You might also like
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankFrom EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankNo ratings yet
- Biostatistics For Academic3Document28 pagesBiostatistics For Academic3Semo gh28No ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Normal DistributionDocument29 pagesNormal Distributionatul_rockstarNo ratings yet
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- Probability & Probability Distribution 2Document28 pagesProbability & Probability Distribution 2Amanuel MaruNo ratings yet
- CFA Level 1 Review - Quantitative MethodsDocument10 pagesCFA Level 1 Review - Quantitative MethodsAamirx6450% (2)
- The Normal Distribution and Other Continuous Distribution: Dr. K. M. Salah UddinDocument50 pagesThe Normal Distribution and Other Continuous Distribution: Dr. K. M. Salah UddinfaisalNo ratings yet
- Tugas Kuliah StatistikaDocument4 pagesTugas Kuliah StatistikaCEOAmsyaNo ratings yet
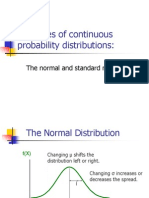
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuNo ratings yet
- H4 ExpectedValue NormalDistribution SolutionDocument6 pagesH4 ExpectedValue NormalDistribution SolutionHennrocksNo ratings yet
- Normal DistributionDocument29 pagesNormal DistributionMohamed Abd El-MoniemNo ratings yet
- Probability and Inference: Random VariablesDocument22 pagesProbability and Inference: Random VariablescrutiliNo ratings yet
- The Normal Distribution 5: Elementary StatisticsDocument34 pagesThe Normal Distribution 5: Elementary StatisticsNoor HafizahNo ratings yet
- Pro Band StatDocument27 pagesPro Band StatSunu PradanaNo ratings yet
- AIMDocument8 pagesAIMSaqib AliNo ratings yet
- Topic20 8p7 GalvinDocument53 pagesTopic20 8p7 GalvinJude SantosNo ratings yet
- Point and Interval Estimation-26!08!2011Document28 pagesPoint and Interval Estimation-26!08!2011Syed OvaisNo ratings yet
- Tugas Kuliah Statistika SESI 4Document4 pagesTugas Kuliah Statistika SESI 4CEOAmsyaNo ratings yet
- Basic Probability Reference Sheet: February 27, 2001Document8 pagesBasic Probability Reference Sheet: February 27, 2001Ibrahim TakounaNo ratings yet
- AssignmentDocument11 pagesAssignmentshan khanNo ratings yet
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalNo ratings yet
- Chapter 3Document6 pagesChapter 3Frendick LegaspiNo ratings yet
- Multiple Linear RegressionDocument18 pagesMultiple Linear RegressionJohn DoeNo ratings yet
- Pattern Basics and Related OperationsDocument21 pagesPattern Basics and Related OperationsSri VatsaanNo ratings yet
- Chapter 6Document30 pagesChapter 6Mohd Nazri OthmanNo ratings yet
- Binomial, Poison and Normal Probability DistributionsDocument20 pagesBinomial, Poison and Normal Probability DistributionsFrank VenanceNo ratings yet
- Continuous Probability Distribution PDFDocument47 pagesContinuous Probability Distribution PDFDipika PandaNo ratings yet
- Normal Distribution-7Document5 pagesNormal Distribution-7Shobha Kumari ChoudharyNo ratings yet
- f (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,Document4 pagesf (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,missy74No ratings yet
- ECON1203 PASS Week 3Document4 pagesECON1203 PASS Week 3mothermonkNo ratings yet
- Basics of StatisticsDocument16 pagesBasics of StatisticsSolaiman Sikder 2125149690No ratings yet
- STAT100 Fall19 Test 2 ANSWERS Practice Problems PDFDocument23 pagesSTAT100 Fall19 Test 2 ANSWERS Practice Problems PDFabutiNo ratings yet
- ErrorDocument13 pagesErrorAbdul GaniNo ratings yet
- Session 4-5 Reference: SFM Ch.5Document24 pagesSession 4-5 Reference: SFM Ch.5Vikas YadavNo ratings yet
- Notes ch7Document20 pagesNotes ch7Jeremy RodriquezNo ratings yet
- The Normal DistributionDocument9 pagesThe Normal DistributionDog VenturesNo ratings yet
