You might also like
- Skills in Mathematics Integral Calculus For JEE Main and Advanced 2022Document319 pagesSkills in Mathematics Integral Calculus For JEE Main and Advanced 2022Harshil Nagwani100% (3)
- PMP Exam Cram Test BankDocument260 pagesPMP Exam Cram Test Bankmuro562001100% (2)
- VE2Document90 pagesVE2Avinash M. KatkarNo ratings yet
- QFD: A Tool of Product Design and Development: Dr. Pravin KumarDocument28 pagesQFD: A Tool of Product Design and Development: Dr. Pravin KumarPravin KumarNo ratings yet
- Post Completion Sustainability of ADB-Assisted ProjectsDocument103 pagesPost Completion Sustainability of ADB-Assisted ProjectsIndependent Evaluation at Asian Development BankNo ratings yet
- Decision Making in Finance For Production LinesDocument26 pagesDecision Making in Finance For Production LinesRahul NakheNo ratings yet
- Establishing+a+Lean+Six+Sigma+Program+in+Higher+Education+-+Author ManuscriptDocument18 pagesEstablishing+a+Lean+Six+Sigma+Program+in+Higher+Education+-+Author Manuscriptimran24No ratings yet
- Waste Reduction by Lean Construction - Office Building Case StudyDocument11 pagesWaste Reduction by Lean Construction - Office Building Case StudyLucero Bereche BNo ratings yet
- Case StudyDocument28 pagesCase StudyPrabhat YadavNo ratings yet
- Full Download Ebook PDF Applied Calculus For The Managerial Life and Social Sciences 10th Edition PDFDocument41 pagesFull Download Ebook PDF Applied Calculus For The Managerial Life and Social Sciences 10th Edition PDFapril.cash242100% (34)
- Lean Six Sigma Mid-Term Ass Final 1.0Document21 pagesLean Six Sigma Mid-Term Ass Final 1.0era nominNo ratings yet
- Productivity Improvement in Construction Site. Modification To ProposalDocument8 pagesProductivity Improvement in Construction Site. Modification To ProposalAbdallaNo ratings yet
- Group Theory For Physicists - Christoph LudelingDocument123 pagesGroup Theory For Physicists - Christoph LudelingteolsukNo ratings yet
- Productivity and Reliability-Based Maintenance Management, Second EditionFrom EverandProductivity and Reliability-Based Maintenance Management, Second EditionNo ratings yet
- Chapter 11 NotesDocument7 pagesChapter 11 NotesGloria HuNo ratings yet
- Ch-8 (Business Process Reengineering)Document22 pagesCh-8 (Business Process Reengineering)Shrutit21No ratings yet
- Case Study - Lucas TVSDocument19 pagesCase Study - Lucas TVSMangesh GhandatNo ratings yet
- KAIZEN: A Case Study in Small Scale OrganizationsDocument4 pagesKAIZEN: A Case Study in Small Scale OrganizationsijsretNo ratings yet
- Exam SolutionDocument11 pagesExam SolutionAamir Ahmed Ali SalihNo ratings yet
- Value Stream Mapping: Literature Review and Implications For Indian IndustryDocument11 pagesValue Stream Mapping: Literature Review and Implications For Indian IndustryMohamed SafeerNo ratings yet
- Design For Supply ChainDocument15 pagesDesign For Supply ChainSuryakant GideNo ratings yet
- Agile ManufacturingDocument5 pagesAgile ManufacturingVarunNo ratings yet
- Ass 2 Lean Mayflower Engineering B 22 - 23 (2) - TaggedDocument12 pagesAss 2 Lean Mayflower Engineering B 22 - 23 (2) - TaggedRahib AliNo ratings yet
- Lean ManufacturingDocument11 pagesLean ManufacturingraisehellNo ratings yet
- Bhasin - 2012 - Performance of Lean in Large OrganisationsDocument9 pagesBhasin - 2012 - Performance of Lean in Large OrganisationsDragan DragičevićNo ratings yet
- Design For Sustainability - A Practical ApproachDocument128 pagesDesign For Sustainability - A Practical Approachkayyappan1957No ratings yet
