You might also like
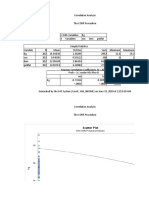
- CorrelationDocument6 pagesCorrelationEveryday LevineNo ratings yet
- DataDocument1 pageDataEveryday LevineNo ratings yet
- DataDocument1 pageDataEveryday LevineNo ratings yet
- Libname Orionx Pcfiles PathDocument1 pageLibname Orionx Pcfiles PathEveryday LevineNo ratings yet
- Scaling, Reliability & ValidityDocument88 pagesScaling, Reliability & ValidityEveryday LevineNo ratings yet
- SAS Visualization and Reporting of Employee and Flight DataDocument5 pagesSAS Visualization and Reporting of Employee and Flight DataEveryday LevineNo ratings yet
- Individual Assignment Set 1Document2 pagesIndividual Assignment Set 1Everyday LevineNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Undimensional: Service Quality & Brand Loyalty of Kolachi & KababjeesDocument15 pagesUndimensional: Service Quality & Brand Loyalty of Kolachi & KababjeesHurain ShaikhNo ratings yet
- Ch. 2 Probability (FILEminimizer)Document81 pagesCh. 2 Probability (FILEminimizer)Sefer TuncaNo ratings yet
- PPT OME Lec 3 Lesson 1 ForecastingDocument33 pagesPPT OME Lec 3 Lesson 1 ForecastingZkdlin KimNo ratings yet
- Hypothesis Testing Steps and Types of ErrorsDocument116 pagesHypothesis Testing Steps and Types of ErrorsavijeetboparaiNo ratings yet
- SPSS T-Test Analyze Gender DifferencesDocument24 pagesSPSS T-Test Analyze Gender DifferencesRahman SurkhyNo ratings yet
- Mario R. Melchiori CPA Universidad Nacional Del Litoral Santa Fe - ArgentinaDocument8 pagesMario R. Melchiori CPA Universidad Nacional Del Litoral Santa Fe - ArgentinashrutigarodiaNo ratings yet
- Tree Example - Hitters - Jupyter NotebookDocument10 pagesTree Example - Hitters - Jupyter Notebookeleni giannopoulouNo ratings yet
- Chapter 3-1 ExerciseDocument3 pagesChapter 3-1 ExerciseAnson LoNo ratings yet
- Seminar2 Student Copy SUSSDocument6 pagesSeminar2 Student Copy SUSSmelodyNo ratings yet
- Mplus Version 7 - User's Guide 2012muthen28Document856 pagesMplus Version 7 - User's Guide 2012muthen28kienneuNo ratings yet
- Fitch - Liquidity Score MethodologyDocument1 pageFitch - Liquidity Score MethodologyJean-Baptiste CarelusNo ratings yet
- SPSS AssignmentDocument3 pagesSPSS AssignmentKwin KonicNo ratings yet
- Design of Experiments - Individual Final ReportDocument223 pagesDesign of Experiments - Individual Final ReportRafael OrtizNo ratings yet
- Agricultural Sector FDI and Economic Growth in Saarc CountriesDocument7 pagesAgricultural Sector FDI and Economic Growth in Saarc CountriesJameel KassamNo ratings yet
- Assignment 6Document2 pagesAssignment 6kyle cheungNo ratings yet
- 14 PoissonExponentialDocument14 pages14 PoissonExponentialrasha assafNo ratings yet
- Unit III Probability B.tech 2nd SemDocument30 pagesUnit III Probability B.tech 2nd Sempure handsNo ratings yet
- Chapter 10 One-Sample Tests of HypothesisDocument36 pagesChapter 10 One-Sample Tests of Hypothesiswindyuri100% (2)
- Tugas Statistik Fikry Chairanda Variabel X Dan yDocument8 pagesTugas Statistik Fikry Chairanda Variabel X Dan yFikryNo ratings yet
- Chapter 3 (PR)Document29 pagesChapter 3 (PR)Srikanta KarthikNo ratings yet
- Maximum Likelihood and Bayesian Parameter Estimation: Chapter 3, DHSDocument35 pagesMaximum Likelihood and Bayesian Parameter Estimation: Chapter 3, DHSNikhil GuptaNo ratings yet
- Regression PacketDocument27 pagesRegression PacketgedleNo ratings yet
- BBA 122 Notes On Estimation and Confidence IntervalsDocument34 pagesBBA 122 Notes On Estimation and Confidence IntervalsMoses CholNo ratings yet
- Probability and Statistics Sheet: A A S, T & M TDocument57 pagesProbability and Statistics Sheet: A A S, T & M TjncxsjNo ratings yet
- Learning Worksheet No. In: 10 Statistics and ProbabilityDocument5 pagesLearning Worksheet No. In: 10 Statistics and ProbabilityElizabeth Micah SwiftNo ratings yet
- Presentation 6Document43 pagesPresentation 6Swaroop Ranjan BagharNo ratings yet
- Demand EstimationDocument27 pagesDemand EstimationAnonymous FmpblcLw0No ratings yet
- SOA Exam P SyllabusDocument3 pagesSOA Exam P SyllabusMuneer DhamaniNo ratings yet
- Textbook Distribution-TablesDocument1 pageTextbook Distribution-TableskakkrasNo ratings yet
- Econometrics I: TA Session 5: Giovanna UbidaDocument20 pagesEconometrics I: TA Session 5: Giovanna UbidaALAN BUENONo ratings yet