- F (A) P (X A) : Var (X) 0 If and Only If X Is A Constant Var (X) Var (X+Y) Var (X) + Var (Y) Var (X-Y)Document8 pagesF (A) P (X A) : Var (X) 0 If and Only If X Is A Constant Var (X) Var (X+Y) Var (X) + Var (Y) Var (X-Y)PatriciaNo ratings yet
- 2s03 Session 3 CLT & Normal Dist (Handout)Document51 pages2s03 Session 3 CLT & Normal Dist (Handout)Sabrina RuncoNo ratings yet
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttilieNo ratings yet
- Introduction To Continuous Probability Distributions: Prepared By: Renna MagdalenaDocument46 pagesIntroduction To Continuous Probability Distributions: Prepared By: Renna Magdalenarenna_magdalenaNo ratings yet
- 9.1. Prob - StatsDocument19 pages9.1. Prob - StatsAnkit KabiNo ratings yet
- Normal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringDocument23 pagesNormal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringsajeerNo ratings yet
- Error Analysis - Statistics: - Accuracy and Precision - Individual Measurement UncertaintyDocument33 pagesError Analysis - Statistics: - Accuracy and Precision - Individual Measurement UncertaintyFarras Amany HusnaNo ratings yet
- Normal DistributionDocument29 pagesNormal DistributionSandeepNo ratings yet
- UDEC1203 - Topic 6 Analysis of Experimental DataDocument69 pagesUDEC1203 - Topic 6 Analysis of Experimental DataA/P SUPAYA SHALININo ratings yet
- Eco StatDocument11 pagesEco StatRani GilNo ratings yet
- Binomial and Normal DistributionDocument29 pagesBinomial and Normal DistributionarunpandiyanNo ratings yet
- Chapter6 StatsDocument4 pagesChapter6 StatsPoonam NaiduNo ratings yet
- Normal DistributionDocument22 pagesNormal Distributionaamirali31No ratings yet
- Module 2 in IStat 1 Probability DistributionDocument6 pagesModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeNo ratings yet
- DOM105 Session 3Document17 pagesDOM105 Session 3Tanish GandhiNo ratings yet
- Basic Concepts of Inference: Corresponds To Chapter 6 of Tamhane and DunlopDocument40 pagesBasic Concepts of Inference: Corresponds To Chapter 6 of Tamhane and Dunlopakirank1No ratings yet
- Discrete Probability DistributionsDocument53 pagesDiscrete Probability DistributionsIra MunirahNo ratings yet
- Statistic and ProbabilityDocument15 pagesStatistic and ProbabilityFerly TaburadaNo ratings yet
- MAE 300 TextbookDocument95 pagesMAE 300 Textbookmgerges15No ratings yet
- AP Stats Project 15Document3 pagesAP Stats Project 15S.WaqquasNo ratings yet
- Hypothesis Testing With One Sample: Larson & Farber, Elementary Statistics: Picturing The World, 3e 3Document23 pagesHypothesis Testing With One Sample: Larson & Farber, Elementary Statistics: Picturing The World, 3e 3S.WaqquasNo ratings yet
- Lfstat3e PPT 08Document15 pagesLfstat3e PPT 08S.WaqquasNo ratings yet
- Exercises: Department of Statistics Ume A UniversityDocument6 pagesExercises: Department of Statistics Ume A UniversityS.WaqquasNo ratings yet
- Exercises: Department of Statistics Ume A UniversityDocument6 pagesExercises: Department of Statistics Ume A UniversityS.WaqquasNo ratings yet
- Lecture 1Document62 pagesLecture 1S.WaqquasNo ratings yet
- Mathematics & Statistics: Lecture 2: Probability and Discrete Random VariablesDocument53 pagesMathematics & Statistics: Lecture 2: Probability and Discrete Random VariablesS.WaqquasNo ratings yet
- Statistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010Document20 pagesStatistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010S.WaqquasNo ratings yet
- Exercises: Department of Statistics Ume A UniversityDocument6 pagesExercises: Department of Statistics Ume A UniversityS.WaqquasNo ratings yet
- Exercises: Department of Statistics Ume A UniversityDocument6 pagesExercises: Department of Statistics Ume A UniversityS.WaqquasNo ratings yet
- Exercises: Department of Statistics Ume A UniversityDocument6 pagesExercises: Department of Statistics Ume A UniversityS.WaqquasNo ratings yet