- Assignments-Mba Sem-Iii: Subject Code: QM0002Document17 pagesAssignments-Mba Sem-Iii: Subject Code: QM0002Mithesh KumarNo ratings yet
- V330 Turnover and Inspection Document For PHNNNNN: Close CodeDocument13 pagesV330 Turnover and Inspection Document For PHNNNNN: Close CodeAnna AntonenkoNo ratings yet
- Six Sigma in Indian IT SectorDocument6 pagesSix Sigma in Indian IT SectornoushadNo ratings yet
- Total Quality Management: PCTI Limited - A Unique Name For Quality EducationDocument296 pagesTotal Quality Management: PCTI Limited - A Unique Name For Quality Educationrajesh_vuNo ratings yet
- Assignment 5Document8 pagesAssignment 5sharmilaNo ratings yet
- Babalola2019 PDFDocument33 pagesBabalola2019 PDFMatt SlowikowskiNo ratings yet
- Microsoft Word - Quality Function DeploymentDocument9 pagesMicrosoft Word - Quality Function DeploymentMuhammad Tahir NawazNo ratings yet
- Chap07 Conclusions and Future ScopeDocument3 pagesChap07 Conclusions and Future ScopeNavneet Mishra100% (1)
- DMAICDocument11 pagesDMAICGermán Huarte ZubiateNo ratings yet
- Manufacturing Process DesignDocument45 pagesManufacturing Process DesignAnuj Chanda0% (1)
- Chapter 4Document131 pagesChapter 4Ankita HandaNo ratings yet
- Service Innovation and DesignDocument23 pagesService Innovation and DesignMahfuzur Rahman100% (1)
- Wisner Case 13Document8 pagesWisner Case 13Nabaneeta SahanaNo ratings yet
- Case Tata TocDocument6 pagesCase Tata TocPrasenjit DeyNo ratings yet
- PPTDocument33 pagesPPTMitPatel100% (1)
- A Study On Green Supply Chain Management Practices Among Large Global CorporationsDocument13 pagesA Study On Green Supply Chain Management Practices Among Large Global Corporationstarda76No ratings yet
- Research Methodology Hypothesis On Kia SeltosDocument2 pagesResearch Methodology Hypothesis On Kia SeltosAjitha P.NNo ratings yet
- World Quality Day PosterDocument1 pageWorld Quality Day PosterGenGyan Global Business Solutions Pvt LtdNo ratings yet
- Strategic Dimensions of Maintenance Management: Albert H.C. TsangDocument33 pagesStrategic Dimensions of Maintenance Management: Albert H.C. TsanghuseNo ratings yet
- Minitab ExercisesDocument17 pagesMinitab ExercisessadiqusNo ratings yet
- Value Stream Mapping Process - Supply Chain ManagementDocument21 pagesValue Stream Mapping Process - Supply Chain ManagementMANTECH Publications100% (1)
- A STUDY ON IMPACT OF SIX SIGMA PRACTICES AT Harita Tvs Technologies LTDDocument7 pagesA STUDY ON IMPACT OF SIX SIGMA PRACTICES AT Harita Tvs Technologies LTDAnonymous WtjVcZCgNo ratings yet
- Assignment 5 - Capacity PlanningDocument1 pageAssignment 5 - Capacity Planningamr onsyNo ratings yet
- Project Quality ManagementDocument10 pagesProject Quality ManagementkakkarsunilNo ratings yet
- Cellular LayoutDocument18 pagesCellular LayoutShreeshaila P VijayapurNo ratings yet
- Zero DefectDocument16 pagesZero DefectStephen Lim Kean Jin100% (1)
- MUDA (7 Waste)Document3 pagesMUDA (7 Waste)Shamshair Ali100% (1)
- Operations Research For Sustainability PDFDocument21 pagesOperations Research For Sustainability PDFWilmer MontealegreNo ratings yet
- Value EngineeringDocument10 pagesValue EngineeringSudeep D'SouzaNo ratings yet
- An ABC AnalysisDocument6 pagesAn ABC AnalysisDavisTranNo ratings yet
- Chapter 1. Introduction: 1.1. BackgroundDocument92 pagesChapter 1. Introduction: 1.1. BackgroundSanjay KmrNo ratings yet
- Project Identification and SelectionDocument9 pagesProject Identification and Selectionluckyjp100% (1)
