You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Audit and Assurance June 2011 Marks PlanDocument15 pagesAudit and Assurance June 2011 Marks Planjakariauzzal100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- 2-Overview of Data Mining ProcessDocument27 pages2-Overview of Data Mining ProcessJason KristiantoNo ratings yet
- Lecture 01Document29 pagesLecture 01Jason KristiantoNo ratings yet
- Accounting: Paper 0452/01 Multiple ChoiceDocument13 pagesAccounting: Paper 0452/01 Multiple ChoiceJason KristiantoNo ratings yet
- Ps 1Document3 pagesPs 1Jason KristiantoNo ratings yet
- Minor BDTDocument2 pagesMinor BDTJason KristiantoNo ratings yet
- Libor OIS SpreadDocument2 pagesLibor OIS SpreadHui LinNo ratings yet
- IsDocument2 pagesIsJason KristiantoNo ratings yet
- Persepolis Brings A Particular Graphic Style To The AutobiographicalDocument3 pagesPersepolis Brings A Particular Graphic Style To The AutobiographicalJason KristiantoNo ratings yet
- Paper Line (A4)Document4 pagesPaper Line (A4)Jason KristiantoNo ratings yet
- Naamloosdocument PDFDocument1 pageNaamloosdocument PDFJason KristiantoNo ratings yet
- Computer Science SL P1Document8 pagesComputer Science SL P1Jason KristiantoNo ratings yet
- ECON 2113 SyllabusDocument6 pagesECON 2113 SyllabusJason KristiantoNo ratings yet
- IndividualFinalProject 201718springDocument3 pagesIndividualFinalProject 201718springJason KristiantoNo ratings yet
- IB Business & Management Internal Assessment HL Guide Book: and Summer AssignmentDocument18 pagesIB Business & Management Internal Assessment HL Guide Book: and Summer AssignmentShivani AggarwalNo ratings yet
- Business and Management HL P1Document7 pagesBusiness and Management HL P1Jason KristiantoNo ratings yet
- R TagoreDocument2 pagesR TagoreJason KristiantoNo ratings yet
- TOK Essay (9 of 10)Document8 pagesTOK Essay (9 of 10)Jason Kristianto100% (1)
- Business & Organisation SL P2Document9 pagesBusiness & Organisation SL P2Jason KristiantoNo ratings yet
- Computer Science SL P1 ADocument6 pagesComputer Science SL P1 AJason KristiantoNo ratings yet
- Dossier OverviewDocument32 pagesDossier OverviewJason KristiantoNo ratings yet
- Be A BeeDocument1 pageBe A BeeJason KristiantoNo ratings yet
- The Book ThiefDocument1 pageThe Book ThiefJason KristiantoNo ratings yet
- TOK Essay (9 of 10)Document8 pagesTOK Essay (9 of 10)Jason Kristianto100% (1)
- Flash Card MdrnaDocument1 pageFlash Card MdrnaJason KristiantoNo ratings yet
- GFWLIVESetup Log VerboseDocument3 pagesGFWLIVESetup Log Verboseanake7777No ratings yet
- SAP FICO NotesDocument39 pagesSAP FICO NotesShivaniNo ratings yet
- Industry AnalysisDocument15 pagesIndustry Analysisarchanabaskota026No ratings yet
- Bse Cancellation FormatDocument11 pagesBse Cancellation FormatcsisixerNo ratings yet
- Answers To Sample Questions For FinalDocument8 pagesAnswers To Sample Questions For Finalvivek1119No ratings yet
- Dictionary of Business PDFDocument481 pagesDictionary of Business PDFsdonen100% (1)
- Simple Revocable Transfer On Death (Tod) DeedDocument4 pagesSimple Revocable Transfer On Death (Tod) DeedJohn LessardNo ratings yet
- Kra KpiDocument6 pagesKra Kpinishitpatel2783No ratings yet
- VKCDocument8 pagesVKCVaishnav Chandran k0% (1)
- Free Cash Flow To Equity Valuation ModelDocument8 pagesFree Cash Flow To Equity Valuation ModelVinNo ratings yet
- Book ReviewDocument5 pagesBook ReviewsivainamduguNo ratings yet
- Sci4 TG U1Document102 pagesSci4 TG U1Guia Marie Diaz BriginoNo ratings yet
- Organic Food Industry GuideDocument5 pagesOrganic Food Industry GuidekyongngNo ratings yet
- Entrepreneurship Challenges & Way ForwardDocument17 pagesEntrepreneurship Challenges & Way ForwardDr Pranjal Kumar PhukanNo ratings yet
- Bank of America v. CA G.R. No. 103092Document6 pagesBank of America v. CA G.R. No. 103092Jopan SJNo ratings yet
- Ici India Limited: Buy Back of SharesDocument11 pagesIci India Limited: Buy Back of SharesyatinNo ratings yet
- Transformational Leadership Case StudyDocument17 pagesTransformational Leadership Case StudyUrvashi ThapaNo ratings yet
- RFX RequestForProcurementDocument3 pagesRFX RequestForProcurementJames SmithNo ratings yet
- Intp 080318Document3 pagesIntp 080318Cristiano DonzaghiNo ratings yet
- Raf 03 2013 0029Document23 pagesRaf 03 2013 0029vallenciaNo ratings yet
- Rencana Bisnis Art Box Creative and Coworking SpaceDocument2 pagesRencana Bisnis Art Box Creative and Coworking SpacesupadiNo ratings yet
- List Journal Int Handelsblattliste Journals 2015Document50 pagesList Journal Int Handelsblattliste Journals 2015Ferry PrasetyiaNo ratings yet
- Kotak Mahindra Life Insurance Company LTD Lta Claim FormDocument2 pagesKotak Mahindra Life Insurance Company LTD Lta Claim FormCricket KheloNo ratings yet
- Concept Paper On GD & PIDocument9 pagesConcept Paper On GD & PIjigishhaNo ratings yet
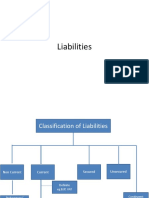
- LiabilitiesDocument21 pagesLiabilitiesdharmendra kumarNo ratings yet
- Modular Full Height Partition - Modular Workstation Manufacturers in DelhiDocument40 pagesModular Full Height Partition - Modular Workstation Manufacturers in DelhikrishnahometextilesNo ratings yet
- Joint VentureDocument6 pagesJoint VentureKJKSZPJ LXGIWYLNo ratings yet
- Centerline-SMED Integration For Machine Changeovers Improvement in Food IndustryDocument16 pagesCenterline-SMED Integration For Machine Changeovers Improvement in Food IndustryDaniel Meza RivasNo ratings yet
- Step 3.4 Partnerships and Partnership Management: Resources For Implementing The WWF Project & Programme StandardsDocument19 pagesStep 3.4 Partnerships and Partnership Management: Resources For Implementing The WWF Project & Programme StandardsShanonraj KhadkaNo ratings yet
- Oracle Cloud Fusion Tax 12092016 V1.0Document44 pagesOracle Cloud Fusion Tax 12092016 V1.0prasadv19806273100% (1)