- Mechanics For Advanced Level PhysicsDocument486 pagesMechanics For Advanced Level PhysicsHubbak Khan90% (20)
- Revisionguide - StatsDocument89 pagesRevisionguide - StatsS.WaqquasNo ratings yet
- LectureDocument12 pagesLectureS.WaqquasNo ratings yet
- Aqa W TRB Pract PapersDocument73 pagesAqa W TRB Pract PapersSarahBukhshNo ratings yet
- Edexcel Statistics 3Document82 pagesEdexcel Statistics 3A4L82% (11)
- Marzano's Compendium: Acknowledging Adherence To Rules and ProceduresDocument28 pagesMarzano's Compendium: Acknowledging Adherence To Rules and ProceduresClaudia VelascoNo ratings yet
- Quarter 1 Science 4 Activity Sheet No. 6Document2 pagesQuarter 1 Science 4 Activity Sheet No. 6karol melendezNo ratings yet
- Math - MAA Problem Series List PDFDocument2 pagesMath - MAA Problem Series List PDFadasdNo ratings yet
- Test Strategy TemplateDocument26 pagesTest Strategy TemplateCola RichmondNo ratings yet
- Lloyds Register Type Approval ST PDFDocument4 pagesLloyds Register Type Approval ST PDFJuan SantosNo ratings yet
- Computer Programming ENEE 101: Lec#17 (Sequences Part 3)Document11 pagesComputer Programming ENEE 101: Lec#17 (Sequences Part 3)Badr WaleedNo ratings yet
- ExamDocument39 pagesExamJessica Nisperos EspenillaNo ratings yet
- International Baccalaureate ProgrammeDocument5 pagesInternational Baccalaureate Programmeapi-280508830No ratings yet
- Advances Chemical Engineering PDFDocument248 pagesAdvances Chemical Engineering PDFDaiane SantanaNo ratings yet
- WHP English10 1ST QDocument8 pagesWHP English10 1ST QXhiemay Datulayta CalaqueNo ratings yet
- Radcliffe Brown - Evans-PritchardDocument2 pagesRadcliffe Brown - Evans-PritchardAnonymous iHg3ImRaXDNo ratings yet
- ERPDocument9 pagesERPWindadahri PuslitkaretNo ratings yet
- Cutting, Coring and Patching - MSTDocument3 pagesCutting, Coring and Patching - MSTwafikmh4No ratings yet
- General Biology 2 Midterms GRASPSDocument2 pagesGeneral Biology 2 Midterms GRASPSAlbert RoseteNo ratings yet
- Tle 6 Mam Melba (Victoria)Document2 pagesTle 6 Mam Melba (Victoria)Precious IdiosoloNo ratings yet
- H. P. Lovecraft: Trends in ScholarshipDocument18 pagesH. P. Lovecraft: Trends in ScholarshipfernandoNo ratings yet
- Application Letter.Document2 pagesApplication Letter.RinzuNo ratings yet
- (1997) Process Capability Analysis For Non-Normal Relay Test DataDocument8 pages(1997) Process Capability Analysis For Non-Normal Relay Test DataNELSONHUGONo ratings yet
- Linux CommandsDocument6 pagesLinux Commandsajha_264415No ratings yet
- Calculation of HLB ValueDocument8 pagesCalculation of HLB ValueShrutiNo ratings yet
- Leopold, L. T. 1968 Hydrology For Urban Planning - A Guide Book On TheDocument26 pagesLeopold, L. T. 1968 Hydrology For Urban Planning - A Guide Book On TheFiguraDesfiguraNo ratings yet
- TEACHeXCELS Required ReadingsDocument69 pagesTEACHeXCELS Required ReadingsJessica MarieNo ratings yet
- Kimia Percubaan SPM 2009 Kertas 1, 2, 3 MRSMDocument68 pagesKimia Percubaan SPM 2009 Kertas 1, 2, 3 MRSMCarolyn Chang Boon ChuiNo ratings yet
- Educ 430 - Assignment 4 - Theory To Practice PaperDocument8 pagesEduc 430 - Assignment 4 - Theory To Practice Paperapi-483914233No ratings yet
- Dukungan Suami Terhadap Pemberian Asi Eksklusif PaDocument11 pagesDukungan Suami Terhadap Pemberian Asi Eksklusif PayolandaNo ratings yet
- Maths InterviewDocument6 pagesMaths InterviewKeamogetse BoitshwareloNo ratings yet
- NIOS Configuration Class: Course SummaryDocument2 pagesNIOS Configuration Class: Course SummaryforeverbikasNo ratings yet
- Raj Yoga ReportDocument17 pagesRaj Yoga ReportSweaty Sunny50% (2)
- Cesare Della RivieraDocument3 pagesCesare Della RivieraCarlos Carlos AgueroNo ratings yet
- Identification of The Challenges 2. Analysis 3. Possible Solutions 4. Final RecommendationDocument10 pagesIdentification of The Challenges 2. Analysis 3. Possible Solutions 4. Final RecommendationAvinash VenkatNo ratings yet