- Pull System, JITDocument12 pagesPull System, JIThendmeNo ratings yet
- Design For Quality - Achieving 0 PPM With SigmundWorks From EGS IndiaDocument32 pagesDesign For Quality - Achieving 0 PPM With SigmundWorks From EGS IndiaNatarajan RamamoorthyNo ratings yet
- An Approach For Condition Monitoring of Rolling Stock Sub-SystemsDocument12 pagesAn Approach For Condition Monitoring of Rolling Stock Sub-SystemsDamigo DiegoNo ratings yet
- Project Quality Management A Complete Guide - 2019 EditionFrom EverandProject Quality Management A Complete Guide - 2019 EditionNo ratings yet
- Engineering Solutions 11.0 User GuideDocument2,056 pagesEngineering Solutions 11.0 User GuideNeimar Soares Silva100% (1)
- 2 Bit Full AdderDocument21 pages2 Bit Full AdderSilvestre VásquezNo ratings yet
- Exercio 3.9 SakuraiDocument7 pagesExercio 3.9 SakuraiManoel Junior Junior JapaNo ratings yet
- AlgebraDocument2 pagesAlgebraNumber1tutorNo ratings yet
- Gamma and Beta Function - Spring 21-22Document23 pagesGamma and Beta Function - Spring 21-22Jamiul HasanNo ratings yet
- Torreti - Bachelard e FenomenotecnicaDocument19 pagesTorreti - Bachelard e FenomenotecnicaGabriel Kafure da RochaNo ratings yet
- Algebraic Geometry - Van Der WaerdenDocument251 pagesAlgebraic Geometry - Van Der Waerdenandrei129No ratings yet
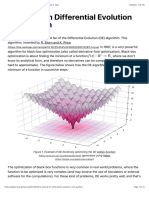
- A Tutorial On Differential Evolution With Python - Pablo R. MierDocument21 pagesA Tutorial On Differential Evolution With Python - Pablo R. MierNeel GhoshNo ratings yet
- Reometro ICAR-5000Document23 pagesReometro ICAR-5000Jhon CardenasNo ratings yet
- Generalized Confusion Matrix For Multiple ClassesDocument3 pagesGeneralized Confusion Matrix For Multiple ClassesFira SukmanisaNo ratings yet
- Lebanese International University: CSCI 250 - Introduction To Programming - TEST-2: Student Name: Student IDDocument5 pagesLebanese International University: CSCI 250 - Introduction To Programming - TEST-2: Student Name: Student IDralf tamerNo ratings yet
- Quiz02: Top of FormDocument4 pagesQuiz02: Top of FormJay WongNo ratings yet
- Finding The Raw ScoreDocument33 pagesFinding The Raw ScoreRaven Jade MasapaNo ratings yet
- Image Processing-Ch4 - Part 1Document63 pagesImage Processing-Ch4 - Part 1saifNo ratings yet
- Discrete Maths 103 124Document22 pagesDiscrete Maths 103 124Bamdeb DeyNo ratings yet
- ENME 599 Final Formula SheetDocument2 pagesENME 599 Final Formula SheetNormanNo ratings yet
- CMPT 354 Assignment 3Document7 pagesCMPT 354 Assignment 3rakyn21No ratings yet
- Rudita Cahya Nadila - CH 4Document8 pagesRudita Cahya Nadila - CH 4Giovanni HebertNo ratings yet
- Fractions, Decimals, Percents: Learners Module in Business MathematicsDocument29 pagesFractions, Decimals, Percents: Learners Module in Business MathematicsJamaica C. AquinoNo ratings yet
- Grade 10 Term 3 TopicsDocument10 pagesGrade 10 Term 3 TopicsOwamiirh RsaNo ratings yet
- Fuzzy Neutrosophic SubgroupsDocument12 pagesFuzzy Neutrosophic SubgroupsMia AmaliaNo ratings yet
- Xtract V 3 0 8Document72 pagesXtract V 3 0 8Don Ing Marcos LeónNo ratings yet
- Chetan PrakashDocument48 pagesChetan PrakashpatrickNo ratings yet
- Latest Syllabus PDFDocument74 pagesLatest Syllabus PDFsmit shahNo ratings yet
- CodeVisionAVR Revision History 20051208Document20 pagesCodeVisionAVR Revision History 20051208letanbaospkt06No ratings yet
- AkosidogiewowoDocument20 pagesAkosidogiewowoGerald CerenoNo ratings yet