Dependent VariablesDocument19 pagesNBER Paper on Statistical Models of Sample Selection, Truncation and Limited Dependent VariablesngaNo ratings yet
- Chapter19 ModelsofNonstationaryTimeSeriesDocument19 pagesChapter19 ModelsofNonstationaryTimeSeriesTavonga Stonard MangwiroNo ratings yet
- Econometrics Chapter 8 PPT SlidesDocument42 pagesEconometrics Chapter 8 PPT SlidesIsabelleDwight100% (1)
- Cheat SheetDocument4 pagesCheat SheetshaziadurraniNo ratings yet
- Introductory Econometrics A Modern Approach 5th Edition Wooldridge Solutions ManualDocument25 pagesIntroductory Econometrics A Modern Approach 5th Edition Wooldridge Solutions ManualStephanieMckayeqwr100% (58)
- Unit 09 - Inference For Regression - 4 Per PageDocument16 pagesUnit 09 - Inference For Regression - 4 Per PageKase1No ratings yet
- Week 3 - The SLRM (2) - Updated PDFDocument49 pagesWeek 3 - The SLRM (2) - Updated PDFWindyee TanNo ratings yet
- Properties of OLS Estimators: BLUEDocument2 pagesProperties of OLS Estimators: BLUERustamzad GulNo ratings yet
- SAS/ETS PROCEDURES SUMMARYDocument10 pagesSAS/ETS PROCEDURES SUMMARYjitenNo ratings yet
- Redux AsyncDocument3 pagesRedux AsyncParesh LahadeNo ratings yet
- Econometrics Board QuestionsDocument13 pagesEconometrics Board QuestionsSushwet AmatyaNo ratings yet
- The Simple Linear Regression Model: Specification and EstimationDocument66 pagesThe Simple Linear Regression Model: Specification and EstimationKumar AkNo ratings yet
- Doing Good or Doing Well? Image Motivation and Monetary IncentivesDocument32 pagesDoing Good or Doing Well? Image Motivation and Monetary IncentivesEdwin ReyNo ratings yet
- Impact of Internet Banking in Profitability On Commercial BankDocument15 pagesImpact of Internet Banking in Profitability On Commercial BankNisarg DarjiNo ratings yet
- Simulation Models S AsDocument7 pagesSimulation Models S AsngyncloudNo ratings yet
- Simultaneity Bias in OlsDocument2 pagesSimultaneity Bias in OlsPaul Pornpawit BrimbleNo ratings yet
- Gretl and R: Interacting with R from within GretlDocument46 pagesGretl and R: Interacting with R from within GretlTaha NajidNo ratings yet
- Econometrics: Multicollinearity: What Happens If The Regressors Are Correlated?Document45 pagesEconometrics: Multicollinearity: What Happens If The Regressors Are Correlated?whoosh2008No ratings yet
- Greene FrontiersDocument158 pagesGreene FrontiershenryNo ratings yet
- Download ebook Business Analytics 5E Pdf full chapter pdfDocument67 pagesDownload ebook Business Analytics 5E Pdf full chapter pdfjerry.matson224100% (23)
- Journal of Applied Statistics Volume 43 Issue 7 2016 (Doi 10.1080/02664763.2015.1094036) Caudill, Steven B. Mixon, Franklin G. - Estimating Class-Specific Parametric Models Using Finite MixDocument10 pagesJournal of Applied Statistics Volume 43 Issue 7 2016 (Doi 10.1080/02664763.2015.1094036) Caudill, Steven B. Mixon, Franklin G. - Estimating Class-Specific Parametric Models Using Finite MixrodrigoromoNo ratings yet
- FRM一级强化段定量分析 Crystal 金程教育 (标准版Document156 pagesFRM一级强化段定量分析 Crystal 金程教育 (标准版Kexian WuNo ratings yet
- Linear Regression Slope CoefficientDocument8 pagesLinear Regression Slope CoefficientgddNo ratings yet
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
- All Cheat SheetsDocument5 pagesAll Cheat SheetsteteNo ratings yet
- Enders 1995 ARCHDocument28 pagesEnders 1995 ARCHLuis ZamoraNo ratings yet
- 16Document34 pages16admin2146No ratings yet
- On Measuring Political Violence - Northern Ireland, 1969 To 1980Document12 pagesOn Measuring Political Violence - Northern Ireland, 1969 To 1980johnmay1968No ratings yet
- Time Series Analysis MethodsDocument79 pagesTime Series Analysis MethodsHector GarciaNo ratings yet
- Harvard Ec 1123 Econometrics Problem Set 6 - Tarun Preet SinghDocument3 pagesHarvard Ec 1123 Econometrics Problem Set 6 - Tarun Preet Singhtarun singhNo ratings yet